背景
ある日,私は機械翻訳に興味を持った.
(英語に苦しむ日本の研究者の声を聞いたからかもしれないし,勉強会の準備に追われていたからかもしれない.)
しかし私は門外漢なので,encoder-decoderモデルの "あの" 図を読むことができなかった.
先日気持ちを掴むことができたので,自分なりに噛み砕いたものを記録・共有するためにこの記事を書いた.
先人の詳細な記事
http://qiita.com/odashi_t/items/a1be7c4964fbea6a116e
RNNの図を翻訳
翻訳までの流れを別視点から描いた.
encoder-decoderモデルによって「彼 は 走る」を「He runs」と翻訳するまでの流れは,以下のようになっている.
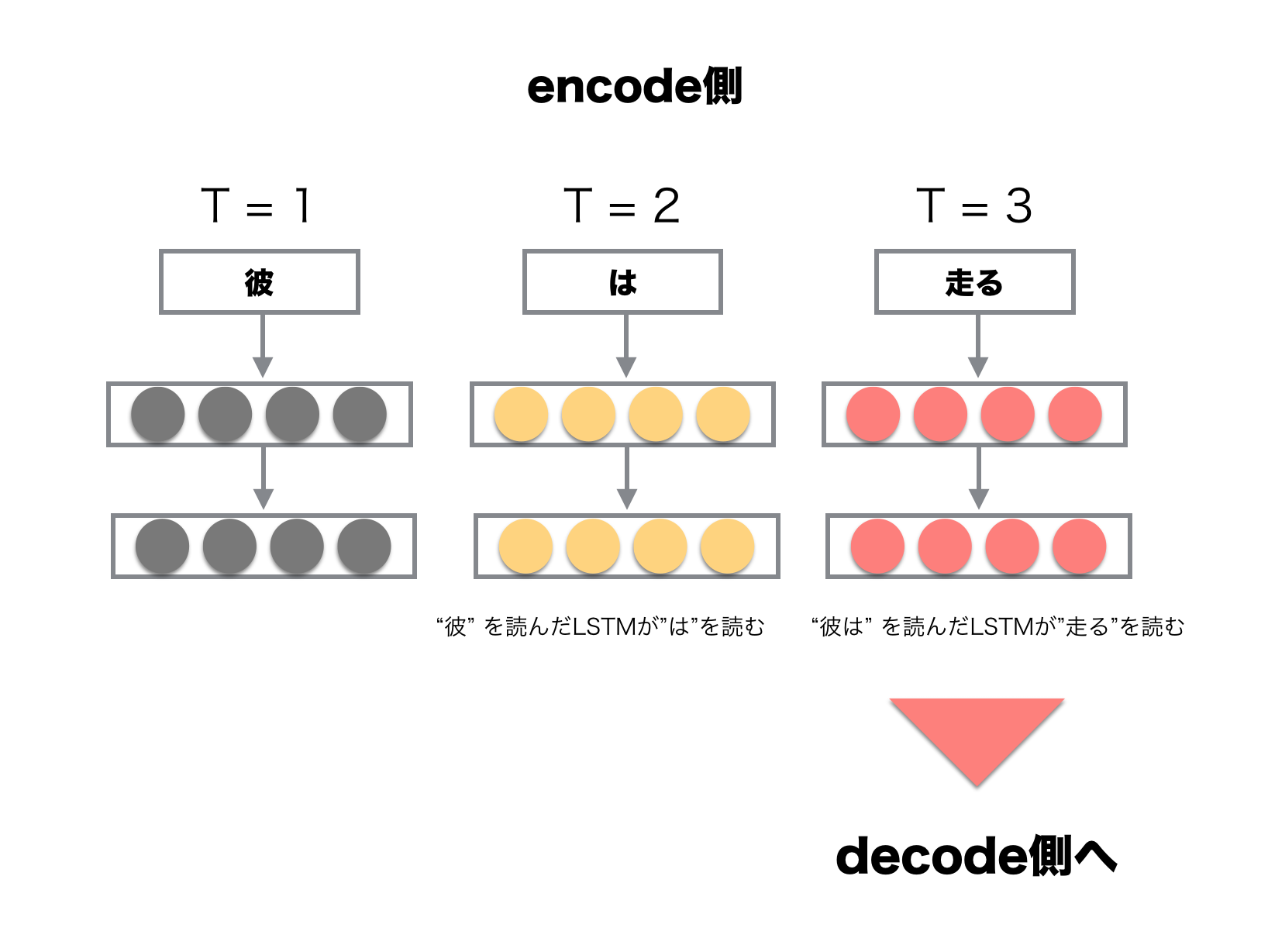
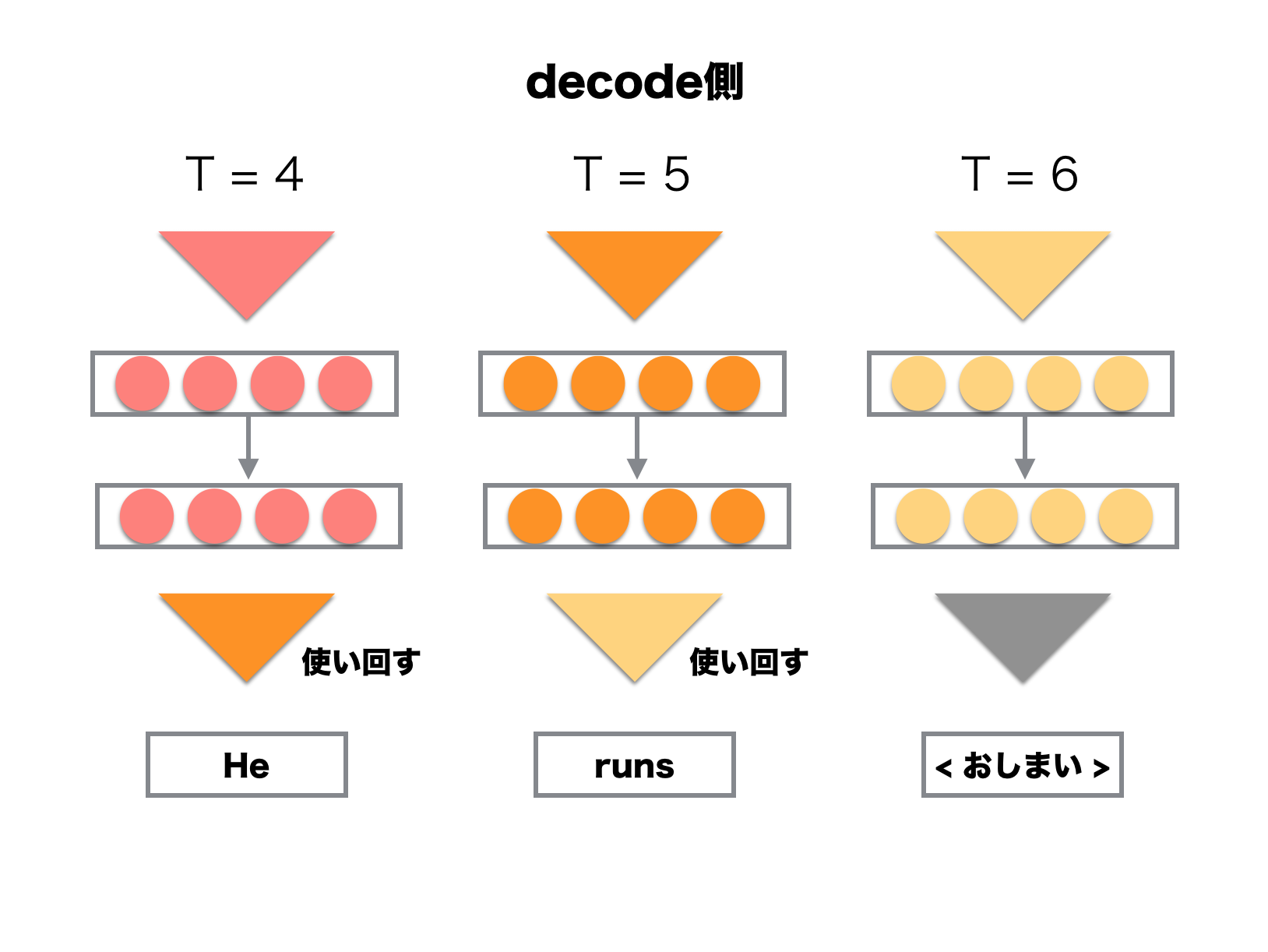
encode側の図において,日本語の登場順序がodashi_tさんの図とは逆になっている.
逆順に入力すると実験的に良い結果が得られているらしいので,実験を行う際はodashi_tさんの例に従うと良さそうだ.
理解できたような気がしたところで,Chainerを用いて実装した.
- TensorFlowのサンプルプログラムには,機械翻訳が含まれているらしい.
- ChainerにもシンプルなSeq2Seqのサンプルがあると良い?
実装
https://github.com/g329/seq2seq/blob/master/seq2seq.py
なるべくencoder-decoderの気持ちが伝わるように書いたつもりだ.
先人の記事を読みながらソースコードを眺めて欲しい.
python seq2seq.py
と実行し,しばらくすると以下のような出力が得られるはずである.
teacher : 黄昏に天使の声響く時,聖なる泉の前にて待つ
-> 5時に 噴水の前で 待ってます
熊本弁から日本語への翻訳の他,英語から日本語など様々応用が効く.
学習の様子を観察していると,あっという間に時間が過ぎてしまうので注意して欲しい.
データが沢山あれば "A Neural Conversational Model"に載っているようなこともできるらしい.夢が広がる.
その他
Seq2Seqは,少しアレンジするだけで様々な面白い動きを見せてくれる.
そのあたりに関しては,LTの準備が終わったあたりにまた書くつもりだ.