プログラマは知らなければならないか?
知っていて損はありませんし、実際にパフォーマンスの高いコードを書く時に役立ちます
ただ、ほとんどの開発ではそこまで速度に拘らないので、気にしなくても仕事は出来ます
簡単な答え
キャッシュメモリは凄く高価なため速い、メインメモリは安価なので遅い
という事になります。もう少しだけ説明すると
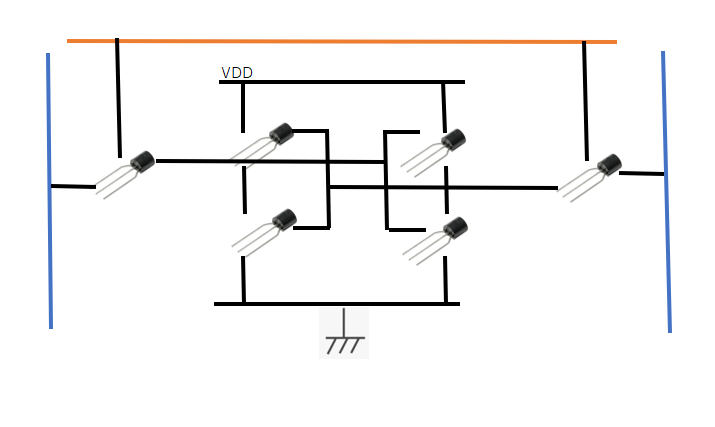
キャッシュメモリは、SRAM(Static RAM)を採用します
SRAMはフリップフロップ回路を使いデータを保存します
フリップフロップではリフレッシュが不要なためデータアクセスが速い(約4倍)
ただし、回路が複雑になるため、情報密度が低く、高価なメモリになります
(原理的にはMOSが2個とCMOS2個 = トランジスタ6個が必要)
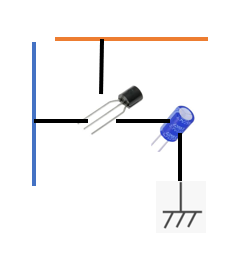
メインメモリは、基本的にはDRAM(Dynamic RAM)を採用します
DRAMは、コンデンサを利用してデータを保存するので定期的なリフレッシュ等も必要
そのため、SRAMと比較すると速度が遅い
(原理的には、トランジスタ1個とコンデンサ1個)
SRAM図
DRAM図
CPUキャッシュ
キャッシュについてもっと深堀りしてみよう
CPUアーキテクチャによって様々であるが、一例をあげる
現在のCPUにはコアが複数あり、コア毎にL1キャッシュ、L2キャッシュがある
また、全てのコアがアクセス出来るキャッシュメモリとしてL3キャッシュがある
L1~L3になるにつれ、速度は遅く容量は大きくなる
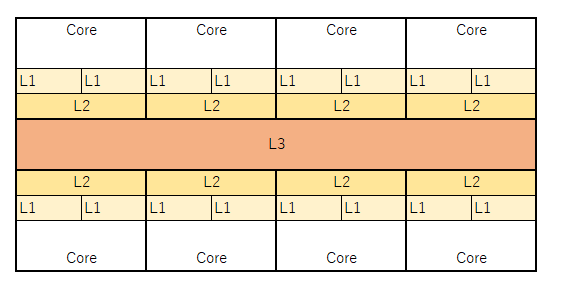
L1キャッシュ
L1キャッシュはCPUコアの最も近い場所にあるキャッシュで、すぐにアクセスが可能だ
例えるなら、机の上に置いてある資料である
手を伸ばせばデータにアクセス可能

一例でいえば、速度は4クロック(2ns)、容量は32KB
これが最も速いキャッシュ
L2キャッシュ
L1キャッシュに存在しないデータアクセスが発生した場合L2キャッシュを探しL1にコピーを行う
例えるなら、同じ部屋にある本棚

手の届かない場所にデータがあるため、専用のスタッフ(バス)にコピーしてもらう
そのため、多少の時間がかかる
一例でいえば、速度は10クロック(5ns)、容量は2MB
L3キャッシュ
L2キャッシュに存在しないデータはL3キャッシュからコピーしてくる
L3キャッシュにも存在しない場合はメインメモリからコピーしてくる必要がある
例えるなら倉庫だ

L3キャッシュはL2よりさらにアクセスに時間がかかるものの、大きな容量がある
一例でいえば、30クロック 15ns、容量は30MB
ライトバック
例えばメモリの値に変更があった場合、L1キャッシュの値を変更してもメインメモリに反映されない
ので、L1キャッシュに変更があった場合は、L2、L3、メインメモリへと変更を反映させなければならない
それを、ライトバックという
また、他のコアが同じ領域のデータにアクセスしている場合には、他のコアのL1、L2キャッシュにも反映させる必要がある
キャッシュの階層化
なぜキャッシュを階層化させるのか?
階層化させると、ライトバック問題も発生し、デメリットがある。
が、例えばL1キャッシュを大きくしすぎると、データのアクセスに時間がかかるようになる
机でいえば、机を広くして沢山資料をおけば、資料を探す時間が増えてしまう
容量と速度はトレードオフの関係になる
そこで、色々な実験結果から、現在の3階層のキャッシュが最も効率が良いという結果になったと思われる
メインメモリー
メインメモリーはCPUの外部に接続される
FSB(Front Side Bus)あるいはDMI(Direct Media Interface)といったバスで接続される
またDRAMが使われるため、CPUキャッシュと比較すると非常に遅い
実測値だと100ns程度かかるそうです
(L3キャッシュの10倍だぞ10倍)
外部ストレージ
おまけです
SSD(NVMe M.2) 90μs
SATA3.0 SSD 150μs
SATA3.0 HDD 15ms
メモリと比べると圧倒的に遅いですね
キャッシュが速い事をプログラムでどう生かすか
本題ですね
今までの事から、L1、L2、L3、メインメモリ、外部ストレージ と速度が遅くなる事を学びました
ではそれをプログラマはどう利用するか
外部ストレージをキャッシュする
外部ストレージが遅いのはみんな知ってると思います
なので、ファイルをメモリに読み込んでメモリ上で処理を行い、終了時にメモリからファイルに書き込みを行います
ここはプログラムでは基本なので説明不要でしょう
キャッシュを制御する
一応アセンブラ命令には、CPUキャッシュを操作する命令が存在するので
プログラマが明示的にキャッシュを制御する事は可能ですが
普通のプログラムで使う事はありません
そんなのは、コンパイラやCPUが自動的に行ってくれます
では、プログラマは、CPUキャッシュをどうやって制御するのか?
答えは、ループ処理等の連続で使うデータは連続で隣り合わせのメモリに配置する事です
キャッシュはあまり容量が大きくありませんので
使用するデータが連続したメモリに配置されていれば
キャッシュのヒット率が増え、非常に速くなります
ではキャッシュミスをしやすい例
多次元配列の順番
for(int i=0; i<1000000; i++){
for(int j=0; j<1000000; j++){
dest[i][j] = src[i][j];
}
}
for(int i=0; i<1000000; i++){
for(int j=0; j<1000000; j++){
dest[j][i] = src[j][i]; // 添え字の順番が逆
}
}
上記のコードは添え字が [i][j]か[j][i]が違うだけだが動作は同じです
ところが、例2の方が遅いです(テストでは3倍以上差が出た)
なぜでしょう?
キャッシュヒット率の違いです
二次元配列がメモリにどう配置されるかがイメージできると分かると思いますが
例1では、Jループでは連続したメモリに対してアクセスをしていますが
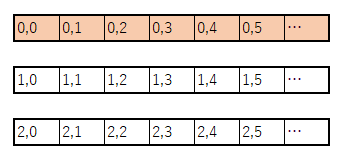
例2では、1000000ずつ飛び飛びにアクセスしています。そのためキャッシュミスが発生しています
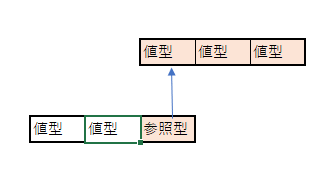
参照型と値型
参照型は、たとえばClassなどのオブジェクトの事を指します
値型(int等)は、メモリに直接データが存在しますが
参照型は実体へのポインタしかないので、データは非連続アドレスになります
そのため、参照型のデータをアクセスすると、キャッシュミスをおこします
(言語によって、仕様が異なる)
構造化データ
たとえばデータを持つときに、構造体をつくり同じオブジェクトのデータをまとめがちだ
struct Item{
int id;
char name[100];
int price;
char memo[1000];
.......
};
こういった構造はオブジェクト指向では当たり前で正しい設計であるが
例えば沢山のItemに関して priceを集計する場合
Item items[10000];
...
int total = 0;
foreach(var i: items){
total += i.price;
}
(コードはイメージ)
のように書くと思うが、この場合は構造体Itemが大きいため、頻繁にキャッシュミスをおこす
(priceが連続していない)
ので、集計に関して高速化を考える場合には、オブジェクト毎の構造体を作らず
priceを連続させるデータ構造にするといい
例えば
int prices[]; という変数を作り、itemの0番目から順にデータを入れておけば
int prices[10000];
...
int total = 0;
foreach(var i: prices){
total += i;
}
priceは連続しているので、キャッシュミスが大きく減る

このように、Object Orientedではなく、Data Orientedにデータ構造を変更する事で
キャッシュヒット率を上げて高速化出来る
そのほか
他にもいろいろとキャッシュミスを防ぐテクニックがある
良かったらオススメのテクニックを教えてください