初めに
初めての人は、初めまして。
そうでない人は、お久しぶりです。
最近、AIに沼り、NLPを勉強し始めた人です。
そんな、NLP初心者がRasaを使うときに沼ったので、この記事にまとめてみました。
記事を作っている時、うまくいかなかったことが多々ありました。
公式すら敵でした。
なので、うまくいかないことがある可能性が高いです。
記事通り動かなかった場合、 少し調べてから この記事にコメントをください。
できるだけ、対応します。
この記事の対象
- AIに興味がある人
- NLPに興味がある人
- NLPしたいけど、何をしたらいいのかわからない人
- Pythonできるけど、何しようか迷ってる人
環境
ここでは、Python 3.7 or 3.8 (64bit版)が必要です。 【情報源】
インストールしてない人は、ここからインストールしてください。

▼ winでのNeofetchは、これ見て
そもそも:
NLP
自然言語処理(しぜんげんごしょり、英語: natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。「計算言語学」(computational linguistics)との類似もあるが、自然言語処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす事が多い[1]。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な(コンピュータが理解しやすい)表現に変換するといった処理が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。
まぁ、簡単に言うと、
人間が脳内で行ってる処理と同じ処理を機械にさせること
です。
別で、「神経言語プログラミング」というものがあります。これも、英語で書くと"Neuro-Linguistic Programming"となり、"NLP"と略すことができます。
しかし、後述する、"spaCy"の説明文で
「spaCyは自然言語処理(NLP)のためのライブラリだ」
という記述があったので、統一するため、この記事での"NLP"は、「自然言語処理」とします。
Rasa
Rasa is an open source machine learning framework for automated text and voice-based conversations. Understand messages, hold conversations, and connect to messaging channels and APIs.
Rasaは文章・音声での会話の自動化のための機械学習フレームワークです。発言を理解し、会話を行い、そして、それらを言葉の種類に結び付けます。
簡単に言うと、
AIと簡単に会話ができるようになるツール
です。
spaCy
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python.
If you’re working with a lot of text, you’ll eventually want to know more about it. For example, what’s it about? What do the words mean in context? Who is doing what to whom? What companies and products are mentioned? Which texts are similar to each other?
spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning.
spaCyは、 Pythonの高度な自然言語処理(NLP)用の無料のオープンソースライブラリです。
大量のテキストを処理している時、最終的に、その文章についてもっと知りたいと思うでしょう。たとえば、「この文章はどういう意味なのか」「この文脈だと、この単語はどんな意味を持つのか」「誰が何を誰にしているのか」「どんな企業・製品が関わっているのか」「この文章と、どの文章が似ている文章なのか」
spaCyは製品用に特別に設計されており、大量のテキストを処理して「理解」するアプリケーションを構築するのに役立ちます。情報抽出または自然言語理解システムを構築するため、または深層学習のためにテキストを前処理するために使用できます。
難しい単語がたくさん出てきましたね。
まぁ、簡単に言うと、
非常に強力な、文章を理解したり、他のツールが文章を理解するのを助けるためのツール
です。
GiNZA
Universal Dependenciesに基づくオープンソース日本語NLPライブラリ
簡単に言うと、
NLPで日本語を使えるようにするライブラリ
です。
さて、この記事で扱っていくものが大まかに紹介したところで、本編へまいりましょう。
① 環境開発
まずは、環境開発です。
環境開発に関しては、Rasa公式に丁寧な説明があったので、それを参考にします。
この記事では、Windowsを前提に話を進めていきます。
違うOSを使ってる場合、インストール方法が少し変わってくるので、下のリンクを参考に進めてください。
Microsoft VC++ Compiler
ここから先は「Microsoft VC++ Compiler」が必要みたいです。
これは、Visual Studioからインストールできます。
忘れずにインストールしてください。
pipを最新バージョンにする
> pip install -U pip
Virtual Environment の起動
This step is optional, but we strongly recommend isolating python projects using virtual environments.
とあるように、公式が強く推奨しているので、仮想環境を使っていきます。
といっても、僕自身、あんま理解していないんで、書いてあるコードをそのまま実行しちゃいました。
> python -m venv ./venv
これで、仮想環境の起動構成ができた(?)らしいです。
> .\venv\Scripts\activate
これで起動できたみたいです。
ちなみに、仮想環境終了は、下のコマンドでできます
> deactivate
Rasa と spacy と GiNZA をインストール
> pip install rasa spacy ginza ja-ginza
Rasa init
環境開発だけじゃ味気ないので、ちょっとしたテストまでしちゃいます。
> mkdir RasaTest
> cd RasaTest
適当なフォルダを切って、
実行します。
> rasa init --no-prompt
これで、Rasaを使う準備ができました。
Rasaで会話 (初期設定)
それでは、実際に会話してみましょう
> rasa shell
これで起動しました。
> rasa shell
(省略)
Your input -> hi
Hey! How are you?
Your input -> good thanks
Great, carry on!
Your input -> bye
Bye
Your input -> /stop # このコマンドで終了
てな感じで、簡単な会話ができるようになりました。
しかし、このままでは、英語でしか会話ができません。
なので、日本語で会話できるようにしていきます。
② 日本語対応
ここからは、公式ドキュメントに明記されていないので、下の記事を参考にしていきます。
^ この記事では、時間帯を聞いて、予約を取るところまでの処理を行っているので、それに沿って話を進めていきます。
先に
さて、ここからの処理を始める前に、VSCodeなどのエディタで「rasa init」を実行したフォルダを参照しましょう。
initで追加されたファイルを編集していきます。
基本は、中身全削除&コピペで大丈夫です。
ドメインの設定
ドメイン:ドメインはボットを構築するのに使用する要素のこと
version: "3.0"
intents:
- greet
- ask_reserve
- nlu_fallback
entities:
- Time
slots:
reserv_time:
type: text
mappings:
- type: from_entity
entity: Time
responses:
utter_greet:
- text: "こんにちは!"
utter_reserve:
- text: "予約したい時間を入力してください。"
utter_default:
- text: "すみません。よくわかりませんでした。"
forms:
reservation_form:
required_slots:
- reserv_time
actions:
- action_reservation_time
session_config:
session_expiration_time: 60
carry_over_slots_to_new_session: true
intents
intentsはユーザーがbotに送信するメッセージの中で、botが処理する必要がある文章の種類を記述します。
ここでは、簡単な挨拶と予約時間を処理に回したいので、greetとreserveと記述します。
entities
entitiesには、ユーザーが入力した文章から、抽出したい要素名を記述します。
今回は、予約時間を取得したいので、Timeと記述しいます。
slots
slotsはbotが返信するときに使用する変数を記述します。
ここでは、「〇〇時に予約しました」といった風に、時間を返したいので、Timeを記述しています。
responses
responsesには、botがユーザーに返信する文章を記述します。
今回は、挨拶と予約時間を送信するように促す文章と例外処理のための文章を用意しています。
forms
formsはユーザーの文章から何か要素を取り出したいときに使用します。
今回は、予約時間(Time)が取得したいので、「Time」と記述しています。
actions
Rasaでは、定型文以外を返したいときは、"Action"というものを別途用意しなければなりません。これは、基本的にpythonで作成します。
今回は予約の完了を通知するためのaction_reservation_timeというactionを用意しました。
カスタムアクションはactionディレクトリ以下の.pyファイルに定義されます。
今回は、プロジェクトに最初から用意されていたactions.pyを以下のように書き換えてカスタムアクションを定義しました。
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
class ActionReservationTime(Action):
def name(self) -> Text:
return "action_reservation_time"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
time = tracker.slots("reserv_time")
dispatcher.utter_message(text="{}に予約を完了しました!".format(time))
return []
ここのクラス名はなんでもOK
ただし、Action.name内の返り値は、domain.ymlで登録するaction名と同じものにしなければならないので、視覚的にわかりやすいものにしましょう。
Action.runにはカスタムアクションとして実際に実行される処理を書きます。
このメソッドの引数は以下の用途で使用されます。
- dispatcher: ユーザーにメッセージを返すために使用します。
- tracker: slotや過去のメッセージ等の状態を保持します。
- domain: domain.ymlに書かれたドメインの情報について保持しています。
今回は、埋まっているであろうreserv_timeから値を取得して、予約完了のメッセージを送信するように組みました。
この処理は、actions/actions.pyで定義するのではなく、以下の方な方法でも実装することができます。
responses:
utter_reservation_time: # action_reservation_timeと同じ挙動
- text: "{reserv_time}に予約を完了しました!"
モデルの設定
Rasaは自然言語理解(Natural Language Understanding, NLU)モデルを利用して、ユーザの入力したテキストからintentを予測したり、入力に対するactionの選択を行います。このモデルの設定はconfig.ymlというファイルに記載されます。
今回用いる設定は以下の通りです。この設定ファイルはlanguageとpipeline、policiesをキーに持つ連想配列となります。
recipe: default.v1
language: ja
pipeline:
- name: SpacyNLP
model: 'ja_ginza'
- name: SpacyTokenizer
- name: SpacyFeaturizer
- name: SpacyEntityExtractor
- name: RegexFeaturizer
- name: LexicalSyntacticFeaturizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
- name: FallbackClassifier
threshold: 0.7
policies:
- name: MemoizationPolicy
- name: RulePolicy
- name: TEDPolicy
max_history: 5
epochs: 100
language
チャットボットで使用する言語を定義します。今回は日本語なのでjaを指定しています。
pipeline
ユーザーが入力した文章をどのように処理するかを記述しています。
今回はRasaの公式がおすすめしている設定を元にSpacyNLPのmodelをGiNZAに変更、加えて固有表現抽出にGiNZAを用いるためのSpacyEntityExtractorを追加しました。
その他のパイプラインの詳細については公式ページに詳しく記載されているため、そちらをご覧ください。
policies
policiesはユーザの入力に対してボットがどのような対応をするかを決定するために使用されます。
これも、推奨設定を使っています。
モデルの訓練データ
ここから先は、ボットの処理をより作りこんでいきます。
nlu
nluの値には、intentの例となる文を用意します。
ここで定義した文章と似ている文章をintentのタグにひっかけて処理を行います。
ドメインで設定したように、ボットに対する挨拶となるgreetと予約をするためのトリガーであるreserveの2つのintentを宣言しているので、それらに対する入力の例を与えています。
version: "3.0"
nlu:
- intent: greet
examples: |
- こんにちは
- おはようございます
- こんばんは
- やっほー
- Yo
- こん
- ちゃ
- intent: ask_reserve
examples: |
- 予約をする
- 予約をお願いします
- 予約をしたい
- 予約できますか?
rules
rulesは、あるintentや条件に対しての決まった処理を行います。
これはconfig.ymlにおいてRulePolicyを指定していない限り無効となります。
今回は、ユーザの入力がgreetとreserveのintentのどちらにも当てはまらない(Fallbackが発生する)場合にutter_defaultレスポンスを返すように設定しています。
そして、Reserveという、予約フォームが起動している時に時間に関する入力があった場合処理を行うルールも設定しました。
version: "3.0"
rules:
- rule: Fallback
steps:
- intent: nlu_fallback
- action: utter_default
- action: action_back
- rule: Reserve
condition:
# Condition that form is active.
- active_loop: reservation_form
steps:
# Form is deactivated
- action: reservation_form
- active_loop: null
- slot_was_set:
- requested_slot: null
# The actions we want to run when the form is submitted.
- action: action_reservation_time
- action: action_restart
stories
storiesはユーザとボットの対話の例を示す訓練データです。
ユーザーの返答に対し、何か、物語を展開するときに使うことが推奨されています。
version: "3.0"
stories:
- story: Greeting
steps:
- intent: greet
- action: utter_greet
- action: action_back
- story: Ask Reservation
steps:
- intent: ask_reserve
- action: utter_reserve
- action: reservation_form
- active_loop: reservation_form
以下に、それぞれのstoryがどのように進行するかを示します。
エンドポイント設定
モデルの設定やデータの準備は終わりましたが、最後にエンドポイントの設定をendpoints.ymlに書く必要があります。 今回はカスタムアクションを設定しているため、アクションサーバのエンドポイントを定義しておきます。
action_endpoint:
url: "http://localhost:5055/webhook"
モデル訓練
モデルの訓練は、プロジェクトのルートディレクトリで下記のコマンドを実行するだけです。 このコマンドはdomain.ymlやconfig.ymlの変更を気にしないため、もしこれらのファイルのみを変更して再学習を行いたい場合は、--forceをオプションを付ける必要があります。
> rasa train
訓練されたモデルはmodelsディレクトリに置かれます。
何もオプションを指定していない場合はyyyymmdd-hhmmss.tar.gzという名前で保存されます。
チャットボット実行
モデルを学習すると、実際にチャットボットを実行することが可能です。 ただし今回のようにカスタムアクションを定義している場合は、アクションサーバーを立てている必要があります。
Windowsには、同時に二つのコマンドを同じコンソールで実行する方法がないので、
もう一つ、"venv"を起動したコンソールを用意して、以下のコマンドを実行してください。
> rasa run actions
rasa_sdk.executor - Registered function for 'action_reservation_time'.
このような文字列が表示されていれば、うまく起動しています。
その後、元のコンソールに戻り、CLIで対話的にチャットボットを実行するための、shellコマンドを使用します。
> rasa shell
(省略)
Your input ->
実際に動いているかどうか確かめてみます。
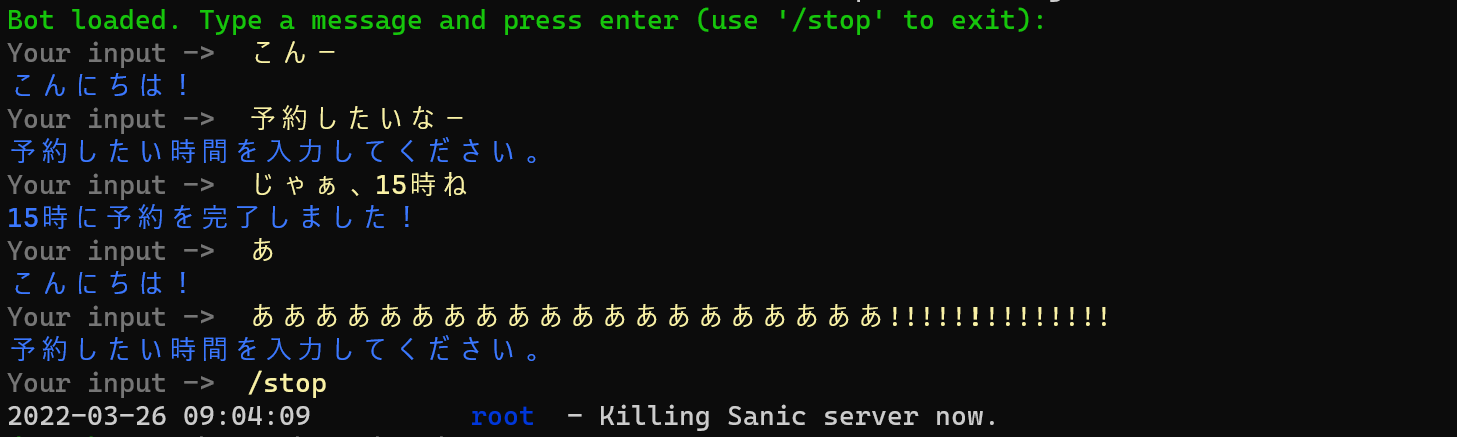
奇声を発したのにもかかわらず、予約時間を答えるように言われてますね。
この原因として、「閾値が低すぎた」ということが考えられます。
なので、閾値を上げに行きます。
閾値を上げる
...
pipeline:
...
- name: FallbackClassifier
- threshold: 0.7
+ threshold: 1
...
閾値を1に変更しました。
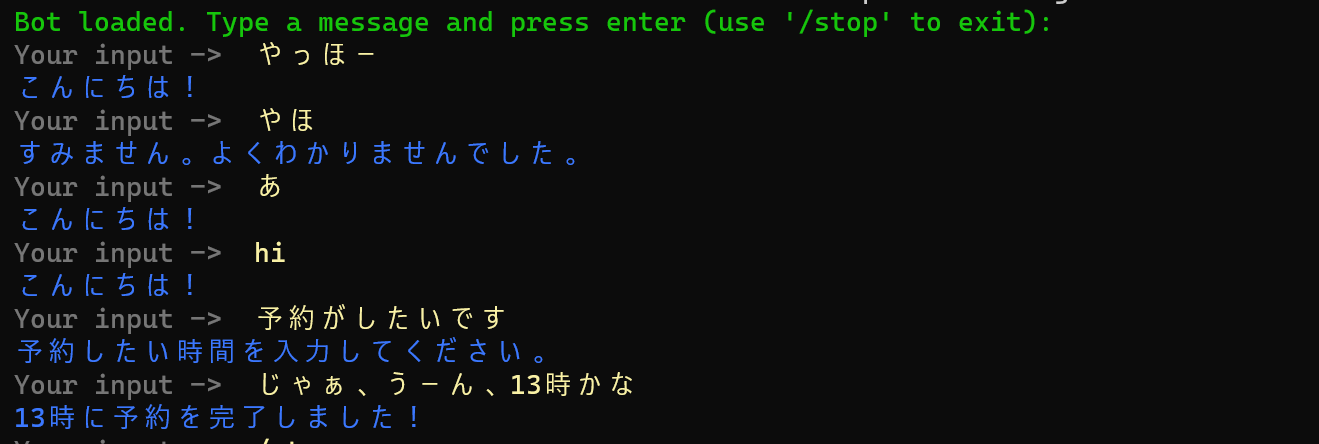
挨拶ぽいものがfallbackに流れていますが、これは、nlu.ymlの量を増やせば解決できるので、大丈夫です。
予約文章の認識も、時間指定の文章の認識もうまくいっていますね。
チュートリアルはここまでです。
お疲れさまでした。
では、次は、これを改造していきます。
③ 改造
と、思いましたが、書いていたら、ちょっと長くなりすぎたので、次の記事にまとめます。
↓↓↓↓↓ 次の記事 ↓↓↓↓↓
終わりに
どうでしたか?
AIの開発、めちゃくちゃ簡単でしたね。
では、次の記事も書ききらないといけないので、ここら辺で。
じゃ、また ノシ