1. 概要
今回は機械学習の一種、サポートベクタマシン(英:Support Vector Machine, SVM)を使用してりんごと梨の分類を行いました。りんご、梨それぞれ10個の画像の画素値(平均値)を用いて2成分でSVMにかけることで分類出来るか調査しました。
ちなみに、SVMというのは全てのデータポイントではなく、境界付近の一部のデータポイントをピックアップして、境界を決定する手法になります。そして、その境界付近のデータポイントをサポートベクタと呼んでいます。
2. 用意するデータ
事前にりんごと梨のRGB画素値の平均値を取得します。
参考としてりんごの画素値の平均値のcsvファイルは下のapple.csvを使用しました。opencvを使用しているので並び順がBGRとなっています。りんごだけあって、Redの画素値が高いですね。
因みに、このcsvファイルの作成方法は別記事で紹介しているので是非見てみてくださいね!↓↓↓
[【Python】対象物の画素値RGBの平均値を計算する][3]
[3]:https://qiita.com/ZESSU/items/40b8bb2cd179371df6ac
りんごのcsvファイルに加えて梨のcsvファイルも予め作成しておきます。
,blue,green,red
0,39.88469583593901,28.743374377331637,137.23369201906283
1,83.72563703792319,79.59471228615863,164.77884914463453
2,66.8231805177587,74.52501570023027,141.8854929872305
3,55.2837418388098,45.28968211495237,148.4160869099861
4,37.59397951454073,49.82323881039423,137.30237460066527
5,53.68868757437335,50.963264366051206,142.6121454070861
6,51.277953772145956,64.07145371348116,152.98116860260473
7,50.47702848900108,48.37151099891814,124.46714749368914
8,40.35442093843233,52.0682126390019,137.8299091402224
9,48.18758094199441,55.87655919841865,145.6361529548088
3. 環境
今回はライブラリで
・matplotlib
・numpy
・scikit-learn
・mglearn
を使用するのでこれらのライブラリをインストールする必要が有ります。まだ入っていないライブラリは、下のコマンドでインストールしてくださいね。
pip install matplotlib
pip install numpy
pip install mglearn
pip install scikit-learn
4. コード
今回は2次元でSVMをかけたので、BGRのBG, GR, BRの3パターンで観察します。
コードにコメントを付けておいたので参考にしてみてくださいね。
ちなみに日本の梨って英語で「Japanese pear」と言うらしいです。「pear」は洋梨らしいです。(コードでは「Japanese pear」とすると長くて読みにくいので「pear」にしました。)
import os
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
from sklearn.svm import LinearSVC
import mglearn
def main():
path = 'output'
os.makedirs(path, exist_ok=True)
apple = np.loadtxt('input/apple.csv', delimiter=',', skiprows=1,usecols=[1,2,3]) #appleのcsvファイルから画素値データを取得
pear = np.loadtxt('input/pear.csv', delimiter=',', skiprows=1,usecols=[1,2,3])
#pearのcsvファイルから画素値データを取得
SVM2D(np.delete(apple,2,1), np.delete(pear,2,1),'blue','green',path) #bgrのbgをSVMにかける
SVM2D(np.delete(apple,0,1), np.delete(pear,0,1), 'green', 'red',path) #bgrのgrをSVMにかける
SVM2D(np.delete(apple,1,1), np.delete(pear,1,1), 'blue', 'red',path) #bgrのbrをSVMにかける
def SVM2D(ap_pv, pe_pv, xlabel, ylabel, path):
yap=[0]*ap_pv.shape[0] #りんごのデータ数分の0の並んだ配列を作成
ype=[1]*pe_pv.shape[0] #梨のデータ数分の0の並んだ配列を作成
y = np.array(yap+ype) #りんごと梨の訓練データ分類の配列
X = np.concatenate([ap_pv,pe_pv],0) #りんごと梨のデータ(RGB画素値)の配列
#SVMの境界図を作成
linear_svm = LinearSVC().fit(X, y)
fig=plt.figure(figsize = (10, 6))
ax = fig.add_subplot(1,1,1)
ax.axis('normal')
mglearn.plots.plot_2d_separator(linear_svm, ap_pv)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
ax.legend(['apple', 'pear'])
ax.xaxis.set_major_locator(ticker.MultipleLocator(20))
ax.yaxis.set_major_locator(ticker.MultipleLocator(20))
ax.tick_params('x', labelsize =15)
ax.tick_params('y', labelsize =15)
ax.set_xlabel(xlabel, fontsize= 20)
ax.set_ylabel(ylabel, fontsize= 20)
plt.savefig(path+'/SVM_'+xlabel+'_'+ylabel+'.png')
#訓練データの正答率を出力
print('score on training set: {:.2f}'.format(linear_svm.score(X,y)))
if __name__=='__main__':
main()
5. 結果と考察
3パターン「Blue-Green」,「Green-Red」,「Blue-Red」についてSVMを行った結果、それぞれの境界線は下図となりました。
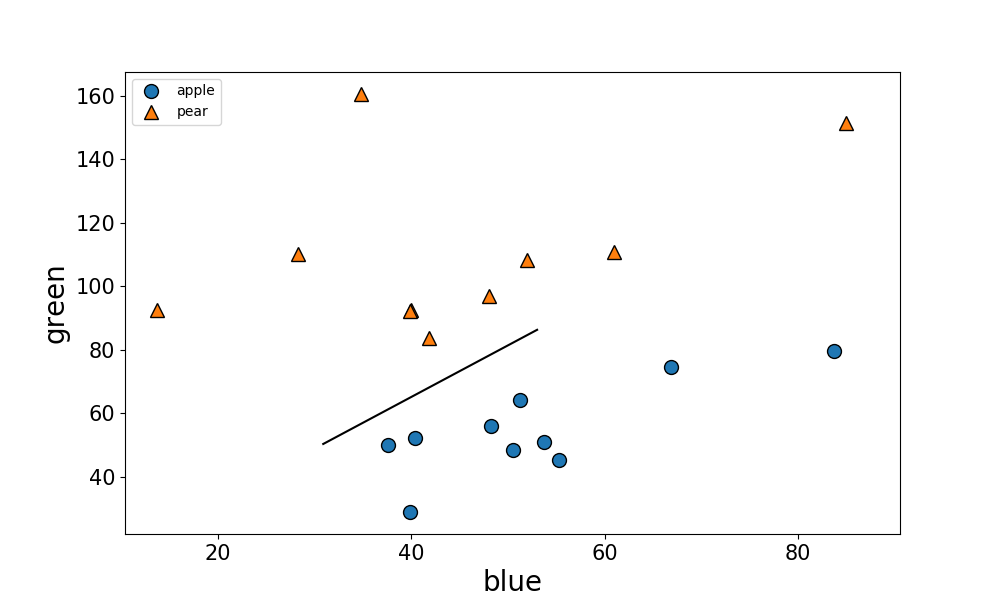
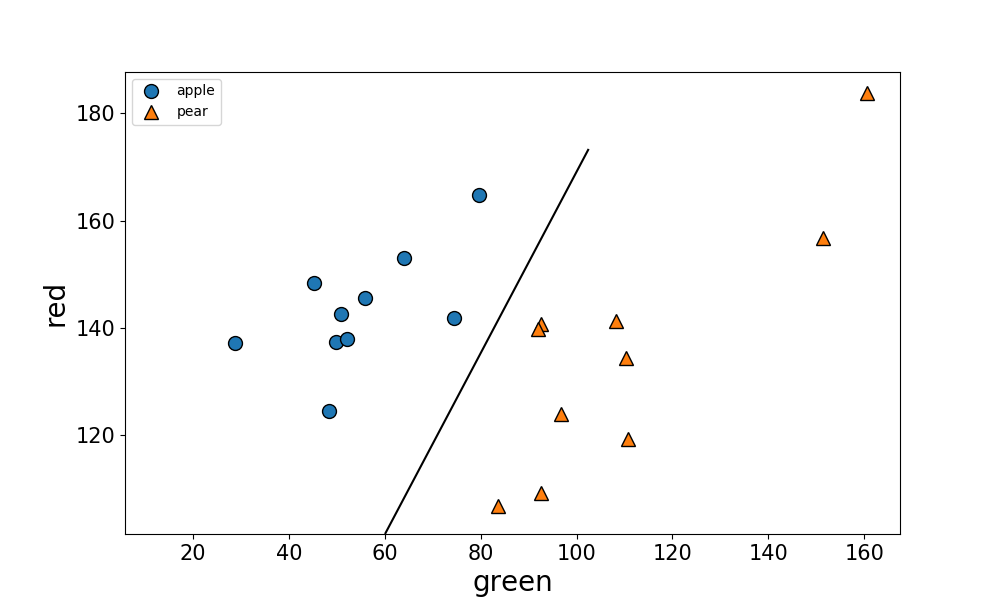
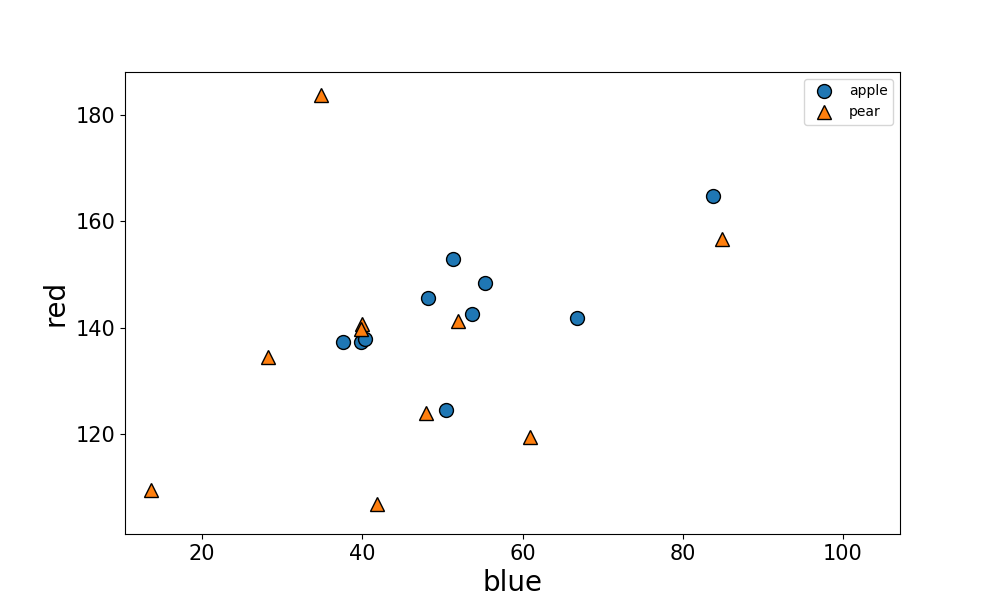
Blue-Redはデータポイントが混ざってしまって分類が出来ていません。それに比べて、Blue-Green、Green-Redの図を見ると、はっきりとりんごと梨を分けることが出来ました。
このことから、梨とりんごの判別には赤でも青でもなく、緑色の情報が大事なことがわかりました。
RGB画像では、りんごはRedを基調としますが、梨は黄緑色なのでGreenとRedを基調とします。
なので、りんごと梨では緑色に明瞭な違いが出たんですね。
6. 参考文献
★サイト
・[[python 機械学習初心者向け] scikit-learnでSVMを簡単に実装する][0]
[0]:https://qiita.com/kazuki_hayakawa/items/18b7017da9a6f73eba77
・[「梨」の英語|洋ナシや「日本の梨」の正しい発音と関連英語][1]
[1]:https://mysuki.jp/english-pear-7661
「Pythonではじめる機械学習」は機械学習の勉強をしている人にとって、とても参考になる書籍です。実際に機械学習する際のサンプルコードなどが載っており私も大変重宝しています。内容は読みやすいほうですが、Pythonと機械学習や深層学習の基礎を知っている人向けかなと思います。ぜひ手にとって読んでみてくださいね!