🚀 はじめに
最近、LLM(大規模言語モデル)の進歩が目覚ましいですが、同時に SLM(小規模言語モデル) の進化も見逃せません。
「巨大なモデルをクラウドで」だけでなく、「賢い軽量モデルをローカルで」動かす可能性を探るべく、自宅のゲーミングPCでどこまで戦えるか検証してみました。
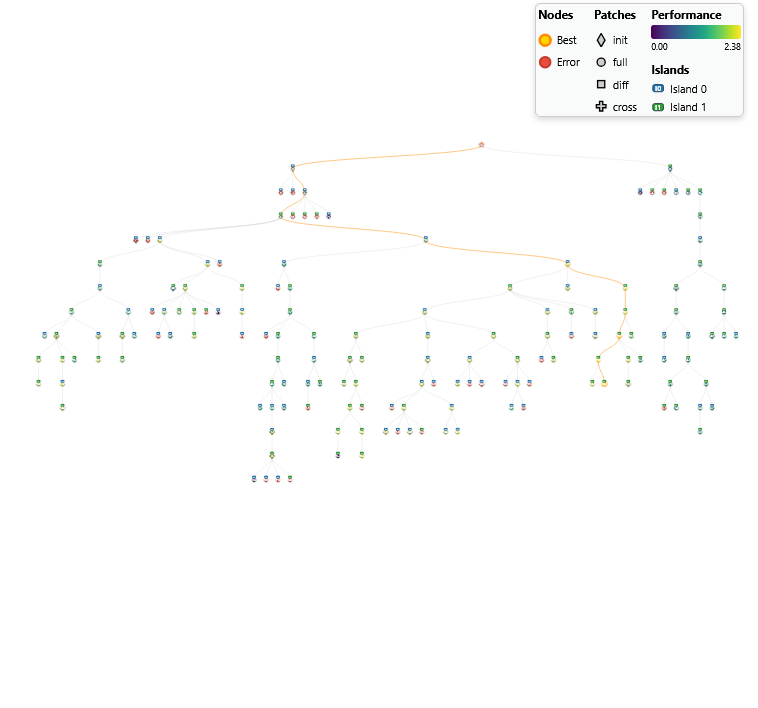
図: 初期スコア(0.96)から約2.5倍へ進化!AIが自律生成した6時間後の最適解
ShinkaEvolveとは、Sakana AIが開発した「LLMを用いたコード自動改善フレームワーク」です。
今回は、このShinkaEvolveをローカル環境で動かすため、実行基盤にOllamaを採用しました。
ShinkaEvolveのテンプレート問題であるCircle Packingを、完全にローカルLLMのみで実行した記録をまとめます。
Circle Packing(円詰め問題)とは?
決められた正方形の枠の中に、円を重ならないように配置し、その半径の総和(または最小半径)を最大化する最適化問題です。単純に見えて、配置の組み合わせが無限にあるため難易度が高い問題です。
検証のゴール
クラウドAPI(OpenAI等)を一切使わず、ローカルPC内のGPUリソースだけで自律的なコード改善サイクルを回すこと。
今回の記事ではOpenAI APIやGemini APIを一切使用していません。インターネット遮断環境でも動作可能です。
💻 動作環境
検証に使用したマシンスペックは以下の通りです。GPUメモリ(VRAM)が8GB程度でも、量子化モデル等を使えば動作可能です。
| 項目 | スペック |
|---|---|
| CPU | Intel Core i7 12700 |
| Memory | 32GB |
| GPU | RTX 3070 (VRAM 8GB) |
| OS | Windows 11 Home |
| WSL | Ubuntu 22.04.5 LTS |
🛠️ 使用したツール
| ツール名 | 説明 |
|---|---|
| ShinkaEvolve | Sakana AI製のコード進化フレームワーク |
| uv | 高速なPythonパッケージ管理ツール |
| Ollama | ローカルLLMを簡単に動かせる実行基盤 |
| rnj-1 | 4-bit量子化 (Q4_K_M) 済みの8Bモデル。VRAM 8GBで動作させるために採用 |
📕 rnj-1モデルを採用した理由
- gpt-oss:20bはモデルが大きいため推論時間が非常に遅くなりました。
- ministral-3:8bも実行してみたのですがうまくコードが実行できずスコアが0.0になることが多発しました。
- rnj-1:8bは軽量でありながらgpt-oss:20bと同等のコーディング能力を有しているため採用しました。
🔨 コード変更点・実装
ShinkaEvolveはデフォルトではOpenAI API等の利用が前提となっているため、ローカルLLM(Ollama)に向けた調整が必要です。
主な変更点は以下の通りです。詳細な差分はこちらのCommitで確認できます。
-
モデル指定のハードコーディング解除: configファイル等で指定したローカルモデル名が正しく渡るように修正。
具体的には、公式ドキュメントの🕹️ Local LLM Supportをベースに、モデル指定やAPIエンドポイント周りを修正しています。 - プロンプトの一部変更: rnj-1 は優秀ですが、複雑なシステムプロンプトのままでは指示通りに返答しない(フォーマット崩れなど)ケースが見られました。そのため、モデルが解釈しやすいようにプロンプトの一部を改変・最適化しています。
📥 修正版コードについて
修正版のコードを一式、GitHubにアップロードしました。
以下のリポジトリをcloneするだけで、すぐに試すことができます。
📝 動作手順
私の環境(Windows11・WSL)で導入した際の手順をステップバイステップで説明します。
0. 事前準備
まずはシステムを最新の状態にしておきます。
sudo apt update
1. Ollamaのインストールと設定
ローカルLLMの実行環境であるOllamaを準備します。
-
Ollamaのインストール
curl -fsSL https://ollama.com/install.sh | sh -
LLMモデル(rnj-1:8b)のダウンロード
ollama pull rnj-1:8b -
embeddingモデル(nomic-embed-text:latest)のダウンロード
ollama pull nomic-embed-text:latest -
Ollamaのコンテキスト幅を拡張
デフォルトの2kでは不足する場合があるため、8kに拡張します。※新しいターミナルを開いた場合は、再度exportコマンドを実行してくださいexport OLLAMA_NUM_CTX=8192
2. ShinkaEvolveのセットアップ
-
Pythonパッケージ管理ツール uv のインストール
curl -LsSf https://astral.sh/uv/install.sh | sh -
プロジェクトのセットアップ(クローン 〜 依存関係インストール)
リポジトリをクローンして、依存関係をインストール、仮想環境に入ってディレクトリを移動します。これらをまとめて実行します。# リポジトリのクローン git clone https://github.com/YukkiMoru/ShinkaEvolve cd ShinkaEvolve # 依存関係のインストール uv sync # 仮想環境のアクティベート source .venv/bin/activate # 実行ディレクトリへの移動 cd examples/circle_packing/
3. ShinkaEvolveの実行
準備ができたら、いよいよ実行です!
uv run run_evo.py
※ 実行を停止したい場合は
Ctrl+Cを押してください。
新しい別のターミナルを開いて以下のコードを実行することでWebUIを表示できます。
# 新しいターミナルを開いて実行
source .venv/bin/activate
cd examples/circle_packing/
uv run shinka_visualize --port 8888 --open
🚑 トラブルシューティング
起動に失敗する場合
以前の実行データが残っているとエラーになることがあります。
その場合は、成果物ディレクトリ examples/circle_packing/results_cpack を削除して再度試してみてください。
-
LLMモデルがメモリを食い続けている場合
バックグラウンドのOllamaプロセスを停止します。sudo killall ollama
🐟 結果
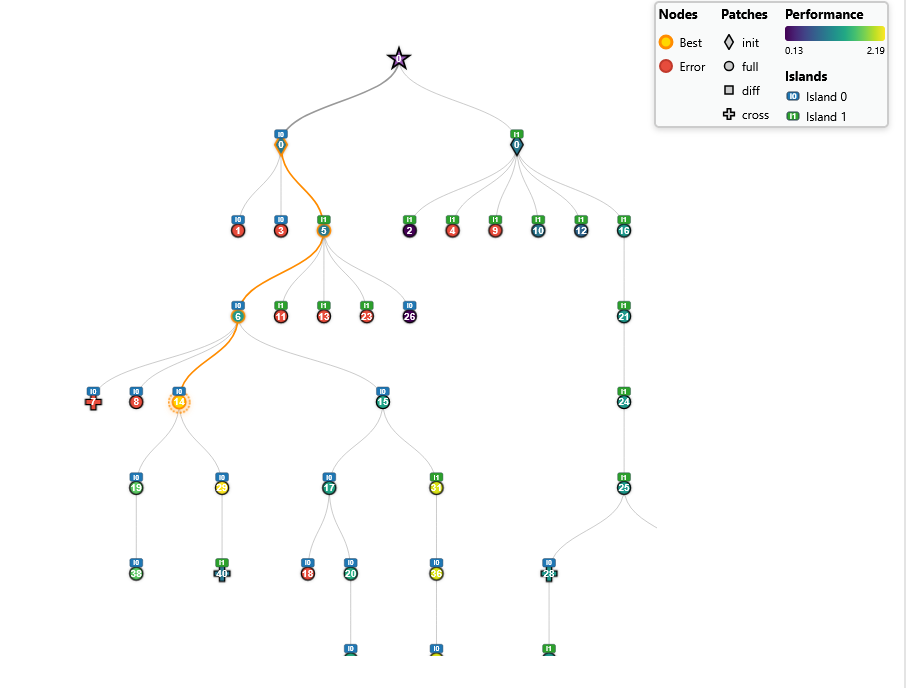
実行結果は以下の通りです。時間が経つにつれてスコアが向上していく様子が確認できました👀
-
初期解: 0.959764
-
1時間後: 2.194625
-
2時間後: 2.207945

-
6時間後: 2.378484
-
18時間後: 2.526801
ちなみに、公式のベストスコアは 2.635 です。
ローカルLLMでもかなり健闘していると言えるのではないでしょうか。
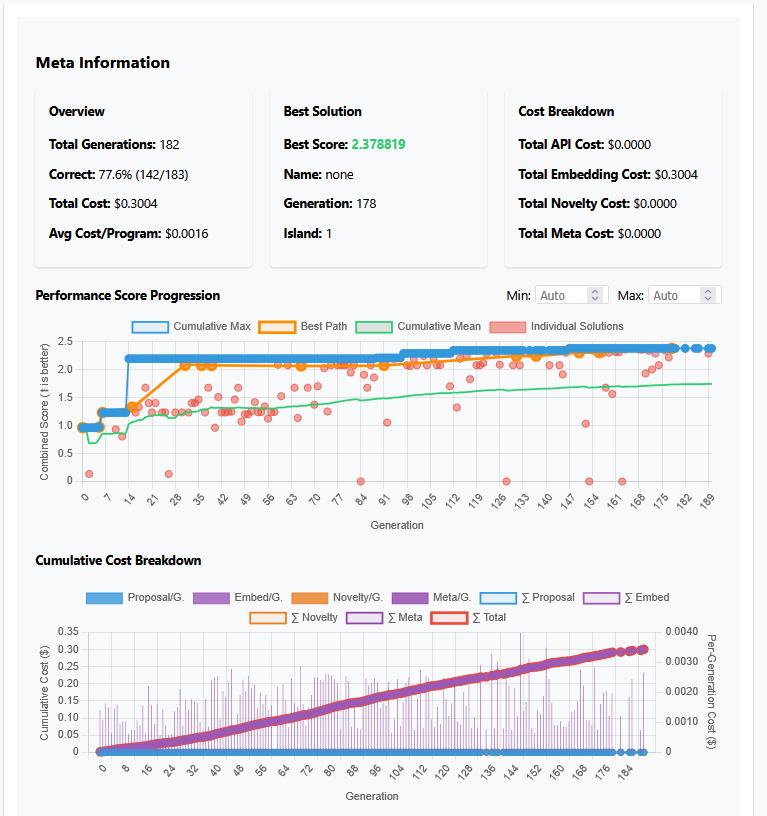
※Embedding Costでは$0.3004と書いてありますがlocalの設定ミスによる表示上の数値です。実際の課金は発生していません。
🔧 他のLLMモデルとの入れ替え方法
例として、使用モデルをgpt-oss:20bに入れ替える手順を説明します。
-
LLMモデルのダウンロード
ollama pull gpt-oss:20b -
設定ファイル (
examples/circle_packing/run_evo.py) の書き換え
ファイル内のevo_configセクションにあるモデル指定部分を書き換えます。変更前 (rnj-1:8b):
llm_models=["local-rnj-1:8b-http://localhost:11434/v1"], # ... meta_llm_models=["local-rnj-1:8b-http://localhost:11434/v1"], # ... novelty_llm_models=["local-rnj-1:8b-http://localhost:11434/v1"],変更後 (gpt-oss:20b):
llm_models=["local-gpt-oss:20b-http://localhost:11434/v1"], # ... meta_llm_models=["local-gpt-oss:20b-http://localhost:11434/v1"], # ... novelty_llm_models=["local-gpt-oss:20b-http://localhost:11434/v1"],※コード内の
local-rnj-1:8b-...となっている箇所をすべてlocal-gpt-oss:20b-...に置換してください。 -
プロセスの再起動
設定反映のため、一度Ollamaプロセスをリフレッシュしてから再実行します。sudo killall ollama uv run run_evo.py
🎉 おわりに
私自身、「ローカルLLMでShinkaEvolveを動かすのはスペック的に厳しいのでは?」と思っていましたが、案外スムーズに動いたので驚きました👀
今回作成した修正版コードはGitHubに公開しています。
興味のある方は、ぜひご自身のローカル環境で「AIによるコード進化」を体感してみてください🎣