前回 勝敗予測モデル2エポック目の成績報告とDNNの種々考察(ポエム回) : TensorFlow将棋ソフト開発日誌 #9
目次 TensorFlow将棋ソフト開発日誌 目次
ソースはgithubにあります(俺が読めればいいというレベル)
EC2であり金溶かした人の顔してる
今回の話題
- 勝敗予想モデルの学習をAWS EC2 p2.8xlargeで行ってみた
- パフォーマンスを確保するためにはいろいろと考えないといけないことがわかった
- 今後の方針
AWS EC2 p2.8xlarge
最近Amazonが米国リージョンで提供を開始したGPUを搭載したEC2インスタンスです。
参考 : Amazon EC2 P2 インスタンス
- CPU : Intel Xeon CPU E5-2686 v4 @ 2.30GHz (32core)
- GPU : nVidia K80 x4(8gpu core)
- memory : 488GB
- 料金 : $7.2 / hour
16gpu coreが使用できるp2.16xlargeというインスタンスもありますが「AWS EC2 p2.16xlarge でCUDAを使用する際に16GPUは同時に使用できない」に書いた理由により使用を見送りました。
なぜマルチGPUを欲するのか
ありていにいうと1エポック分の学習サンプルを全て消化するのに必要な時間を減らしたいからです。現在のところ自宅のマシンでは23時間強かかっていて設計、学習、検証のサイクルをこなしづらくなっています。また勝敗予想から指す手の決定まで一通りのソフトウェアができた後に必要な学習回数(対局回数)は少なく見積もっても10万対局のオーダーになると考えられるため現在の自宅のマシン(GTX 1080 1枚)では足りないからです。
学習方法、トラブル、途中経過と処理時間(途中)
モデルは前回までと同じ構造のものを使用しました。マルチGPUでの学習のためのプログラム改修はTensorFlowのチュートリアルの「Convolutional Neural Networks」を参考にほぼほぼ同じようなコードにしました。つまりデータ並列です。
ミニバッチサイズと学習の効率、GPUパフォーマンスの問題
はじめに動かした時、シングルGPUの時と同じ設定としてモデル上のミニバッチのサイズ(サンプル数)を100としていました。つまり1回のイテレーションで8GPUが合計800のサンプルを学習します。その設定でロスの低下を観察していたところサンプルの消化数に対してロスの低下が(1GPUの時と比べて)悪いという現象が見られました。
『機械学習プロフェッショナルシリーズ 深層学習』からの引用。
なお,ミニバッチのサイズをあまり大きくすることは,確率的勾配降下法のよさを損なうことになり,あまり良くありません.サイズを大きくすると,ミニバッチ間で計算される勾配のばらつきが小さくなり,wの更新量が安定するので,学習係数εを大きくでき,それだけ学習が速く進む効果があります.しかし一般に,ミニバッチのサイズをN倍しても,εをN倍にまで大きくすることはできないので,トータルの計算速度(単位時間あたりの更新回数)は逆に低下してしまいます。
今回AdamOptimizerの学習係数は変更していないため安定した勾配に対して小さな更新量で学習を行っていたためイテレーションに対するロスの低下が悪いということになったのだと思います。
次に各GPUが計算するミニバッチの大きさを6として1イテレーションで合計48サンプルを学習するようにしてみました。しかし今度はGPUの計算が早く終わってしまいCPUでの勾配の集計更新処理に律速するようになり単位時間あたりのサンプルの消化数が低下してしまいました(つまり学習ソフトウェアとしての速度が落ちた)。
現在はGPUごとのミニバッチサイズを20にして1イテレーション合計160サンプルを学習するように実験しています。これでもGPUの稼働率が100%に張り付いていないため8GPUを十分に活かせていない状況です。
学習の途中経過
これを書いている時点で学習が終わっていないため途中経過となりますがTensorFlowの画像を並べていきます。
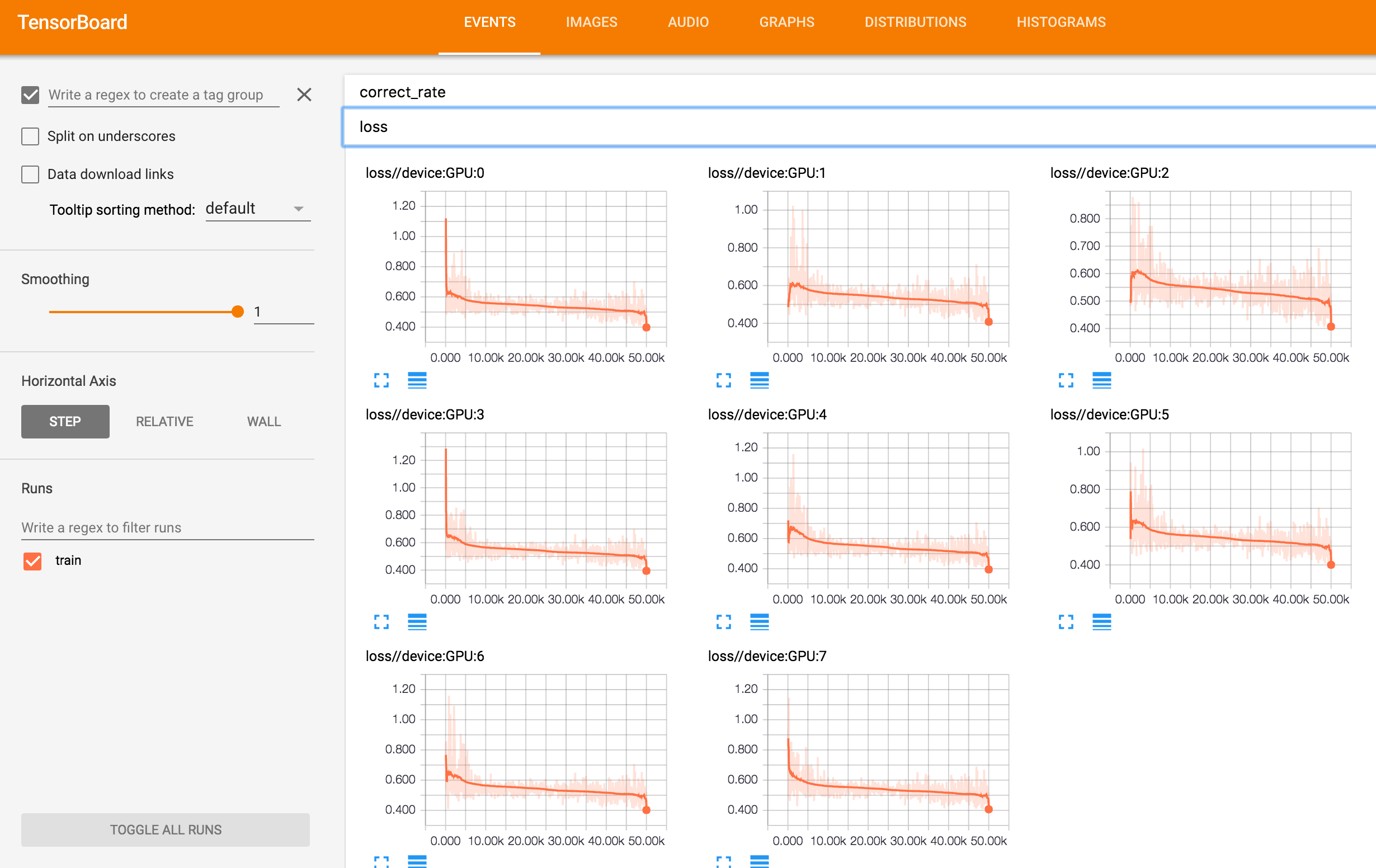
ロスの推移の画像です。GPUごとに表示しています。
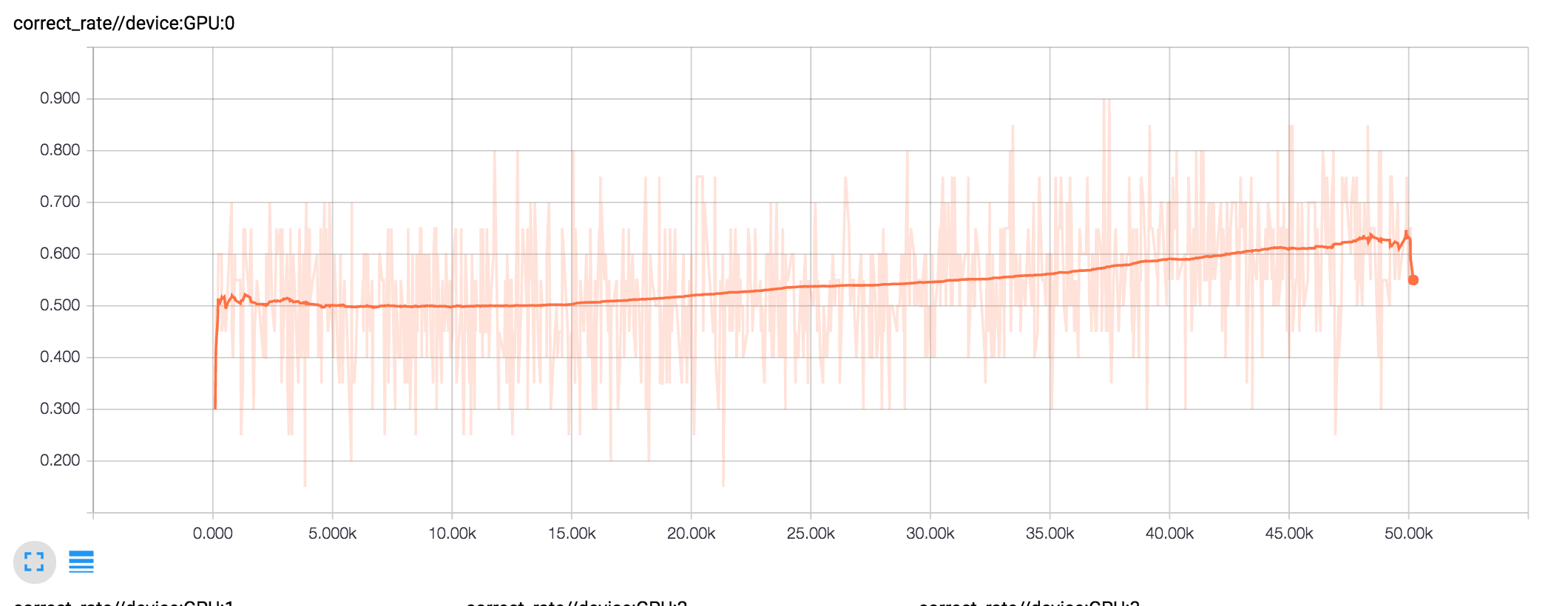
学習サンプル正答率の推移の画像です。こちらもGPUごとに表示しています。
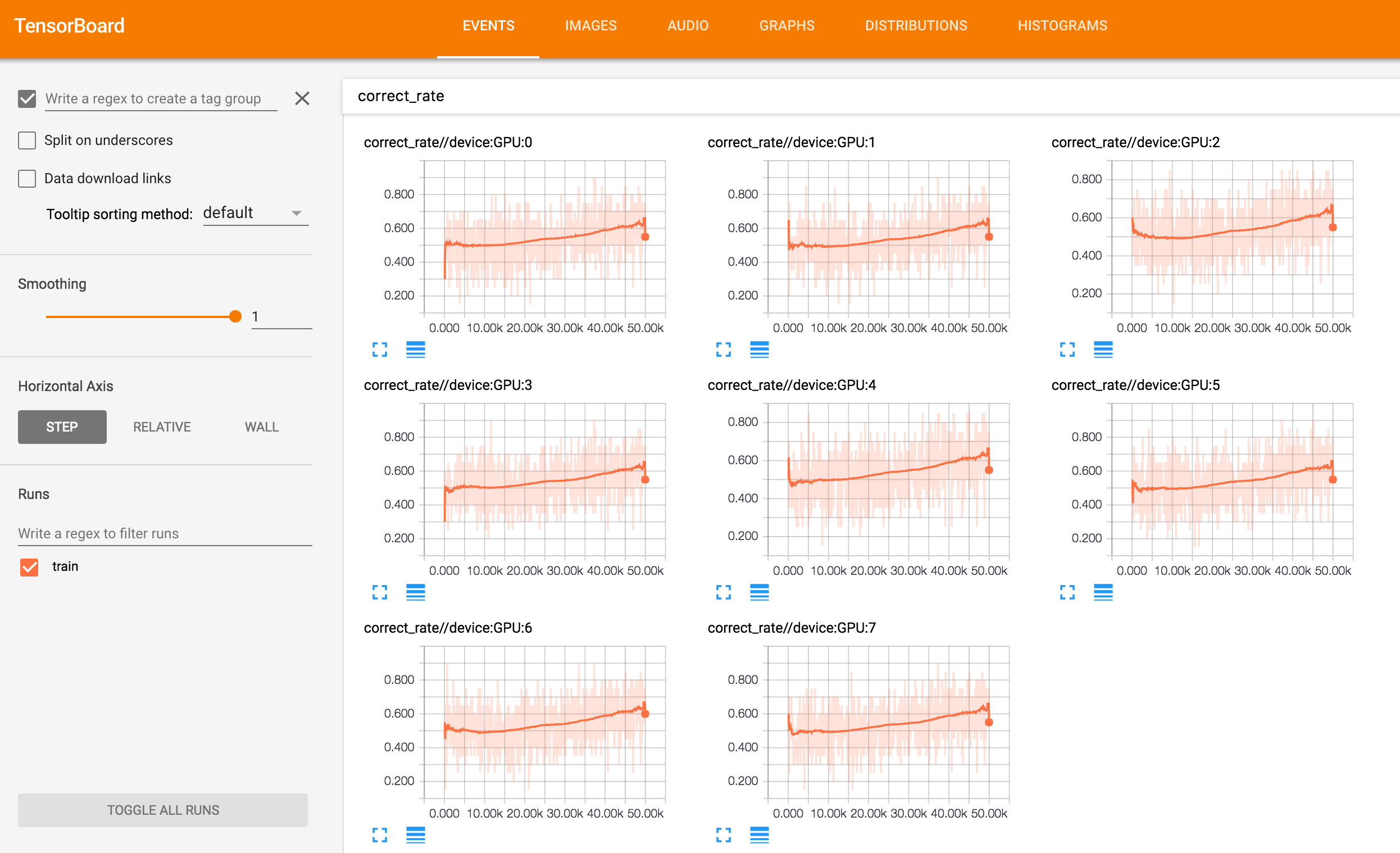
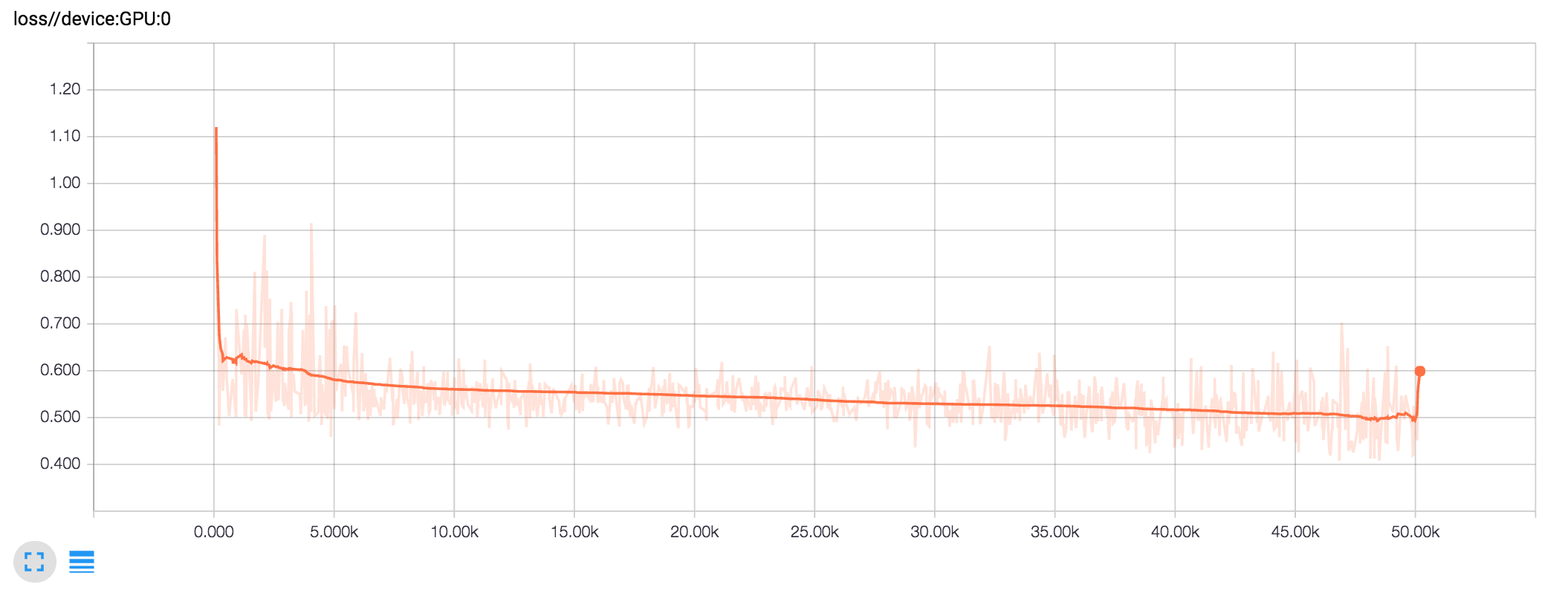
/GPU:0 についてロスの推移と学習サンプルの正答率の推移を並べます。TensorFlow将棋ソフト開発日誌 #7のグラフと比べてみてシングルGPUの頃と同じような学習が実現できていることが確認できます。シングルGPUではミニバッチサイズ100、マルチGPUではミニバッチサイズ160なのでイテレーションに対するロスは比較できませんが消化サンプルに対するロスはだいたい同じ感じになっています。
マルチGPUでパフォーマンスを確保するためには
ここでマルチGPUを活用するにあたっての問題が発生します。
- ミニバッチのサイズを大きくすれば各GPUの稼働率は上がり時間あたりの学習サンプル消化数も向上するがサンプル消化数に対する学習の効率は下がる
- ミニバッチサイズを小さくするとイテレーションごとのGPUの計算時間が低下しCPU律速になり時間効率が低下する
ではどうするかというと「モデルを大規模化・複雑化してGPUの計算時間を上昇させ同一計算時間、同一消化サンプル数に対するモデルの性能の向上を目指す」というのが正しいアプローチのように思えます。もともと使っているのがひどく適当なモデルであるので指し手モデルの運用まで一区切りができたらモデルの複雑化に着手する予定です。
しかし上の方法だと結局時間あたりの学習サンプル消化数が向上しません。時間あたりの学習サンプル消化数を向上させるには以下が必要なのかなと考えています。
- 単体のGPUコアの性能を向上させる
- CPUの性能を向上させ集計処理での律速を緩和する
- データ並列におけるCPU上での集計処理に代わるアーキテクチャ的なアプローチを考える
学習プログラムを1回終わらせるのに必要な時間が大きいという問題については学習サンプルを複数のグループに分割して段階的に実行することで対処していこうと思います。
まとめ
今回得た発見をまとめると以下のようになります
- マルチGPU化するときのミニバッチのサイズには気をつけよう
- データ並列において各GPUの計算時間をそれなりに大きくしておかないとCPU律速になってしまいGPU本来のパフォーマンスを得られない
- そのためにはモデルの大規模化・複雑化が必要なので小さな問題、練習的なモデルではマルチGPUの恩恵はあまり得られない
今後の予定
現在のモデルでミニバッチサイズ20だとGPUの稼働率を確保できない(nvidia-smiを監視して感覚的に70%くらい)ためしばらくp2インスタンスの使用はやめます。ここまででだいたい5万円くらい溶かしているので(あとちょっとでGTX 1080が1枚買える値段!)。
Amazon AWSが現在唯一正式サービスとしてGPUインスタンスを時間貸しで提供しています。さくらインターネット、Microsoft Azureは予告、プレビューの段階です。年末から来年頭くらいにかけて盛り上がってくるとは思いますが個人の趣味の利用では自前でマルチGPUマシンを組んだ方が良いのかなーという気がします。特にほとんどのインスタンスがK80かそれに近いGPUなのでうまくパフォーマンスを得つつ費用対効果を得るのには技術が必要になると思います。ここら辺の話はいずれまとめたいと思います。
自分もクラウドではなくマルチGPUマシンを組む方向でいこうと思います。GTX 1080のメモリが8GBなのがネックでそれ以上のGPUは値段や発熱のハードルがあるのが悩みどころ。貯金をしながら最適解を探します。
直近の作業としては勝敗予測モデルを自宅マシンでのんびり学習しながらいよいよ指し手モデル(どこに駒を指すのか候補を挙げるモデル)を作っていきます。
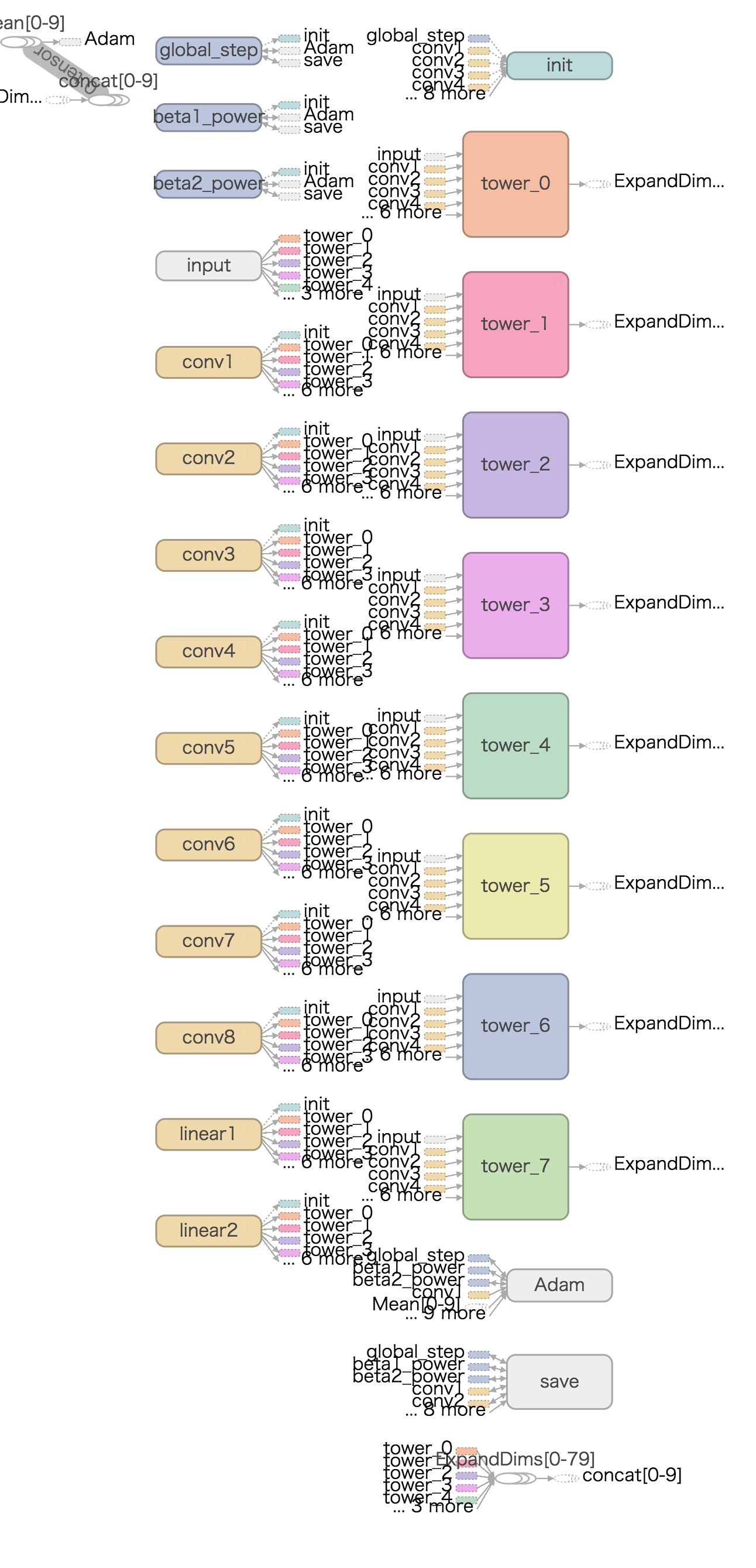
おまけ : マルチGPUでのTensorBoardのグラフ出力
モデルのコーディングが意図通りになっているかを確認するのに便利なTensorBoardのグラフ出力。マルチGPUだと以下のような感じになります。左に縦一列で並んでいるのがモデルの変数(重みなど)、右に縦一列に並んでいるのがGPUがそれぞれ持っている変数(勾配計算のための変数、各GPUごとにグループ化されて表示されています)。グループごとの色分け、割りふりデバイスごとの色分けが切り替えられたりして「モデルを書いてみたけど正しく解釈されてるかな?」って確認したい時に大変便利で重宝します。