はじめに
TeachableMachineで作成した画像分類のモデルをKerasの形式で出力すると、h5ファイルのサイズが2.4kBしかありません。TeachableMachineでは画像分類のモデルをMobileNetを使って転移学習により作成しています。
前回の記事では、ファイルサイズが小さい学習モデルを得ることを目的として、MobilenetV2を使った転移学習のプログラム(TrainValidation_MobileNetV2_model.py)を作成して
にアップしました。このプログラムでは、画像分類のモデルをh5ファイルで2.1kBのサイズで出力します。ファイルサイズで言えば、TeachableMachineと同程度のモデルが得られています。
今回はそのプログラムを簡単に解説します。素人作成のプログラムのため改良の余地が多々あり不十分な解説になりますが、ご参考になれば幸いです。
プログラムの解説
はじめに、プログラムで用いる関数をインポートします。
import glob
import os
import numpy as np
from keras.applications import MobileNetV2
from keras.callbacks import CSVLogger, EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.layers import Dense, GlobalAveragePooling2D
from keras.models import Model
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
from PIL import Image, ImageOps
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from keras.applications.mobilenet_v2 import preprocess_input
続いて環境設定をします。
- data_pathは画像ファイルが格納してあるフォルダを指定します。このフォルダの下に、分類したい画像の種類ごとにフォルダを作成して画像を格納しておきます。例えば、犬と猫の画像を分類したいときはc:/dataの下にdogとcatなどのフォルダを作成して、それぞれ犬と猫の画像ファイルを格納します。out_put_pathは学習モデルを保存するフォルダを指定します。ここで、data_path、out_put_pathおよび画像を格納するフォルダ名は半角としてください。
- IMAGE_SIZEにはモデルを学習・検証するときの入力画像のサイズを指定します。MobilenetV2モデルの入力画像の最大サイズは224×224なので、プログラムではこの224という値を指定しています。
- BATCH_SIZEには一回の学習で使用する画像の枚数を指定します。データ数が多い場合はこの数値を大きくします。2のべき乗(16、32、64、128)で設定することが多いです。なお、BATCH_SIZEは特に指定しなければ32という値が後述のfit関数の実行時に設定されます。
- NB_EPOCHには最大の学習回数を入力します。このプログラムは学習が進まなくなると、この回数に達する前に学習が終了するようになっています。
- VALID_SIZEは検証用画像の割合です。全体の0.2(20%)を検証用の画像に充てるという意味です。残りの0.8(80%)は学習用画像に充てられます。
data_path = "c:/data/" # 画像フォルダ
output_path = "c:/python/" # h5ファイルなどの出力フォルダ
IMAGE_SIZE = 224
BATCH_SIZE = 16
NB_EPOCH = 100
VALID_SIZE = 0.2
ここではモデルを構築する関数を定義しています。
- imagenetで事前学習済みのMobilenetV2モデルを使って、出力部のみ学習(転移学習)するモデルを構築します。小さいモデルを構築するため、MobilenetV2モデルのbase_modelの定義でalphaというパラメータを設定可能な最小値(0.35)とし、base_modelにはGlobalAveragePooling2D層とDense層のみ加えています。
- さらに、転移学習とするためbase_modelは学習しない設定をした後、コンパイルしてモデルとしています。コンパイルの際に学習率(learning_rate)を設定しますが、ここでは5e-4を初期値に設定しています。
def build_model():
base_model = MobileNetV2(
weights="imagenet",
include_top=False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),
alpha=0.35, # alpha=0.35, 0.50, 0.75, 1.0, 1.3 or 1.4
)
x = base_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(nb_classes, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
# ベースモデル部分は再学習しない(転移学習)
for layer in base_model.layers:
layer.trainable = False
model.compile(
loss="categorical_crossentropy",
optimizer=SGD(learning_rate=5e-4, momentum=0.9),
metrics=["accuracy"],
)
return model
ここでは、ラベルの読み込み・名前順にソート・表示とファイルへの書き出し(ファイル名:labels.txt)をしています。-
labels = os.listdir(data_path)
nb_classes = len(labels) #クラス数の取得
labels.sort()
print(labels)
with open(output_path + "/labels.txt", "w") as o:
for i, label in enumerate(labels):
print(i, label, file=o)
ここでは画像データを読み込んで、モデルに適した形に変換しています。
- Xには画像データ、yにはラベル名が代入されます。
- 上述のbase_modelの定義において画像の入力サイズは224×224と定義しましたが、画像データのサイズは一般に224×224ではありません。このため、画像データはImageOps.fitという関数で正方形にトリミングしてから224×224のサイズに変換した後にXに代入します。
- yに代入されるラベル名はフォルダ名となります。
- Xとyをnumpy形式に変換して、preprocess_inputを使ってXの値を0~255からMobilenetV2に適する-1~+1に正規化しています。preprocess_inputを使わずに
X = X.astype("float32")
の行を
X = X.astype("float32") / 127.0 - 1.0
と変更してもよいです。
なお、後述のImageDataGeneratorの関数において、rescaleという変数を用いれば正規化を定義できます。しかし、rescaleは元の値にrescaleを掛けて正規化(例えば0~255を255で割って0~1に正規化)します。今回は、0~255を-1~1にするため、単純に何かを掛けることでは正規化できないため、ImageDataGeneratorに入れる前にここで正規化しています。
X = []
y = []
for index, name in enumerate(labels):
data_dir = data_path + "/" + name
data_files = glob.glob(data_dir + "/*.*")
for i, data_file in enumerate(data_files):
image = Image.open(data_file)
image = image.convert("RGB")
im = ImageOps.fit(
image,
(IMAGE_SIZE, IMAGE_SIZE),
Image.Resampling.LANCZOS, # Pillow 9.1.0で追加
)
data = np.asarray(im)
X.append(data)
y.append(index)
X = np.array(X)
y = np.array(y)
X = X.astype("float32")
# preprocess_input 前のXの最大値と最小値の表示
print("Xmax and Xmin before preprocess_input")
print(X.max())
print(X.min())
# preprocess_input:画像の前処理(Xの値を0~255からMobilenetV2に適する-1~+1に変更)
x = preprocess_input(X)
# preprocess_input 後のXの最大値と最小値の表示
print("Xmax and Xmin after preprocess_input")
print(X.max())
print(X.min())
学習の準備をします。
- train_test_splitという関数を使って、学習用と検証用のデータを上記で設定した8:2の割合に分割します。- ラベル名(y)をto_categoricalで数値の行列データに変換します。
- 上記で定義したbuild_model()を呼び出してモデルを構築します。
- train_datagenでは学習に用いる画像の水増し条件を設定します。
- ResultFileNameでは出力されるモデルの名前を設定します。
- csv_log(学習経過の保存)、early_stopping(学習の早期終了)、reduce_lr(学習率を減らす)、modelCheckpoint(学習ごとにモデルを保存)の設定については、Kerasのコールバックに詳しく載っています。
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=VALID_SIZE, random_state=1
)
y_train = to_categorical(y_train, nb_classes)
y_valid = to_categorical(y_valid, nb_classes)
# インスタンスの呼び出し
model = build_model()
train_datagen = ImageDataGenerator(
# 水増しのパラメータは、学習データと検証データの正解率をみながら適宜変更する
# width_shift_range=0.2,
# height_shift_range=0.2,
zoom_range=0.2,
#rotation_range=20,
#channel_shift_range=20,
#brightness_range=[0.80, 1.0],
# horizontal_flip=True,
# vertical_flip=True,
)
train_datagen.fit(X_train)
valid_datagen = ImageDataGenerator()
valid_datagen.fit(X_valid)
ResultFileName = output_path + "/" + "model"
# 学習経過の記録
csv_log = CSVLogger(ResultFileName + ".csv")
# モデルの学習が進まなくなったら学習終了
early_stopping = EarlyStopping(monitor="val_loss", patience=5, verbose=1)
# モデルの学習が遅くなってきたら学習率を小さくする
reduce_lr = ReduceLROnPlateau(
monitor="val_loss", factor=0.5, patience=2, verbose=1
)
modelCheckpoint = ModelCheckpoint(
filepath=ResultFileName + ".h5",
monitor="val_loss",
verbose=1,
save_best_only=True,
save_weights_only=False,
mode="min",
period=1,
)
学習・検証します。学習の経過はグラフに出力するためhistoryに保存します。fit関数についてはModelクラスのfitに詳しく載っています。
# モデルの学習
history = model.fit(
train_datagen.flow(X_train, y_train, batch_size=BATCH_SIZE),
epochs=NB_EPOCH,
validation_steps=1,
verbose=1,
validation_data=valid_datagen.flow(X_valid, y_valid),
callbacks=[csv_log, early_stopping, reduce_lr, modelCheckpoint],
)
学習・検証のようす
Epoch 1/100
8/8 [==============================] - ETA: 0s - loss: 1.9848 - accuracy: 0.1583
Epoch 1: val_loss improved from inf to 1.81257, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 5s 354ms/step - loss: 1.9848 - accuracy: 0.1583 - val_loss: 1.8126 - val_accuracy: 0.2333 - lr: 5.0000e-04
Epoch 2/100
8/8 [==============================] - ETA: 0s - loss: 1.5474 - accuracy: 0.3583
Epoch 2: val_loss improved from 1.81257 to 1.44668, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 2s 237ms/step - loss: 1.5474 - accuracy: 0.3583 - val_loss: 1.4467 - val_accuracy: 0.4667 - lr: 5.0000e-04
Epoch 3/100
8/8 [==============================] - ETA: 0s - loss: 1.2275 - accuracy: 0.4833
Epoch 3: val_loss improved from 1.44668 to 1.24463, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 2s 229ms/step - loss: 1.2275 - accuracy: 0.4833 - val_loss: 1.2446 - val_accuracy: 0.4000 - lr: 5.0000e-04
Epoch 4/100
8/8 [==============================] - ETA: 0s - loss: 0.9816 - accuracy: 0.5833
Epoch 4: val_loss improved from 1.24463 to 1.06430, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 2s 237ms/step - loss: 0.9816 - accuracy: 0.5833 - val_loss: 1.0643 - val_accuracy: 0.4333 - lr: 5.0000e-04
Epoch 5/100
8/8 [==============================] - ETA: 0s - loss: 0.8255 - accuracy: 0.7083
Epoch 5: val_loss improved from 1.06430 to 0.95260, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 2s 234ms/step - loss: 0.8255 - accuracy: 0.7083 - val_loss: 0.9526 - val_accuracy: 0.5333 - lr: 5.0000e-04
Epoch 6/100
8/8 [==============================] - ETA: 0s - loss: 0.7457 - accuracy: 0.7917
Epoch 6: val_loss improved from 0.95260 to 0.88827, saving model to c:/python/Metallography\model.h5
8/8 [==============================] - 2s 232ms/step - loss: 0.7457 - accuracy: 0.7917 - val_loss: 0.8883 - val_accuracy: 0.5667 - lr: 5.0000e-04
Epoch 7/100
...
8/8 [==============================] - ETA: 0s - loss: 0.2183 - accuracy: 0.9333
Epoch 41: val_loss did not improve from 0.46072
8/8 [==============================] - 2s 260ms/step - loss: 0.2183 - accuracy: 0.9333 - val_loss: 0.4614 - val_accuracy: 0.9000 - lr: 6.2500e-05
Epoch 41: early stopping
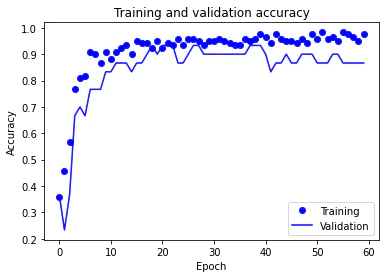
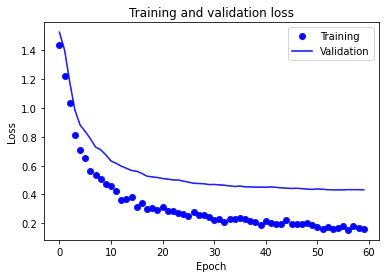
最後に学習結果をグラフで表示します。
# 数値の取得
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(acc))
# plot accuracy
plt.plot(epochs, acc, "bo", label="Training")
plt.plot(epochs, val_acc, "b", label="Validation")
plt.title("Training and validation accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.figure()
# plot loss
plt.plot(epochs, loss, "bo", label="Training")
plt.plot(epochs, val_loss, "b", label="Validation")
plt.title("Training and validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()
結果の出力