はじめに
記事をご覧いただきありがとうございます!
皆さん、カオスエンジニアリング活用されていますか?
私自身、数年前に興味を持って触っていたのですが、クラウド環境で疑似的に障害を起こせるという点で、システムの信頼性を高めるには非常に便利な手法ですよね。
一方で、思いのほか引き合いがなく、最近は私自身もカオスエンジニアリングをあまり追えていませんでした。
そんな中、担当している案件で、AWSのカオスエンジニアリングツールである AWS Fault Injection Simulator(以下、FIS)を使って、AZ障害時の挙動を確認する障害テストを行うことになり、久しぶりにFISを触りました。
ところが、 全然思っていたように動かない という事態に…。
原因は、FISの疑似AZ障害がACLを使って通信を遮断する仕組みにありました。仕組み自体は理解していたつもりだったのですが、いざ実際に障害を起こしてみると、考慮が全然足りていなかったなと痛感しました。
そのうえで、正しく動作するように暫定対応を行ったのですが、この対応はFIS用の一時的なものではなく、 実際の運用でも必要になってくるのでは? と感じたため、今回その内容を共有させていただきます!
カオスエンジニアリングとは
カオスエンジニアリングについて簡単におさらいしておきます。
ざっくり言うと、 「あえて障害を起こして、システムがちゃんと耐えられるかを確認する」 という手法です。
Netflixが「Chaos Monkey」を開発し、始めたことで有名で、クラウド時代の信頼性設計においては、非常に重要なアプローチになっています。
FISは、AWSが提供するカオスエンジニアリングのツールで、ネットワーク遮断やCPU負荷、AZ障害などを 安全にシミュレーションできる のが特徴です。
他にも、Gremlin や Azure の Chaos Studio なども有名ですね。私自身、Azure Chaos Studio は使ったことがありますが、FISと似たような感覚で使えます。
ただ、ここで大事なのは、 カオスエンジニアリングは“テストツール”ではない ということです。
単なる「壊してみるテスト」ではなく、本番環境での信頼性を高めるための“設計思想”や“運用文化” なんです。
つまり、「壊してみて終わり」ではなく、
- どういう前提で設計しているか
- どこに弱点があるか
- それをどう改善するか
まで含めて考えるのが、カオスエンジニアリングの本質です。
とはいえ、今回はアンチパターンですが、テストの一環として“テストツール的”に使ってしまったのが正直なところです。
ですが、ここから得られた気づきをもとに運用改善につなげることができたので、結果的には想定外の形ではありますが、 カオスエンジニアリングと呼べる取り組みになったのではないか と思っています。
構成と実行した実験
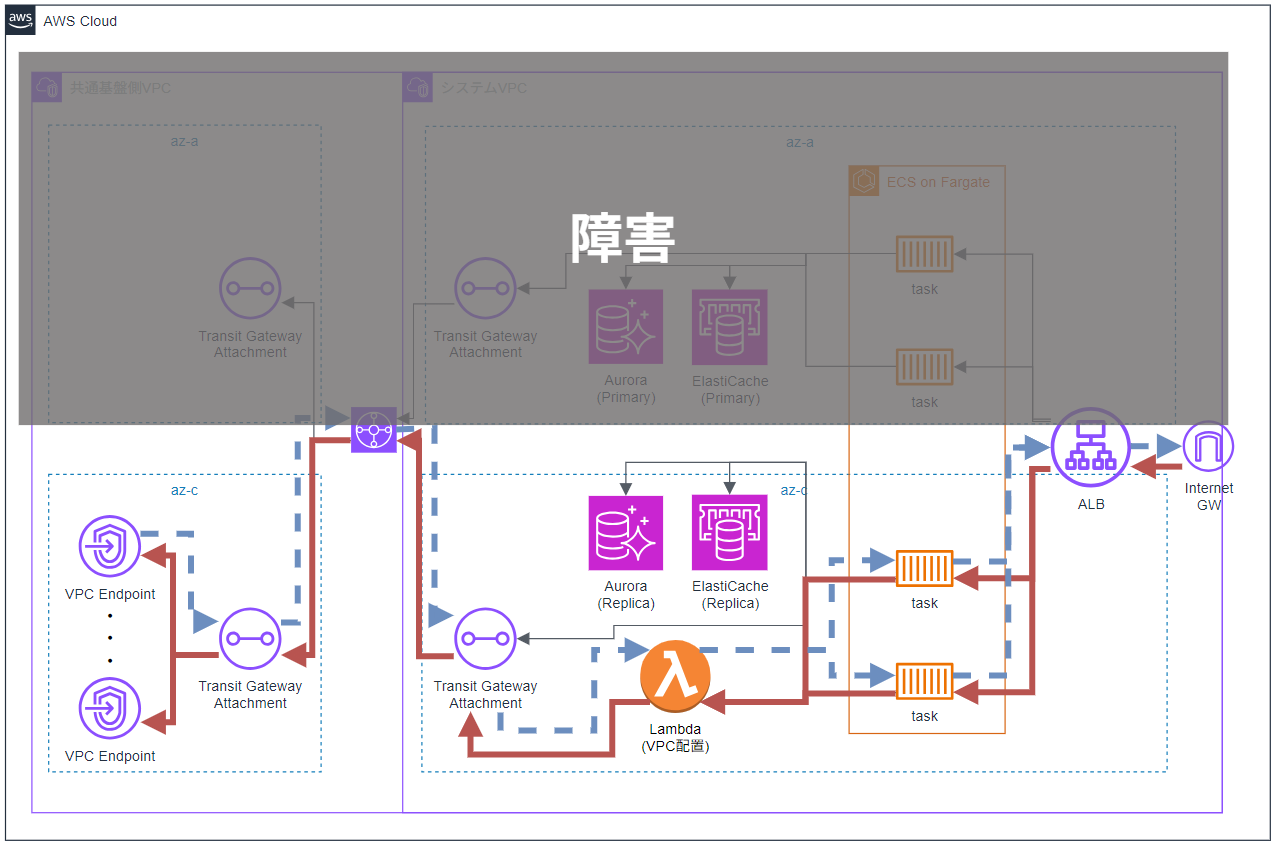
今回のテストで関係するリソースのみを抜粋した概要構成図は、以下の通りです。
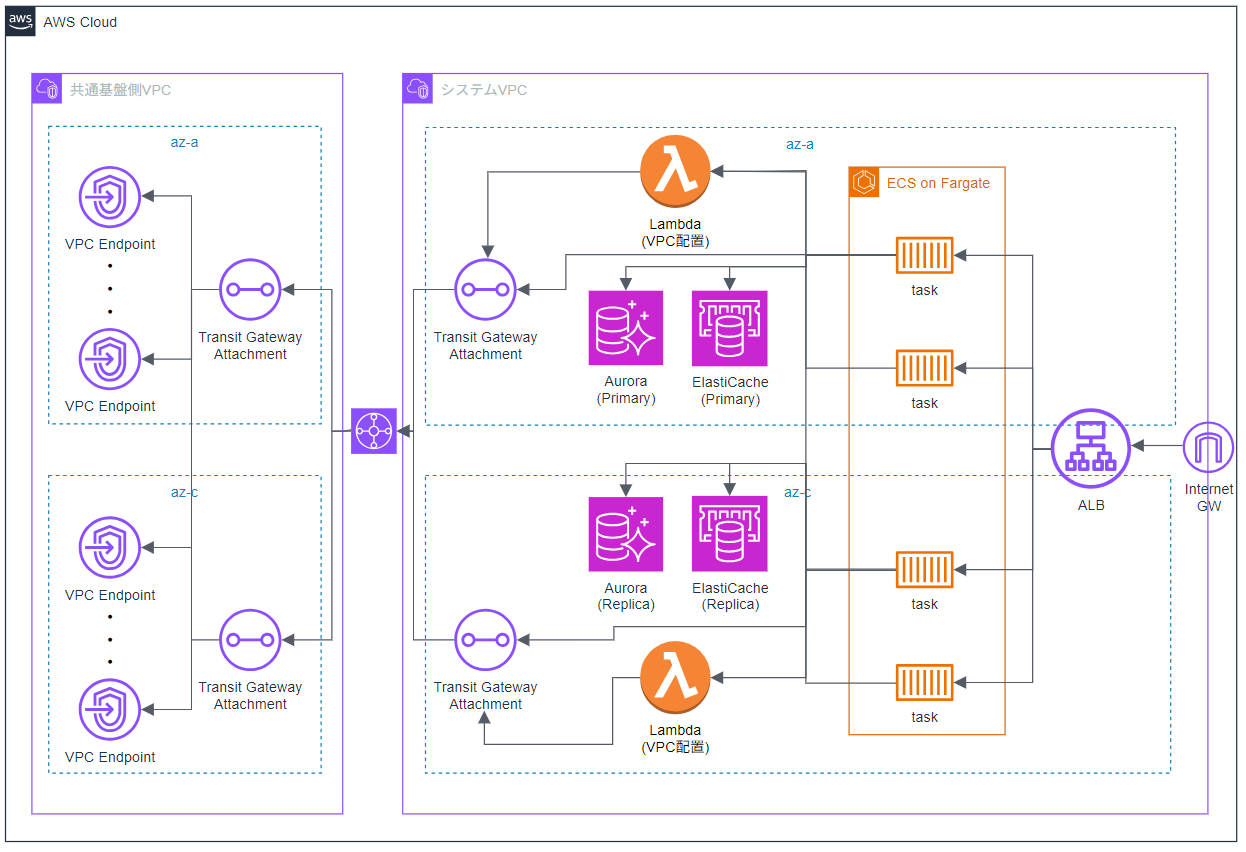
基本的には、2つのAZを使ったマルチAZ構成になっており、ALBで通信を受け、ECS上のタスクで動作するアプリが処理に応じてさまざまなリソースに接続します。
そのアプリから呼び出されるリソースの1つにLambdaがあり、こちらはVPC内に配置されています。
また、Transit Gatewayを介して「共通基盤」と呼ばれる別VPCに接続しており、そこにVPC Endpointを配置して集約を行っています。
マルチAZ構成ということで、片方のAZに何らかの障害が発生しても、システムが正常に動作するかを確認するため、AZ障害をメインに、AuroraやElastiCacheのフェイルオーバーも含めて、以下の3つの実験を行いました
- AZ障害:aws:network:disrupt-connectivity
指定したサブネットに対してACLルールで全通信を遮断することで、受信・送信ともに不可能となり、疑似的にAZ障害のように見せる障害です。
ただし、ACLによる遮断のため、同じサブネット内のリソース間の通信は通ってしまいます。 - Auroraのフェイルオーバー:aws:rds:reboot-db-instances
指定したインスタンスを再起動し、オプション forceFailover を true に設定することで、マルチAZ構成の場合は別AZへのフェイルオーバーを強制的に実行します。 - ElastiCacheのフェイルオーバー:aws:elasticache:replicationgroup-interrupt-az-power
マルチAZが有効な場合のみ実行可能で、指定したAZ内のノードの電源を中断することで疑似障害を発生させます。
プライマリノードが対象だった場合、レプリケーション遅延が最も小さいレプリカが昇格します。
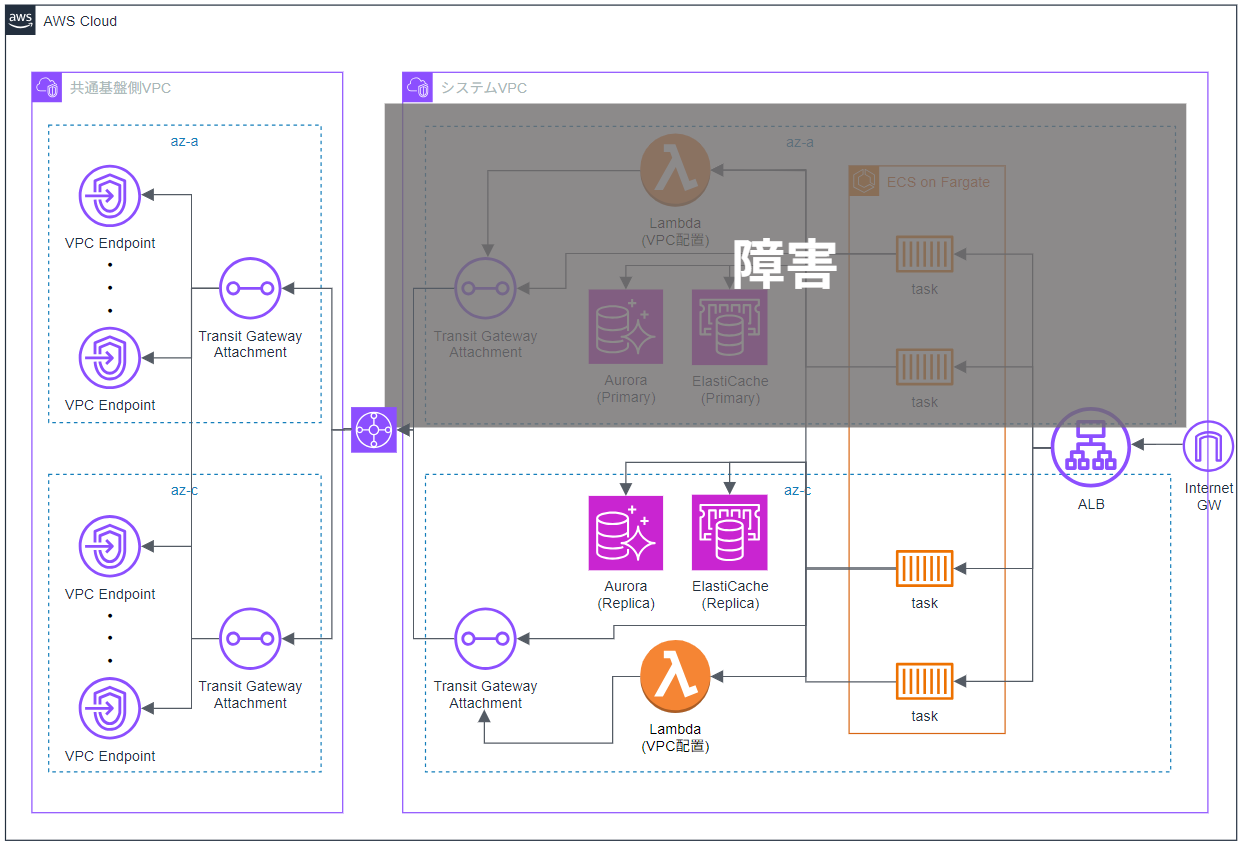
実験時のイメージは以下の図の通りです。
共通基盤については我々の担当範囲外となっており、今回は担当システム側のみ障害を発生させ、共通基盤側は障害対象外としています。
接続エラー続出
先ほど紹介した構成に対して、FISの実験を実行したうえでシステムにアクセスしてみたところ、 エラーが続出し、正常に動作しませんでした。
Lambda
まず最初に、Lambdaでタイムアウトが発生していることに気づきました。
Flow Log を中心に各種ログを確認したところ、障害中のAZに配置された Lambda の IP が、サブネット外に出ようとして REJECT されていることが分かりました。
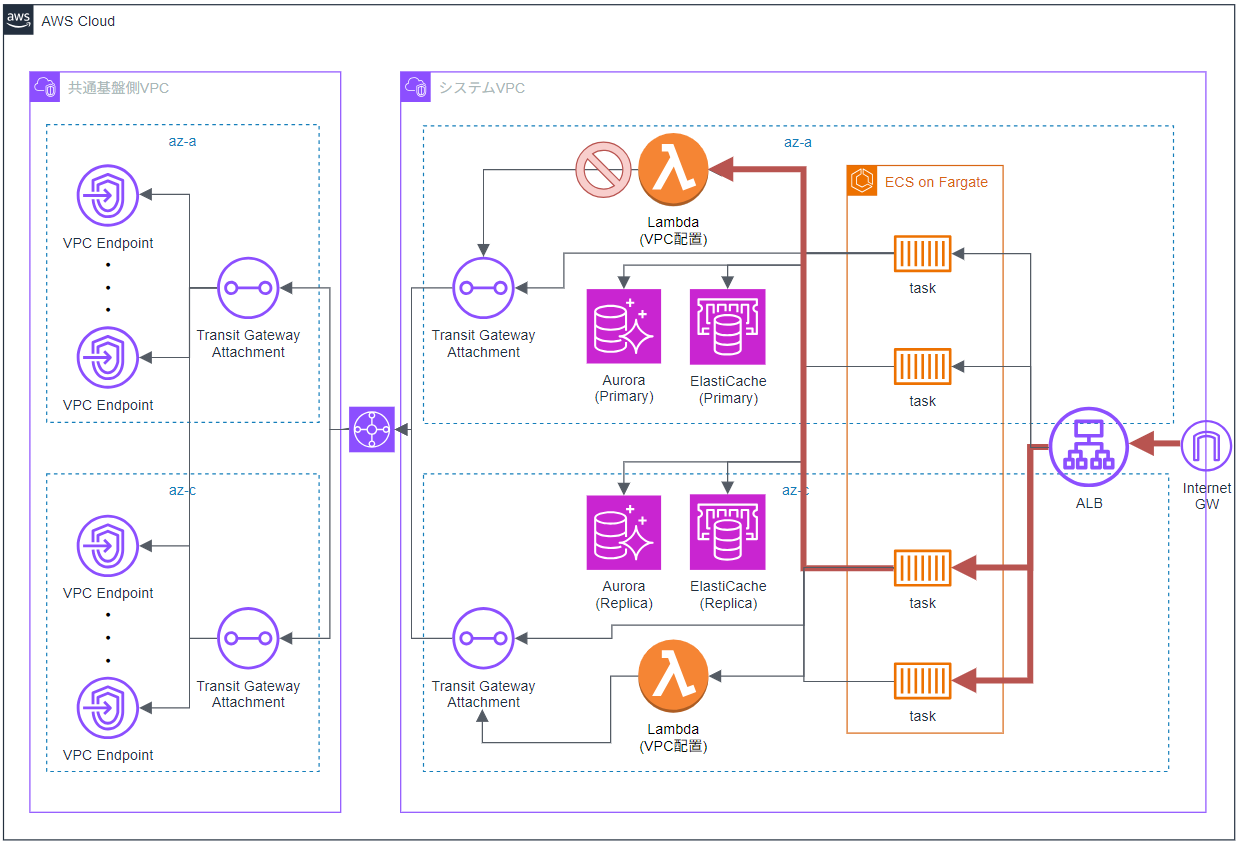
※赤線が行きの線
この原因ですが、VPC配置の Lambda は送信元の IP がサブネットのものになるだけで、受信側の挙動は通常の Lambda と変わりません。
そのため、FISの疑似AZ障害では Lambda が障害を検知できず、障害中の AZ の IP を使ってしまっていました。
この問題に対しては、Lambda の配置サブネットを障害が発生していないサブネット(1つのAZ)に変更し、再度動作確認を行いました。
なお、この挙動については AWS サポートにも確認済みで、対応としては AZ の片寄せしかない とのことでした。
VPC EndpointとTransit Gateway
Lambda を修正したうえで再度アクセスしてみましたが、状況は改善されませんでした。
再度ログを確認すると、引き続き Lambda でタイムアウトが発生していました。
ただし、Flow Log を見ると、先ほど詰まっていた Lambda からの通信は ACCEPT されており、帰りの Transit Gateway 経由の通信で REJECT が発生していることが分かりました。
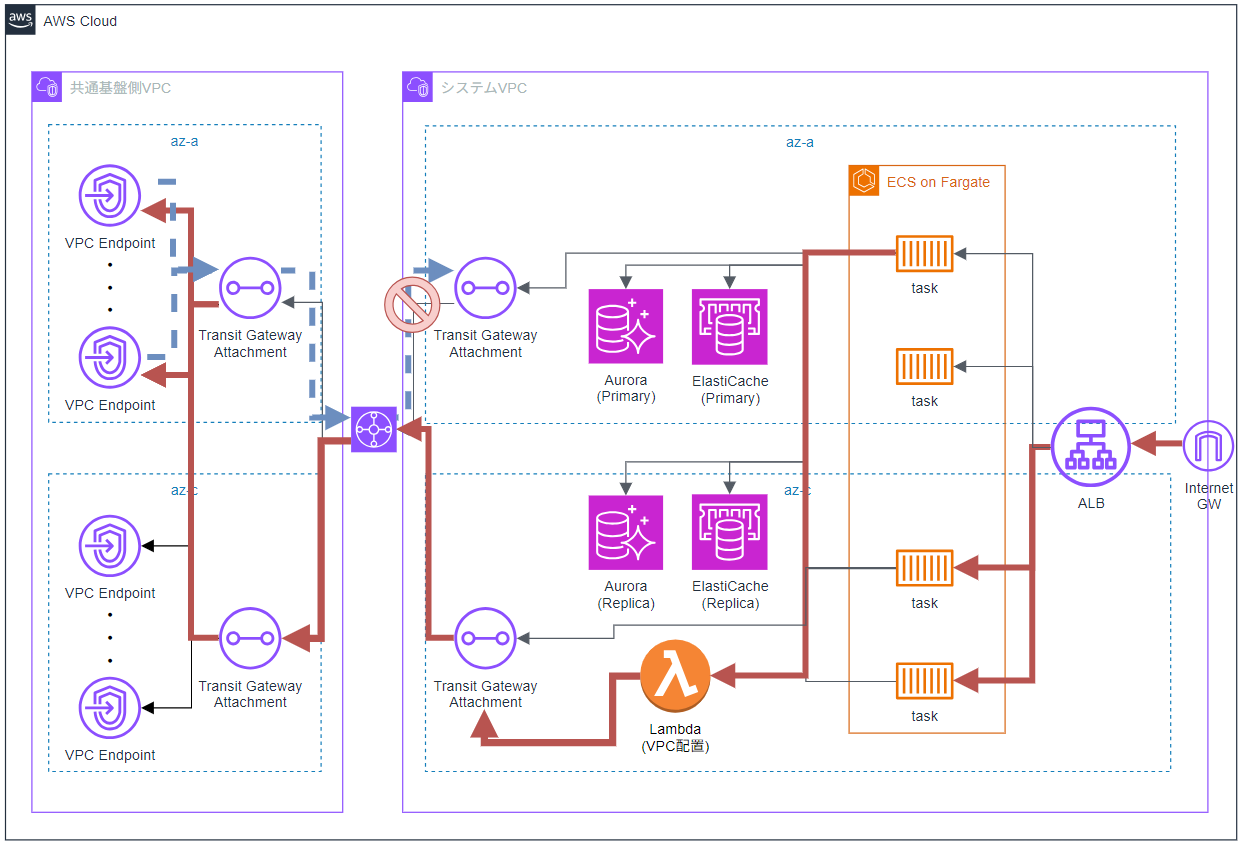
※赤線が行きの線、青点線が帰りの線
Transit Gateway は 同じ AZ を通ろうとする挙動 があります。
今回のケースでは、AZ-C から通信が発生しているため、VPC Endpoint までは AZ-C を使って通信が行われます。
一方で、VPC Endpoint はマルチAZ配置となっており、リージョン DNS を参照している関係上、AZ-A の VPC Endpoint が呼ばれるケースもあります。
その場合、 非対称ルーティング となり、帰りの通信が AZ-A を通ってシステム側 VPC に戻ろうとする際に REJECT されてしまっていました。
この挙動については、AWS の公式ドキュメントでも「Transit Gateway が非対称ルーティングになることがある」としてまとめられています。
ご参考までに、以下のリンクをご覧ください。
この対応策として、共通基盤側でも同様に FIS で AZ 障害を起こさないと意味がないという話になりました。
一方で、これまでの流れから「VPC Endpoint も片寄せしないと、障害を起こしても意味がないのでは?」という懸念が出てきました。
VPC Endpoint は VPC 配置の Lambda とは異なり、 受信側の通信もサブネット内の IP を使う ため、FIS の ACL による遮断が効くように見えます。
しかし、AWS 管理のリソースであるため、 FIS の疑似障害を検知できない可能性がある という疑念がありました。
この点についても AWS サポートに確認したところ、懸念の通り、VPC Endpoint は内部的に障害検知の仕組みを持っているものの、 VPC 側の障害は検知できない とのことでした。
そのため、VPC 配置の Lambda と同様に、VPC Endpoint を片寄せし、さらに共通基盤側にも障害を発生させたうえで再度動作確認を行ったところ、 想定通りの挙動が確認できました。
※赤線が行きの線、青点線が帰りの線
これはFISだけの話なのか?
ここまで読んでいただくと、「FISのACL遮断ってちょっと特殊だな」と思われた方もいるかもしれません。
確かに、FISのAZ障害はACLで通信を遮断することで疑似的に再現しているため、 完全なAZ停止とは違う挙動になります。
ただ、ここで重要なのは、 実際のAWS障害でもAZ全体が完全に停止するケースは非常に稀 だということです。近年のAWSの障害を見ても、今回のように
- 一部のリソースだけが不安定になる
- 通信経路が偏る
- フェイルオーバーがうまくいかない
といった、 AZ全体ではなく一部に影響が出る“グレー障害” のパターンが多く見られます。
そのため、最近のAWSにおいても、 グレー障害への対策・対応 が重要なトピックになりつつあります
つまり、今回FISで遭遇したような
- 障害中のAZを経由してしまう
- マネージドサービスがFISで起こした障害を検知できない
といった挙動は、 FIS特有の問題ではなく、実運用でも十分に起こり得る ということです。
暫定対応は“テスト用”じゃなく“運用用”にもなる
今回の対応として、LambdaやVPC Endpointを 片AZに寄せるという構成変更 を行いました。
この対応は一見すると「FISテストのための一時的な対応」に見えるかもしれませんが、実はそうではありません。
実際の障害時にも、同様の構成変更を行うことで 障害の影響を最小限に抑えることができる可能性 があります。
特に、障害がグレーな場合や、マネージドサービスが障害を検知できない場合には、 手動で片AZに寄せる運用手順 があると安心です。
そのため、今回の対応は「FISテストのための暫定対応」ではなく、 本番運用でも活用できる“前提対応” として、手順書に落とし込むべきだと感じました。
まとめ
今回のFISによるAZ障害テストでは、ACL遮断による疑似障害の限界に直面しました。
LambdaやVPC Endpoint、Transit Gatewayなど、 AWS管理のマネージドサービスが障害を検知できない 、あるいは 非対象ルーティングが発生する といった盲点に気づき、構成変更によって対応しました。
この経験から得られた学びは以下の通りです。
- カオスエンジニアリングは単なるテストではなく、 システムの信頼性を高めるために必要
- FISのACL遮断では、 完全なAZ障害は再現できない
- マネージドサービスの挙動には注意が必要
- Transit Gatewayの非対象ルーティングには要注意
- 実際のAWS障害でも、 AZ全体に障害が起きることは少なく、グレー障害が多い
- FIS実験時の構成変更は、 運用時にも活用できる
また、共通基盤があるという特殊な環境だったため、影響がより顕著に現れたとも考えられます。
とはいえ、最近ではコスト削減の観点からVPC Endpointの集約が進んでいたり、共通基盤を設けて複数システムを統合的に管理するケースも増えていると思います。
だからこそ、 共通基盤や集約VPCがある環境では、予測できない挙動が起こる可能性がある と考え、ぜひカオスエンジニアリングを活用して、システムの信頼性を高めていただければと思います。
最後までお読みいただき、ありがとうございました!
We Are Hiring!