1.どんなもの
行動認識のために人間の骨格情報からLSTMとCNNを組み合わせた方法を提案
2.先行研究と比べてどこがすごいの?
CNNベースでは,どうしても3D情報を2D情報に変換する際に時間的な情報を失うことは避けられない
RNNベースでは,関節の相対的関係を探索することで空間的特徴が元の関節の座標位置より良い結果をもたらしたが,複数のリッチな情報を連結して入力しても単一の情報を入力するのと認識率に向上が見られない
本手法は,CNNとLSTMの融合により,良い結果をもたらすものである
3.技術や手法の肝はどこにあるか?
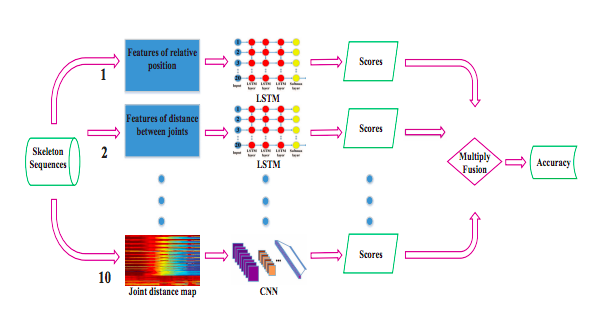
3つのLSTMモデルと7つのCNNモデルからなるニューラルネットワーク
スケルトンシーケンスに様々な手法を適用することで,空間的,時間的な特徴を得る
LSTMでは時間に依存しない空間情報を持つ3つの特徴を得る
CNNはAlexNetを用い,fine-tuningとしてILSVRC-2012の事前学習を使用
スケルトンシーケンスが入力されると,3つの特徴ベクトルと7つのテクスチャマップが生成され,それぞれの異なるNNで学習が行われる.
10個のニューラルネットワークのスコアベクトルが融合,結果ベクトルの最大スコアが,テストシーケンスが認識されたクラスである確率として割り当てられる.
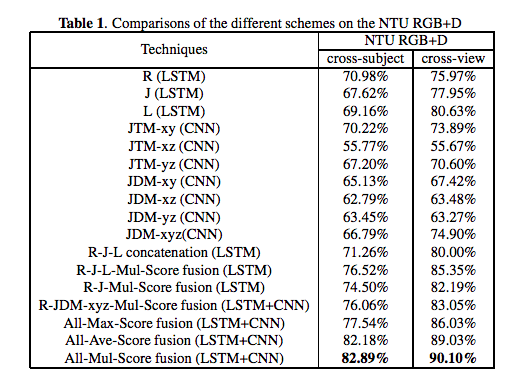
融合方法として,10個のニューラルネットワークから出力されたスコアベクトルは、要素ごとに最大化,平均化,乗算の3つ方法で評価
4.どうやって有効だと検証した?
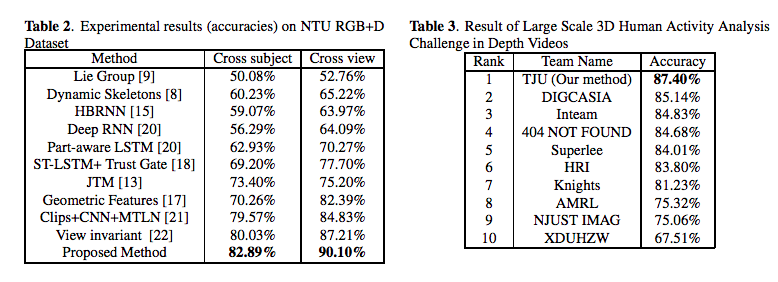
NTU RGB+Dデータセットで評価
実験は,種類のスコア融合法の有効性,3種類の特徴におけるLSTMモデルのスコアリング,およびCNNモデルとLSTMモデルとの融合スコアを評価するために行った.