できたもの

上記gif動画のように移したカードが何かを判定する簡単なアプリを作成しました。
.mlmodelファイルの作成
Create MLから.mlmodelファイルを作成します。
Xcodeのplaygroundから作成できます。次期バージョンからは独立したアプリになるみたいですがXcode10.3環境ではplaygroundから使用します。
playgroundをmacOSで開いたら
import CreateMLUI
let builder = MLImageClassifierBuilder()
builder.showInLiveView()
と記載して実行すると...
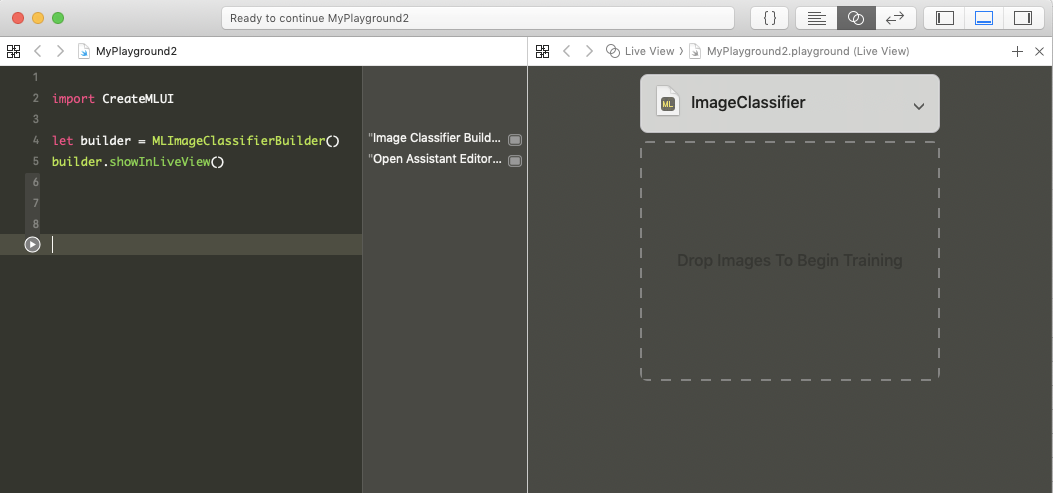
上記画像のようになると思います。
Drop Images というところに画像ファイル(ディレクトリ)をドロップします。
パラメータも選択できますが、今回のアプリレベルなら調整は必要ありませんでした。精度に関してはこのあたりに書いてあります。
ドロップするとトレーニングが始まって完了するとmlmodelファイルがダウンロード可能です。
アップロードしたディレクトリは以下のようになっています。
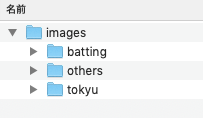
各ディレクトリには10枚程度画像が入っています。ドキュメントには最低10枚とあったのでまずは最低枚数を試しました(結果それでうまくいきました)。
iOS
コードはiOS11のVision.frameworkを使ってみるを参考にさせていただきました。
import UIKit
import AVFoundation
import Vision
class ViewController: UIViewController {
@IBOutlet fileprivate weak var textView: UITextView!
override func viewDidLoad() {
super.viewDidLoad()
// カメラキャプチャの開始
startCapture()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
// カメラキャプチャの開始
private func startCapture() {
let captureSession = AVCaptureSession()
captureSession.sessionPreset = .photo
// 入力の指定
guard let captureDevice = AVCaptureDevice.default(for: .video),
let input = try? AVCaptureDeviceInput(device: captureDevice),
captureSession.canAddInput(input) else {
assertionFailure("Error: 入力デバイスを追加できませんでした")
return
}
captureSession.addInput(input)
// 出力の指定
let output = AVCaptureVideoDataOutput()
output.setSampleBufferDelegate(self, queue: DispatchQueue(label: "VideoQueue"))
guard captureSession.canAddOutput(output) else {
assertionFailure("Error: 出力デバイスを追加できませんでした")
return
}
captureSession.addOutput(output)
// プレビューの指定
let previewLayer = AVCaptureVideoPreviewLayer(session: captureSession)
previewLayer.videoGravity = .resizeAspectFill
previewLayer.frame = view.bounds
view.layer.insertSublayer(previewLayer, at: 0)
// キャプチャ開始
captureSession.startRunning()
}
}
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// CMSampleBufferをCVPixelBufferに変換
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
assertionFailure("Error: バッファの変換に失敗しました")
return
}
// CoreMLのモデルクラスの初期化
guard let model = try? VNCoreMLModel(for: ImageClassifier().model) else {
assertionFailure("Error: CoreMLモデルの初期化に失敗しました")
return
}
// 画像認識リクエストを作成(引数はモデルとハンドラ)
let request = VNCoreMLRequest(model: model) { [weak self] (request: VNRequest, error: Error?) in
guard let results = request.results as? [VNClassificationObservation] else { return }
// 判別結果とその確信度を上位3件まで表示
// identifierは類義語がカンマ区切りで複数書かれていることがあるので、最初の単語のみ取得する
let displayText = results.prefix(3).compactMap { "\(Int($0.confidence * 100))% \($0.identifier.components(separatedBy: ", ")[0])" }.joined(separator: "\n")
DispatchQueue.main.async {
self?.textView.text = displayText
}
}
// CVPixelBufferに対し、画像認識リクエストを実行
try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:]).perform([request])
}
}
プロジェクトに先程の.mlmodelファイルを加えたら完了です。
困った点
最初は読み込むカードのみの画像を入れたところ、カードが写ってなくてもどちらかに判定、それもどちらかに固定で判定されてしまう状態でした。さらにもう一方のカードを移してもあまりconfidenceが上がらない状態で困っていました。
カードが写っているかどうかも判定したかったため背景のみの写真も撮影してothersとしてアップロードしたところ精度が非常に上がりました。
今回は同じ部屋でしか試していないのですが、屋外などでは今回のままではうまく行かないかもしれません。
枚数やオプションを増やした場合、一気に学習時間が伸びたのでそのへんがやはり問題になってくるのだなと感じました。