【RAG入門・Python実装】
第1回:LLMとは?仕組みと課題をわかりやすく解説
はじめに
このシリーズでは「RAGをPythonで実装する」ことを最終ゴールとします。
今回は、その基盤となるLLM(大規模言語モデル)について整理します。
「LLMってよく聞くけど仕組みがいまいちわからない」という方に向けて、なるべくやさしく解説します。
LLM(大規模言語モデル)とは?
大量のテキストデータを学習させることで人間のような自然な言語を理解し、生成できるAIモデルのことである。
LLM(大規模言語モデル)の仕組み
インターネット上の膨大なテキストデータ(書籍、記事、ウェブサイトなど)を読み込ませる。このデータからある単語の次にどの単語が来るかを確率統計的に分析し、モデル化。
(例)「私の職業は」の後は「医者」、「教師」などの単語が高い確率で来る。逆に「机」「学校」などの単語は低い確率で来る。
LLM(大規模言語モデル)の活用事例
- GPTシリーズ(OpenAI)
- Gemini(Google)
- Claude(Anthropic)
- Llama(Meta)
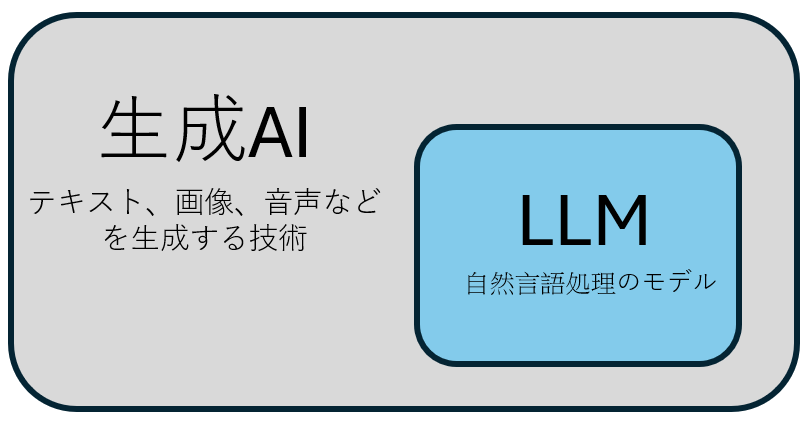
LLMと生成AIの違い
LLMと生成AIはどちらもAIの一種である。生成AIとはテキストや音声、画像、動画などを自立的に生成できるAI技術の総称。一方、LLMは自然言語処理に特化したAIであり、膨大なテキストデータを学習することで、より高度な言語理解を実現。
LLM(大規模言語モデル)の課題
- ハルシネーション
間違った情報や文脈と関係のない事を出力してしまう現象
(例)フェイク情報拡散の危険
- 「プロンプトインジェクション」
悪意のあるユーザーが巧妙なプロンプト文でLLMに本来は禁止されている
出力をさせること (例) 企業の秘密情報や第三者の個人情報が開示
「ハルシネーション」はなぜ起こるのか
学習済みのデータに基づいた知識しか持っていないため、学習データに含まれていない最新の情報や、特定の企業内部の機密情報に関する質問には、正確に答えるのがむずかしいからだ。
まとめ
- LLMは「次の単語を予測する超強力な言語モデル」
- 便利だが、知識更新や正確性に弱点がある
👉 次回は、その弱点を補う「RAG」の仕組みを解説!