はじめに
経緯
- 趣味でグラビア画像をディープラーニング(DL)で生成する研究をしている。
- TensorFlow Research Cloud (TFRC) に応募したら11月末から1ヶ月間の無料期間をもらえた。
- Cloud TPUの概要や使い方、注意点などがわかったのでまとめておく。
正確な話はどう考えても公式資料を見たほうが速くて正確です。英語だとわかりにくい雰囲気やドキュメントにない気づきなどを伝えられればと思っている。ご了承願いたい。
Google Cloud TPUとTensorFlow Research Cloud
- TPU
- Googleが作ったスゴイヤバイDL向けプロセッサ。現在v3まで出ている。
- Cloud TPU
- TPUをGoogle Cloudで使えるようにしたもの。現在TPU v2, TPU v3(beta), TPU v2 pod(alpha)が使える。
- TPU v2
- 現在の標準っぽい位置づけ。180TFLOPS、64GBメモリ(1コア8GB)。
- TPU v3
- 次世代のもの。420TFLOPS、128GBメモリ(1コア16GB)。
- Cloud TPU v2 pod
- 2コアTPUx4基=8コアを1マシンに載せたのが標準のTPU v2ホスト。これをクラスタ化したものがTPU v2 pod。
- Google Cloud Storage
- GCS。Googleのクラウドストレージ。AWSでいうところのS3みたいなもん。
- Google Compute Engine GCE。いわゆるクラウド仮想マシン。TPUホストと通信するのに必要になる。
今回無料で使用させてもらえるのはTPU v2を非プリエンプティブ5台、プリエンプティブ100台。
(手際が悪くて非プリエンプティブ1台だけ使ってる状況ですが・・・)
Cloud TPUを使ってみる
Google Cloud TPUの使い方 (1/2)
作業に関わるマシンやストレージの構成はだいたいこんな感じ
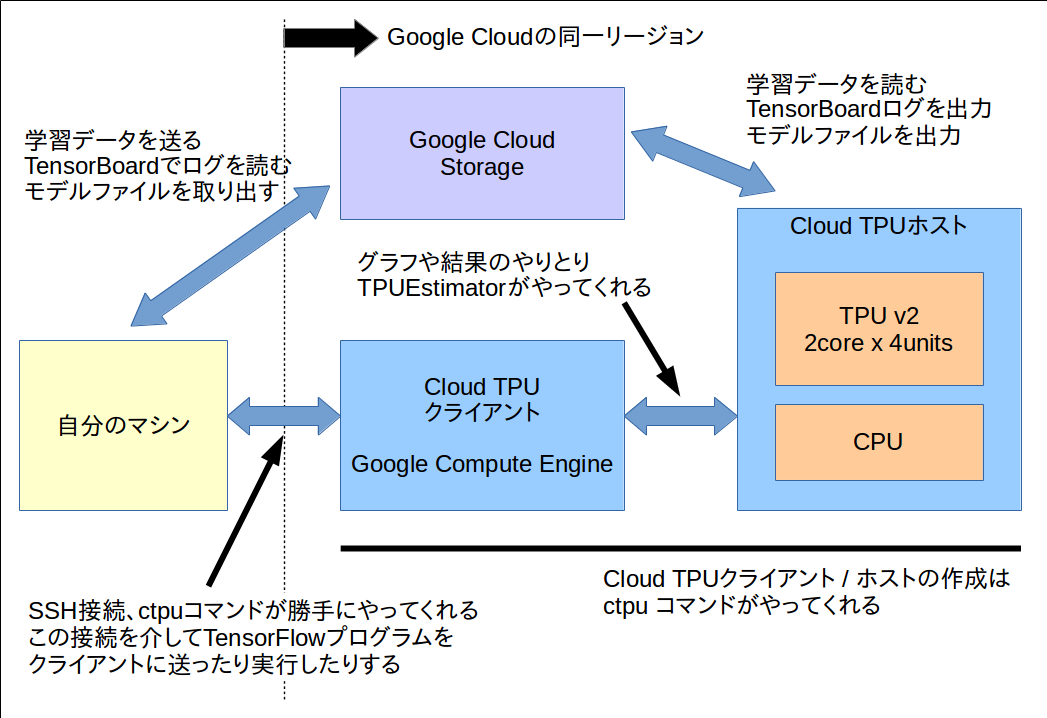
Google Cloud TPUの使い方 (2/2)
- TensorFlowプログラムを書く
- 学習データをTFRecordにまとめてGoogle Cloud Storageへ送る
- TFRecord必須ではないと思うけれど試してない。たぶんTFRecordでやるのが幸せなはず。
-
ctpuコマンドでCloud TPUのホストとクライアントを立ち上げてクライアントにSSHログインする。-
ctpuはCloud TPUホストとクライアントを作ったり停止したり再起動したり削除したりするツール。チュートリアルをやればわかる。 - TPUホストと通信するには同じバージョンのTensorFlowやGoogle Cloudサービス系のツールが入っている必要がある。
-
ctpuはクライアントを作成する際にこれらが適切にインストールされたイメージを使ってくれる。
-
- 自分のマシンからクライアントにTensorFlowプログラムを引っ張ってくる。
- クライアントからTensorFlowプログラムを実行する。
- checkpointファイルやTensorBoardのファイルはGCSに格納される。
- 標準のTensorBoardならGCSにあるTensorBoardファイルを直接読めるので自分のマシンから学習状況をモニタすることが可能。
まったく試していないのだけれど ctpu コマンドが作るクライアントって実はなくても良くて自分のマシンから直接TPUホストを使えるんじゃないかと思っている。余裕があれば方法を探っていきたい。
TPUEstimator
- Cloud TPU向けのコードを書く場合
tf.contrib.tpu.TPUEstimatorを用いた学習コードが必須になる。 - Cloud TPUの2コア4ユニットを有効に使うために自動でデータパラレル用のミニバッチ分割をやってくれたりする。
-
tf.train.Estimatorに慣れていればコードを書き換えるのは難しくなさそう。 -
sess.run([train_op, log_op])なスタイルでやってた人は慣れる必要がある。- 自分はこっちだった。
- Estimatorを使うのが最近の標準っぽいので良い機会なので乗り換えよう。
- TPUEstimatorを使わないでCloud TPUを動かすのも可能らしい。
- その場合は低レベルAPIを駆使する必要がある。
- ノードをまたいだ処理(Batch Normalizationのノード間のシンクロなど)やイテレーションをまたいだ処理(複数回の勾配計算をまとめてパラメータに適用など)にチャレンジする時に必要になってきそう。
ResNet50の学習をしてみた
- 公式ドキュメントの Training ResNet on Cloud TPU | Cloud TPU | Google Cloud を実行した。
- ミニバッチサイズ1024で90エポック、ダミーデータを使用しているのでわかるのは速度のみ。
-
resnet_main.pyにおいて浮動小数点数の精度がbfloat16とfloat32選択できて今回はデフォルトのbfloat16を使用している。つまり半精度での計算。
結果
- 11時間で学習を終えた。
- 1エポックは4分程度で終わるので学習にかかる処理は6時間程度。
- 1エポックごとにCPUでバリデーションを行っており時間がかかっている。またその際にTPUデバイスのセットアップなどの処理が走るためこれまた時間がかかる。
- 雑にミニバッチサイズ1024とか動くのは魅力。
GANの学習 (1/2)
- オレオレGANを学習してみる。画像サイズは128x128x3。
- 自宅のGTX1080ti(11GB memory) x2だとミニバッチサイズは16 per GPUで32が限界だった。
- Cloud TPU v2ではper TPU coreは16でGPUと同じだがTPU coreが8つあるためミニバッチサイズ128で学習できる。
- モデルの詳細は省くが128x128サイズでも100イテレーションに58sec - 70secと高速に感じる。
Cloud TPU特有の実装
- 訓練方針の実装などにコツがいる(
tf.cond系が信用できない。後述) - GANの場合、トレーニング中も100イテレーションごととかに画像出力を確認したいのだけれどTPUEstimatorの
host_call(TPUコアでのイテレーションごとにホストのCPUで実行される関数)にコツがいる。 - また
host_callに画像を渡すこと自体がTPU-CPU間の通信が大きくなりパフォーマンスに良くないらしい。 - 自分は画像サイズ128x128x3のミニバッチサイズ128において32枚分の画像を
host_callに送っているがこれがどれだけ良くないのかはわからない。
GANの学習 (2/2)
性能の感想
- ともかく大きなバッチサイズと速さが使いやすい。
- コアあたりのバッチサイズが稼げないのでBatch Normalization(BN)が安定しているとは思えない。
-
Large Scale GAN Training for High Fidelity Natural Image Synthesis (BigGAN) ではTPU v3をクラスタで使っている。
やはりコアあたりのバッチサイズは小さいのだがコアごとのBNの統計をreduceする処理を自前で実装したとのこと。
データパラレルにおけるBNの問題は悩ましいのでreduceする実装が標準になってほしい。
なおオレオレGAN自体はいまでに成果が出ていない模様
注意点とか雑感とか
使用できるレイヤー・使用できないレイヤー
気になるレイヤー
- 画像生成系でよく使う
tf.resize_images()(tf.image.resize_bilinear()) がバイリニアかつalign_corners=Trueかつsizeがグラフ生成時点で決定していないといけないという制限には注意。- 知らないとハマる場所。
- GANでDを何回とかGを何回とかこうだったらこっちを訓練とかの訓練方針を制御するのによく使うcontrol-flow系(
tf.condやtf.case)がExperimentalなのに注意。- どれだけ不安定なのかよくわからないので使うのを敬遠してしまう。
- 訓練方針を制御したい時はglobal_stepを演算して特定回数でlossを0にするみたいなコードになる。
- その他、意外とサポートしてない関数があったりするので自然言語処理系の人やディープラーニングとはちょっと違う計算している人は注意が必要。
ここらへんは「いずれ充実するもの」と「コンセプト的にサポートされないもの」の2種類があると思う。
その他
TensorBoardの制限
- GANのところでも書いたとおりTensorBoardへの出力はTPUEstimatorの
host_callへ書くことになる。 - TPUで実行されるコード(モデル、ロス、オプティミゼーション)に
tf.summary系のオペレーションは書けない(書こうとするとエラーになる)。
Cloud TPUクライアントについて
-
ctpu upで作成されるクライアント(Google Compute Engine)のデフォルトのマシンタイプはn1-standard-2である。 - クライアントからTensorFlowプログラムを実行するとグラフの準備などに結構なメモリを消費する。
- 分類器くらいだと問題ないのですがGANのようにいくつもネットワークを作るようなプログラムだとメモリが足りずエラーになる。
-
ctpuのオプションで作成するマシンタイプを選択できるのでメモリエラーが出たら変えると良い。- 自分は
n1-highmem-2に変えた。
- 自分は
残りの注意点
だいたい 「TPUを使う時に気をつけること
」 が書いていてくれている。
profileが取れるのはとても便利なのだけれど自分の環境だと何度やっても trace_viewer だけ使えなかった。
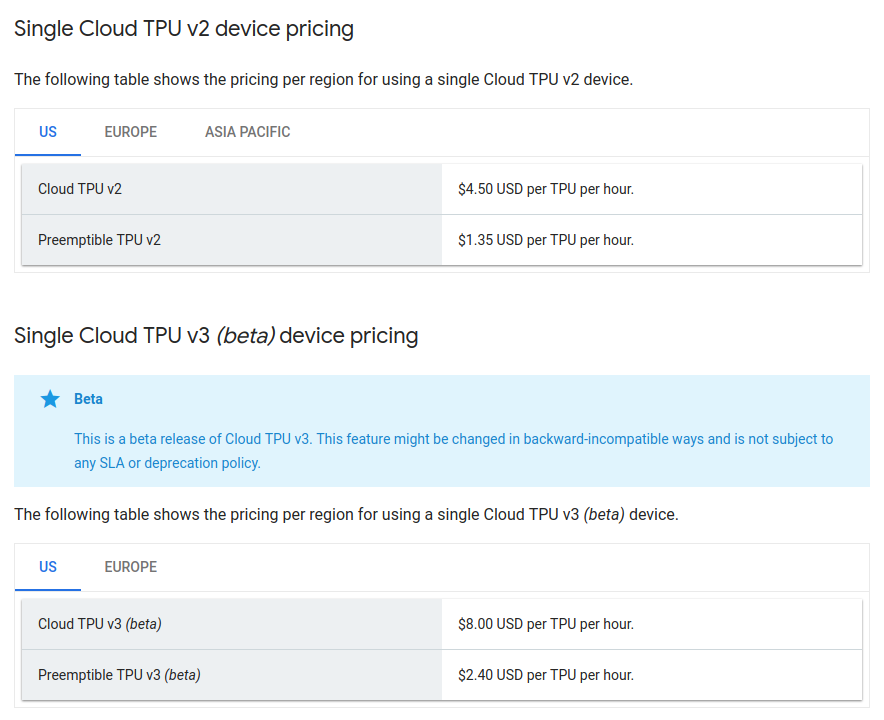
お値段 (1/2)
執筆時点でのUSでのお値段。
お値段 (2/2)
- Cloud TPUのホストの時間料金以外に主にクライアント(GCE)とGCSの料金がかかってくる。
- クライアントは(たまにメモリは食うが)それほどの性能はいらないしウェブサービスと違って計算していない場合は落としておける。
- GCSは気をつけないと結構料金を使うかも知れない。使用が終わったら必要のないデータは削除しておかないとストレージ料金が発生する。
- GCSのリードライトのオペレーションに対する料金
- 学習データのアップロードと学習済みモデルやTensorBoardファイルの読み出しで発生する。
- TPUホストと同一リージョンのバケットを使用するため学習中の読み書きによる料金は発生しない(と認識している)。
- TensorBoardをTPUクライアントで実行すればクライアントも同一リージョンであるため料金は発生しない(と認識している)。
雑感など
- プリエンプティブを使いこなせれば個人でも結構成果だせるかも?
- 簡単な分類問題であれば数時間で終わるため手法の有効性確認などで普段は使わないけど飛び道具的に使うのはアリ寄りのアリ。
- ちなみにASIAでCloud TPUのあるリージョンは台湾のみ。日本とはなんだったのか。
- 今回使ったのは us-central リージョン。GCSにデータを送る際に自宅の光回線で 10MB/sec で送信できたので基本的にはリージョンはあまり問題にならないと思う。
- sshでのクライアント接続は多少遅延を感じた
- もっと太い回線を持っている場合は主にGCSとのデータ送受信の関係でもっと近いリージョンが欲しくなると思う。
まとめ
- TPUEstimatorなら自宅で
tf.deviceを駆使してマルチGPUのコードを書くよりもかなりサボれる - 他のGPUクラウドもこれくらい楽にGPUクラスタのコードが書けると良い
- 現状マルチGPUのクラウドVPCを借りても分散コードは自分で書かないといけないと認識している
- そのためにはTensorFlowではTPUEstimatorとそのバックエンドのGPU版が出てくることを期待したい(もうある?
- GANだとTPU v2だとコアあたりのメモリが足りないのでTPU v3を使いたくなる(なお収入
- 一生Cloud TPU沼にハマっていたい(なお収入