はじめに
今回私は最近はやりのchatGPTに興味を持ち、深層学習について学んでみたいと思い立ちました!
深層学習といえばPythonということなので、最終的にはPythonを使って深層学習ができるとこまでコツコツと学習していくことにしました。
ただ、勉強するだけではなく少しでもアウトプットをしようということで、備忘録として学習した内容をまとめていこうと思います。
この記事が少しでも誰かの糧になることを願っております!
※投稿主の環境はWindowsなのでMacの方は多少違う部分が出てくると思いますが、ご了承ください。
最初の記事:Python初心者の備忘録 #01
前の記事:Python初心者の備忘録 #17 ~機械学習入門編03~
次の記事:Python初心者の備忘録 #19 ~機械学習入門編05~
今回はロジスティック回帰についてまとめております。
■学習に使用している資料
Udemy:【後編】米国データサイエンティストがやさしく教える機械学習超入門【Pythonで実践】
■分類/識別(Classification)
- 目的変数が質的変数(あり/なし、東西南北など)になる(回帰では目的変数は量的変数)
- 分類タスクでは、決定境界を作ってデータを分類することを目的とする
- 決定境界を引く機械学習モデルを分類器(classifier)という
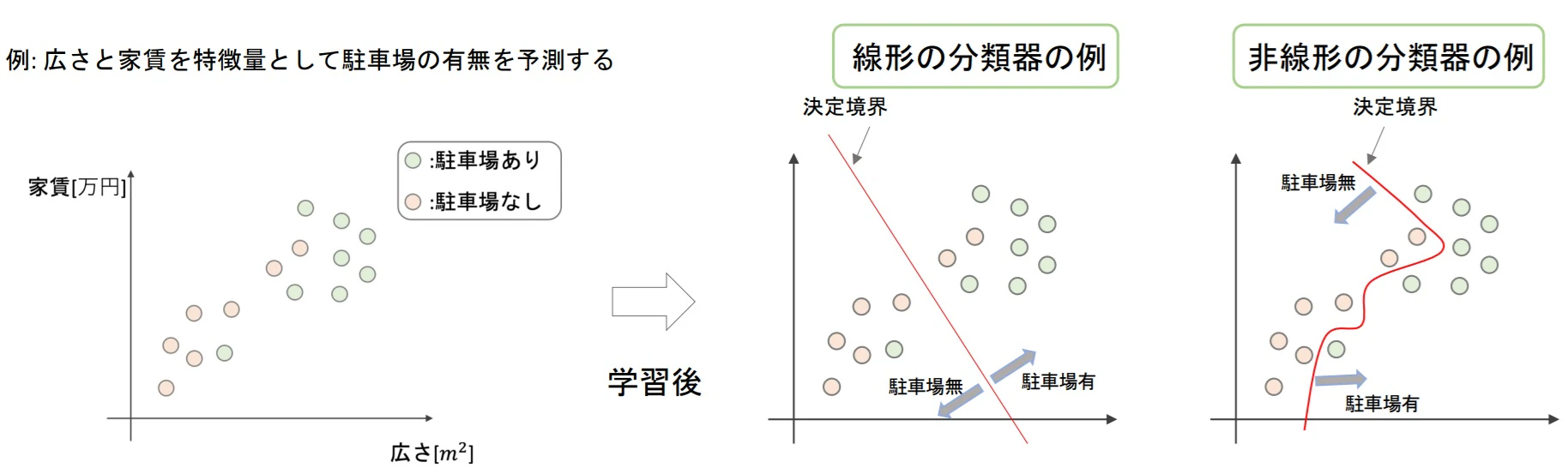
▶分類アルゴリズム
- 目的変数を0/1の2値で扱う
- 回帰では予測値が0~1を超えてしまい解釈できないため、そのまま使えない
- 多クラスの場合は0,1,2,...のように単純に数値化して量的変数のようにすることはできない
→ それぞれの質的変数に量的な差はないため(北から2離れていると南というようなことはない) - 回帰を使用すると外れ値一つで大きく結果が変わってしまう
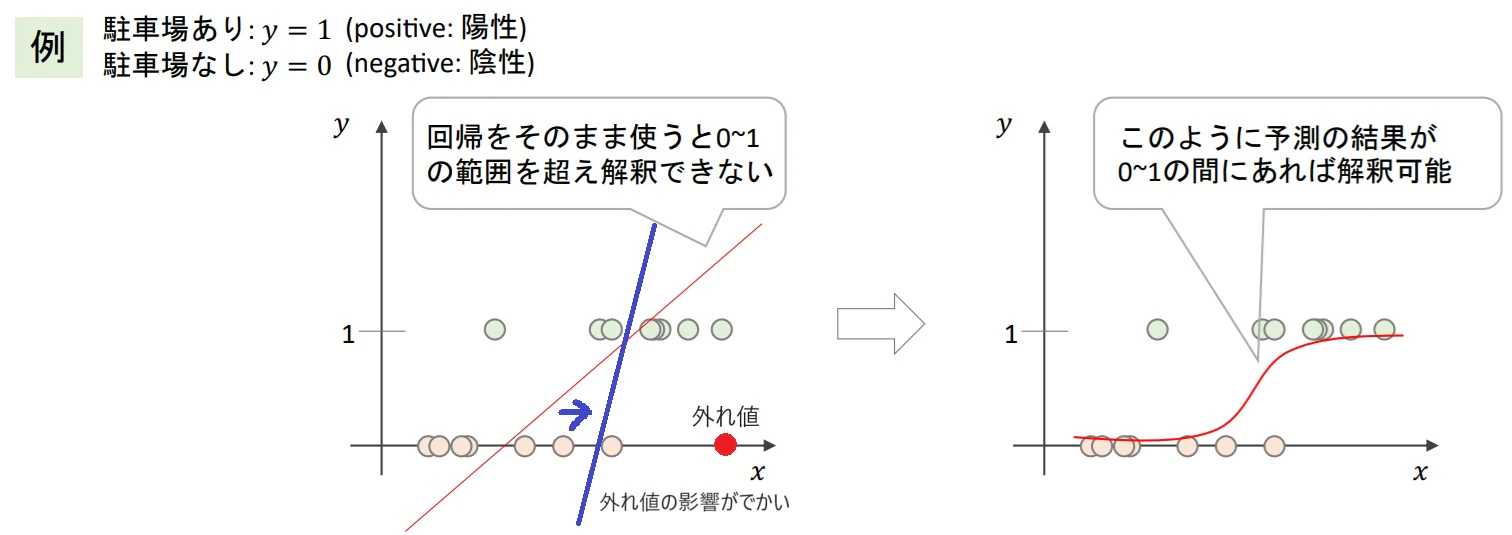
■ロジスティック回帰
- 分類アルゴリズムの最も基本のアルゴリズムで"回帰"とついているが回帰ではなく分類アルゴリズム
- シグモイド関数を使って、どんなXに対しても予測値が0~1に収まるモデルを作成する
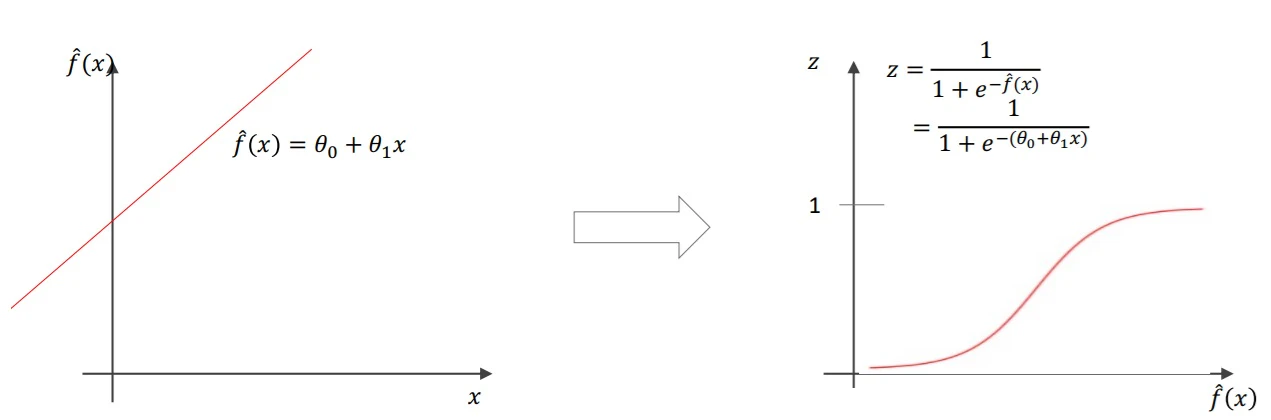
▶シグモイド関数(ロジスティック関数)
- シグモイド関数:$z=\frac{1}{1+e^{-x}}$
- シグモイド関数の$x$に線形回帰の$\hat{f}(x)=\theta_0+\theta_1x$を代入することで、回帰を0~1の間に収める
→ $p(x)=\frac{1}{1+e^{-(\theta_0+\theta_1x)}}$:ロジスティック回帰の数式モデル
$p(x)$は0~1の間しかとらないので、確率として扱う(考える)ことができる
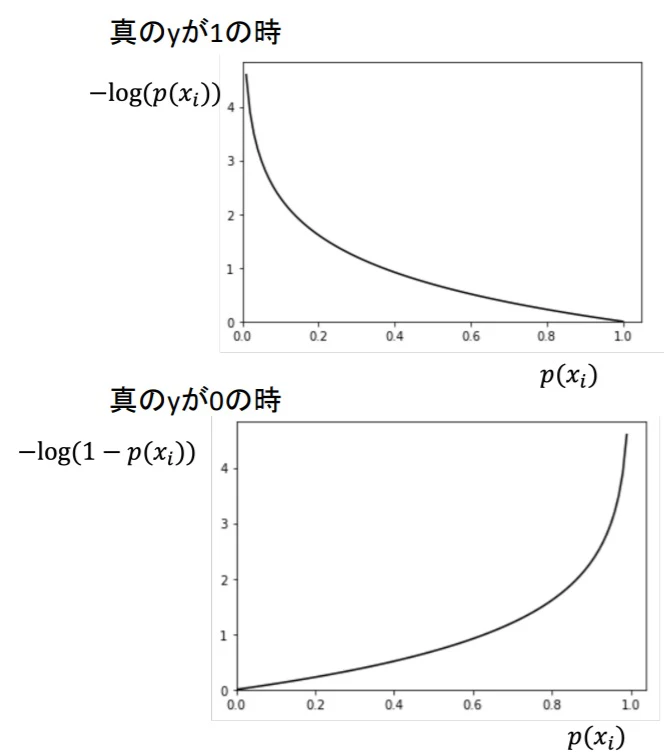
▶ロジスティック回帰の損失関数
- $\theta$を求めるための損失関数が必要
- 最小二乗法では複雑になりすぎるので、LogLoss(交差エントロピー:cross entropy)を使用する
\text{Cost(p(x_i), y_i)=}
\left\{
\begin{array}
\text{-log(p(x_i)) \hspace{1cm} y_i=1} \\
{-log(1-p(x_i)) \hspace{1cm} y_i=0}
\end{array}
\right.
→ 一つの式で表すことも可能
Cost(p(x_i), y_i)=-y_ilog(p(x_i)+(1-y_i)log(1-p(x_i))
→ 損失関数:全データで平均を取る
L(\theta)=\frac{1}{m}\sum_{i=1}^mCost(p(x_i), y_i)=-\frac{1}{m}\sum_{i=1}^m\{y_ilog(p(x_i)+(1-y_i)log(1-p(x_i))\}
→ 最急降下法で最適化
▶Pythonでロジスティック回帰
sklearnのLogisticRegressionはデフォルトではl2ノルムが適用されています。
正則化項を使用する場合は,事前に標準化(StandardScaler)の処理をするのが一般的です。
本記事において標準化の処理を飛ばしている場合がありますが、正則化項を使用する場合や、特徴量間のスケールが大きく異なる場合は事前に標準化をするようにしてください。
ロジスティック回帰
-
sklearn_.linear_model.LogisticRegressionモジュールを使用
→使い方は他モデル同様
引数
- penalty(正則化項):'l1'、'l2'、'elasticnet'、'none'
- solver(使用する最適化問題の手法):'newton-cg'、'lbfgs'、'liblinear'、'sag'、'saga'
- multi_class(多クラス問題用):'ovr'、'auto'、'multinormal' -
.predict(X)でラベル(クラス)の分類結果を取得 -
.predict_proba(X)でラベル(クラス)の確率p(X)を取得
# 学習データとテストデータ作成作成
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import log_loss
# titanicデータロード
df = sns.load_dataset('titanic')
df = df.dropna()
df.head()
# 学習データとテストデータ作成作成
X = df.loc[:, (df.columns!='survived') & (df.columns!='alive')]
X = pd.get_dummies(X, drop_first=True)
y = df['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# ロジスティック回帰
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)
# 損失関数を出してモデルの評価
log_loss(y_test, y_pred_proba) # -> 0.41115706293648924
※上記のモデル評価の値が良くなるようにpenaltyやsolverを調節する
■多クラス分類のロジスティック回帰
ロジスティック回帰を多クラスに適用する手法は大きく分けて2つに分類できる。
- One vs Rest(OvR)
- 多項ロジスティック回帰(Multinomial logistic regression)
※OvRと多項ロジスティック回帰では結果が異なるということに注意する
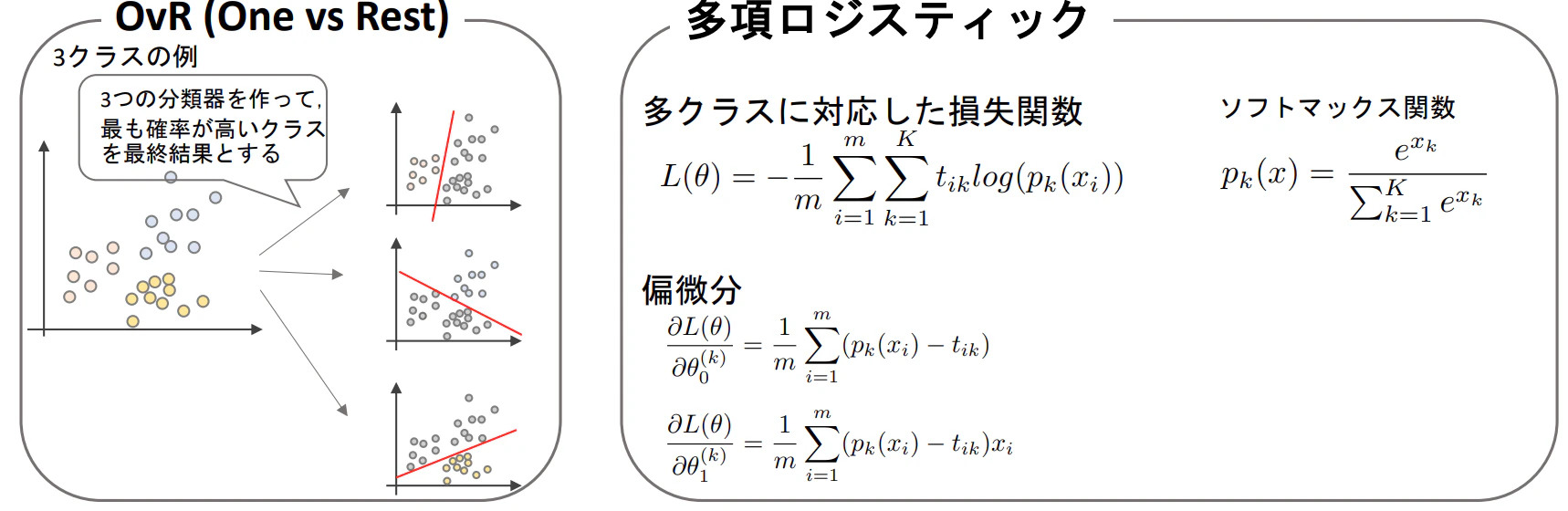
▶One vs Rest(OvR)
- クラスの数だけ分類器を作成し、最も確率が高いクラスを最終的な分類結果とする方法
- ロジスティック回帰のみならず、他のモデルでも使われる手法
- データ数が多かったり、モデルの構築にコストがかかる場合は△
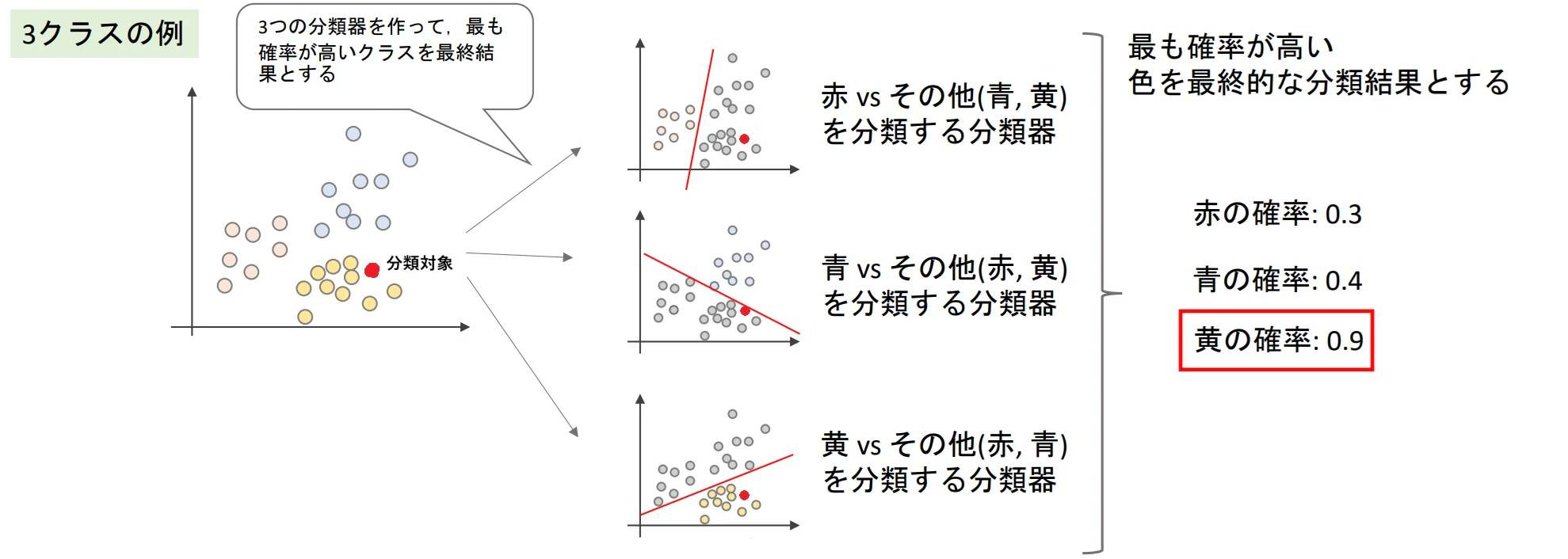
▶多項ロジスティック回帰
- 2値分類用の損失関数を多クラス対応させたもので、一度の学習で多クラスに対応するモデルを構築可能
- 主に下記操作を行う必要がある
- 目的変数のエンコーディング:[赤、青、黄 ⇒ 0、1、2]とはできないので
- シグモイド関数 ⇒ ソフトマックス関数
- 損失関数の多クラス対応:0、1で判断できないので、普通の損失関数は使えない
▶目的変数のエンコーディング
- 2値分類と同様に、目的変数を0,1,2...というようにラベル付けするわけではない
- 単純に数値化できないので、one-hotエンコーディングを行う
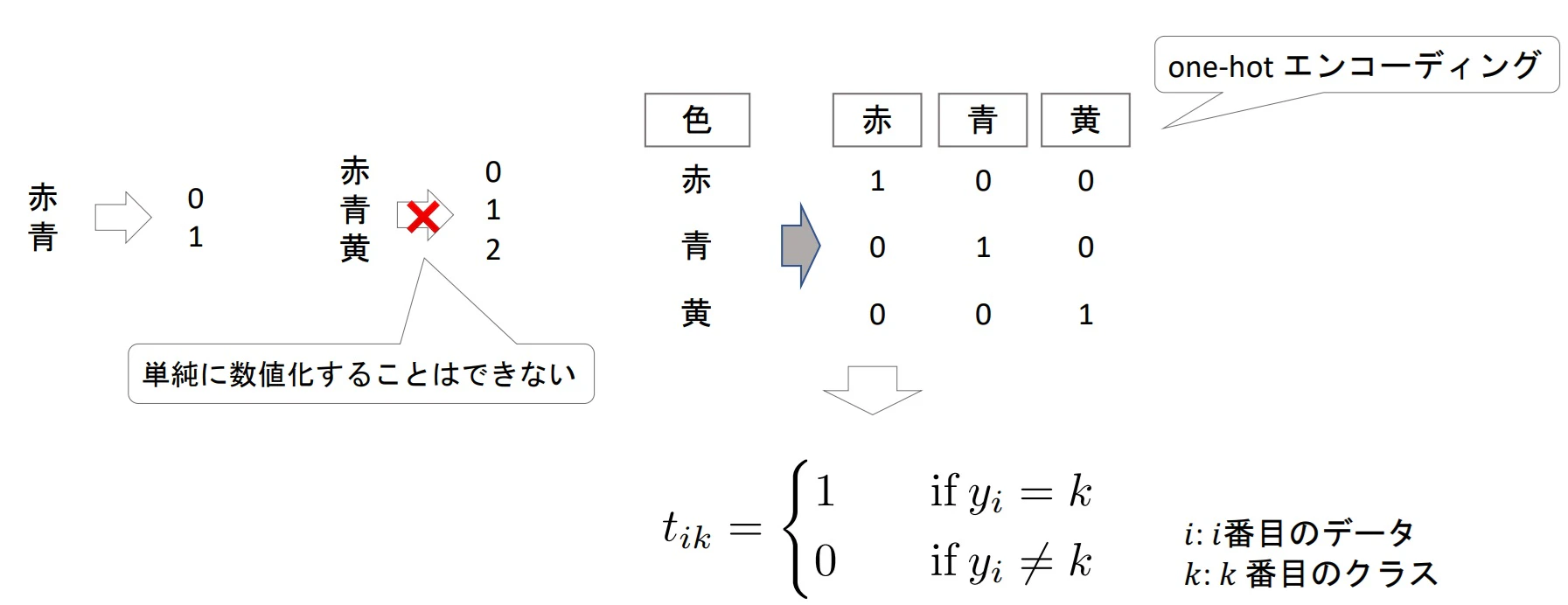
例えば、赤=1、青=2、黄=3とすると下記のようになる
$t_{11}=1、t_{12}=0、t_{13}=0$
$t_{21}=0、t_{22}=1、t_{23}=0$
$t_{31}=0、t_{32}=0、t_{33}=1$
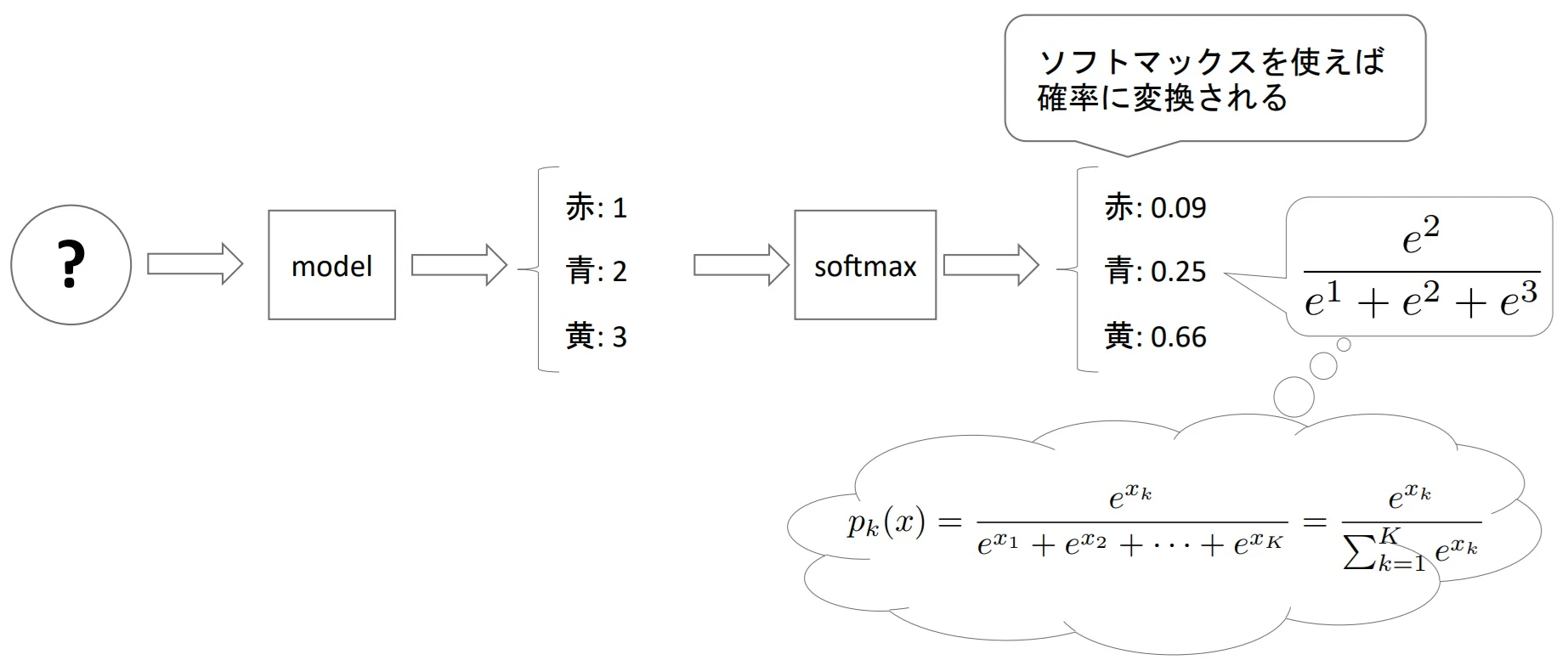
▶ソフトマックス関数(softmax function)
- シグモイド関数を一般化したもの(→ シグモイド関数はソフトマックス関数の一つ)
★今までのシグモイド関数はpositive(1になる)場合しか考えていなかった。($x_2=0$)
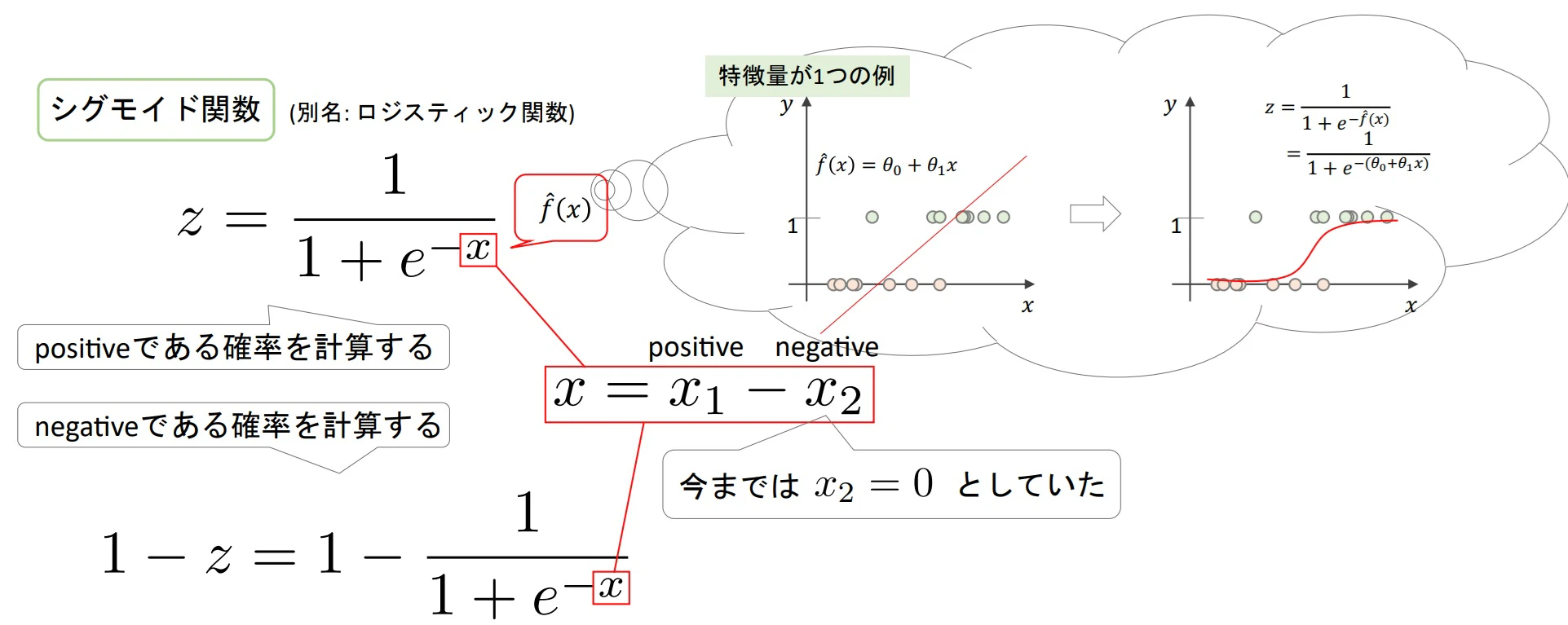
★$x$を正確に表した場合、positiveとnegativeの式はそれぞれ下記のように表せる。
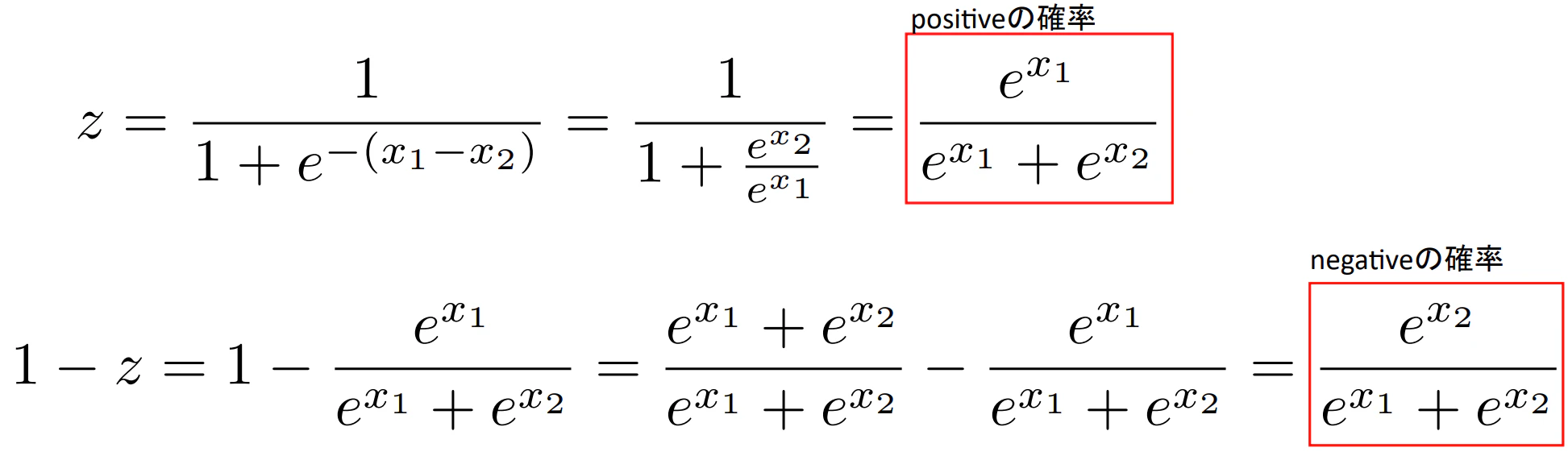
★上記の式を一般化し、多クラスに対応するように記載すると次のようになる

- ソフトマックス関数は入力値を標準化し、確率の形(足すと1)にする
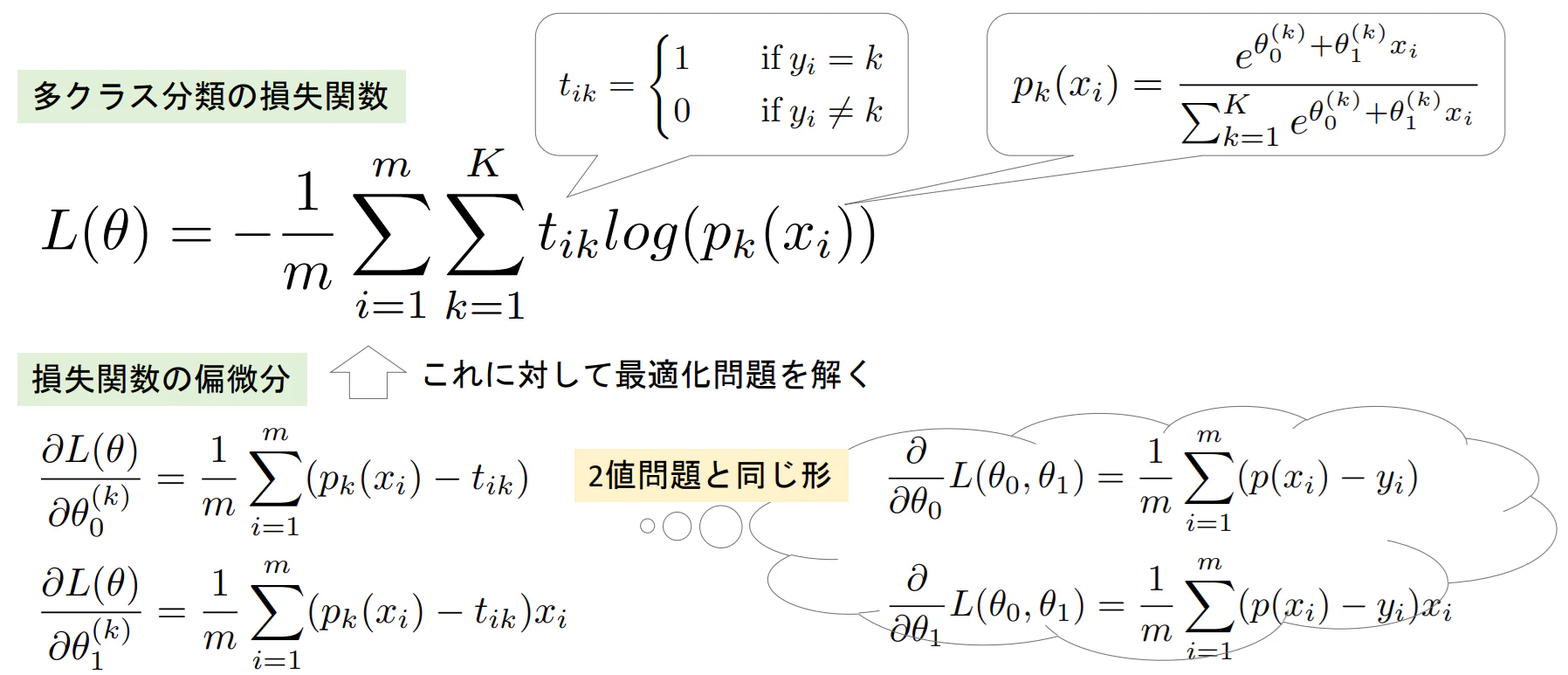
▶多項ロジスティック回帰の損失関数
- 損失関数を多クラス対応できるように一般化する
→ $Cost(p_k(x_i),t_{ik})=-t_{ik}log(p_k(x_i))$
※正解ラベル以外の出力結果は損失としてカウントしない(2値分類と同様)

★正解ラベル(赤:$t_{i1}$)は1、それ以外(青:$t_{i2}$、黄:$t_{i3}$)は0となる。
- 全データの損失の平均や合計を損失関数とする
▶Pythonで多項ロジスティック回帰
-
sklearn.linear_model.LogisticRegressionクラスを使用する -
multi_classにauto、ovr、multinomialのいずれかを指定する。
-auto:solver="liblinear"、もしくはsolver="ovr"(2値分類の場合)となる。それ以外はmultinomialになる
-ovr:One vs Rest
-multinomial:多項ロジスティック回帰
# データ準備
import seaborn as sns
df = sns.load_dataset('iris')
df.head()
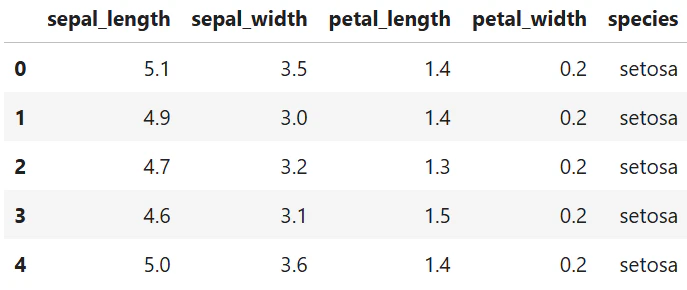
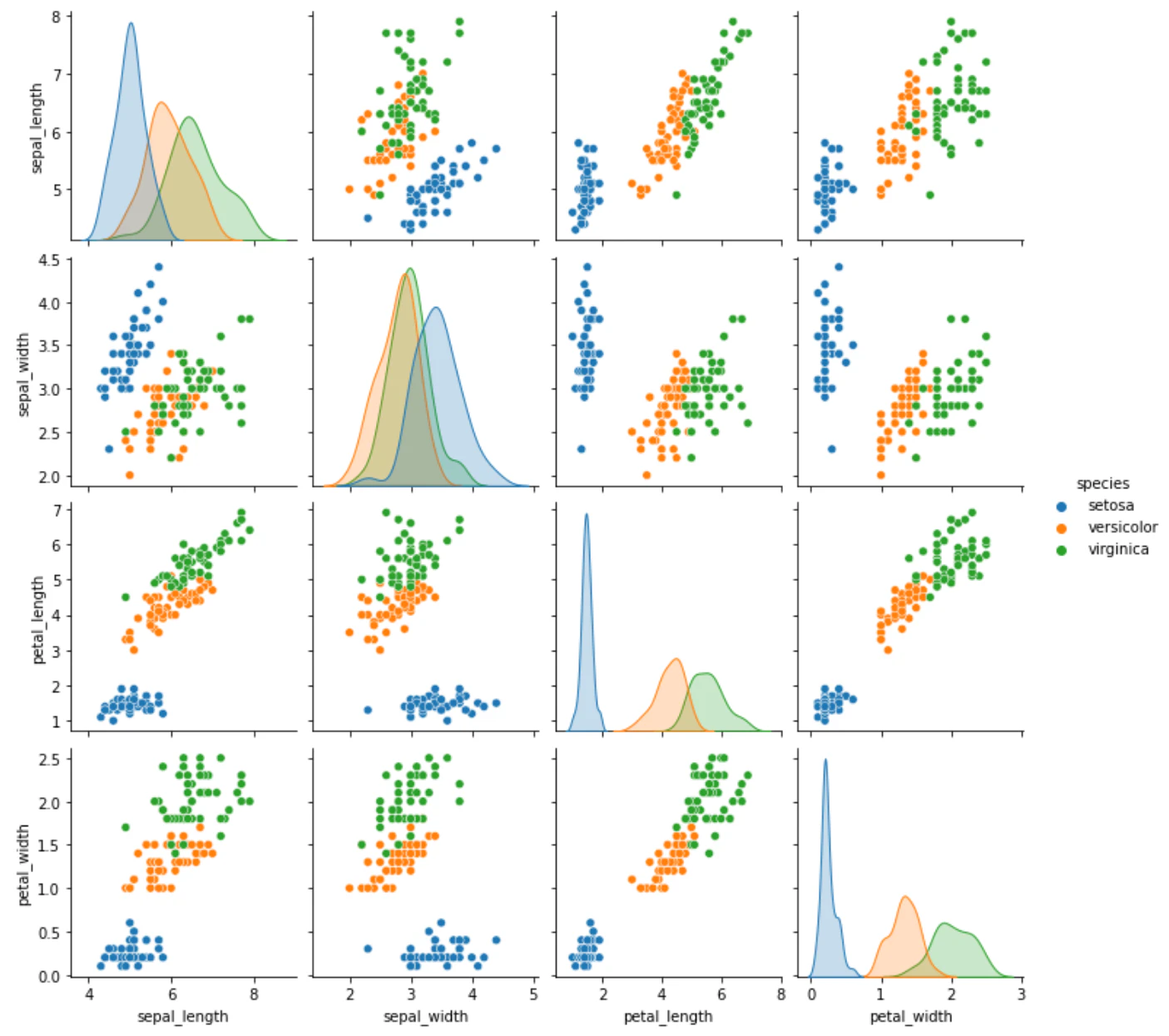
※花の種類とその花びらやがく弁の大きさを記録したデータ
# 目的変数がとりうる値を確認
df['species'].unique() # -> array(['setosa', 'versicolor', 'virginica'], dtype=object)
# データの分布描画
sns.pairplot(df, hue='species')
# 学習データとテストデータ作成
from sklearn.model_selection import train_test_split
y_col = 'species'
X = df.loc[:, df.columns!=y_col]
y = df[y_col]
# 学習データ70%、テストデータ30%に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
print(len(X_train), len(X_test))
OvR
# 学習
model = LogisticRegression(penalty='none', multi_class='ovr')
model.fit(X_train, y_train)
# それぞれの該当するクラスの確率
y_pred_ovr = model.predict_proba(X_test)
# 結果表示
print(model.classes_)
print(model.intercept_)
print(model.coef_)
// それぞれのクラス
['setosa' 'versicolor' 'virginica']
// 0番目の特徴量(切片)
[ 1.11952961 6.81324426 -255.99667973]
// それぞれの特徴量の係数
[[ 1.91635746e+00 6.80805390e+00 -1.08014054e+01 -5.01387880e+00]
[-4.15059756e-01 -2.43651049e+00 1.48863127e+00 -3.08728666e+00]
[-3.59713655e+02 -2.82241847e+02 5.44953421e+02 3.64284106e+02]]
multinomial
# 学習
model = LogisticRegression(penalty='none', multi_class='multinomial')
model.fit(X_train, y_train)
# それぞれの該当するクラスの確率
y_pred_mn = model.predict_proba(X_test)
# 結果表示
print(model.classes_)
print(model.intercept_)
print(model.coef_)
// それぞれのクラス
['setosa' 'versicolor' 'virginica']
// 0番目の特徴量(切片)
[ 80.23761246 129.79119848 -210.02881094]
// それぞれの特徴量の係数
[[ 155.59729865 358.73830851 -523.93809233 -248.11590998]
[ 118.20297971 -15.08081946 -41.54669676 -91.11017728]
[-273.80027837 -343.65748906 565.4847891 339.22608726]]
# OvRとmultinomialの結果比較
y_pred_ovr[:10]
y_pred_mn[:10]
// OvR
array([[2.52308411e-016, 8.82201826e-002, 9.11779817e-001],
[1.28141183e-009, 9.99999999e-001, 5.98425053e-214],
[9.85945513e-001, 1.40544866e-002, 0.00000000e+000],
[2.82376791e-019, 3.87069863e-001, 6.12930137e-001],
[8.87568928e-001, 1.12431072e-001, 0.00000000e+000],
[7.38900210e-019, 6.30771165e-002, 9.36922884e-001],
[9.44848969e-001, 5.51510306e-002, 0.00000000e+000],
[3.42654652e-010, 1.00000000e+000, 2.70303587e-188],
[1.45180559e-011, 1.00000000e+000, 1.29140522e-159],
[4.98401002e-008, 9.99999950e-001, 2.86460698e-255]])
// multinomial
array([[0.00000000e+000, 3.17563442e-259, 1.00000000e+000],
[0.00000000e+000, 1.00000000e+000, 2.66330941e-242],
[1.00000000e+000, 0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 8.28135131e-194, 1.00000000e+000],
[1.00000000e+000, 1.68095575e-284, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000, 1.00000000e+000],
[1.00000000e+000, 0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 1.00000000e+000, 6.49417604e-212],
[0.00000000e+000, 1.00000000e+000, 1.86863800e-178],
[0.00000000e+000, 1.00000000e+000, 7.06830464e-289]])