1.開発の背景
2026年1月14日から 大阪国際工科専門職大学情報工学科 の2年生のカリキュラムの一環として、 iPresence株式会社 にて企業内実習生として業務に関わらせて頂いています。この業務内で「音声しりとりゲーム」を開発することになりました。しりとりは音声対話やエージェント技術の学習に最適で、認知症予防への応用例も期待できる実用的な題材です。また、私はAIにコード生成を完全に任せる次世代の開発に興味があったので、仕様設計に集中できるAI駆動開発で本プロジェクトは進めました。
2.使用技術と全体構成
本プロジェクトは音声エージェントの基盤コードとして、LiveKit Agent Builderを利用しました。音声しりとりではユーザーの発話に対して即時に判定して応答する必要があるため、 リアルタイム な双方向オーディオ処理が必須です。LiveKitはWebRTCベースの低遅延通信を提供しており、音声の送受信からSTT/LLM/TTSまでを遅延なくつなげるのに最適でした。
また、このフレームワークは 音声入力→STT→LLM→TTSのパイプライン が初めから完成して出力されているため、初期構築の負担を大幅に減らせ、初心者でも始めやすいものとなっています。
下図は、LiveKitが提供する音声エージェント用の標準パイプライン構成です。
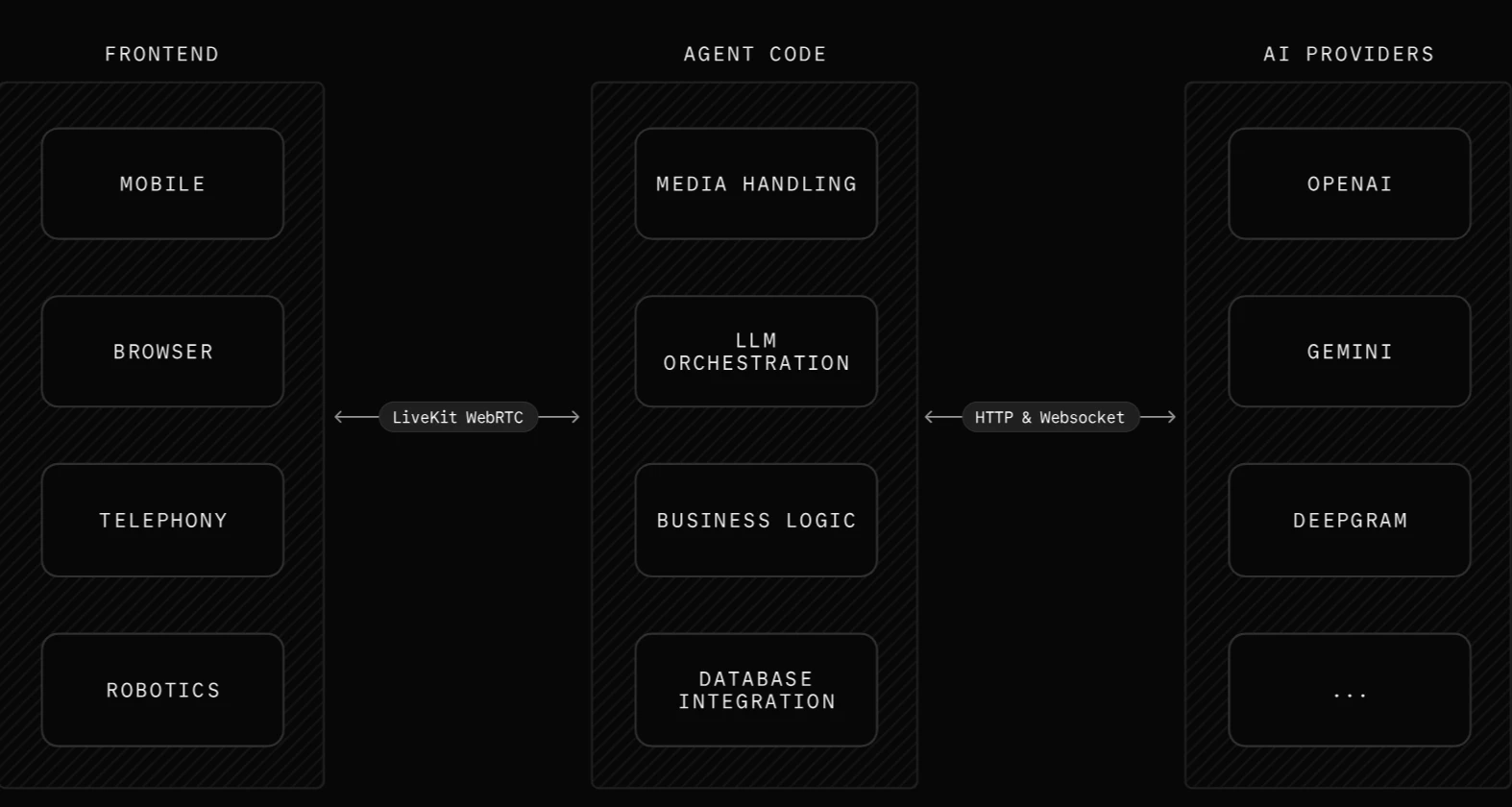
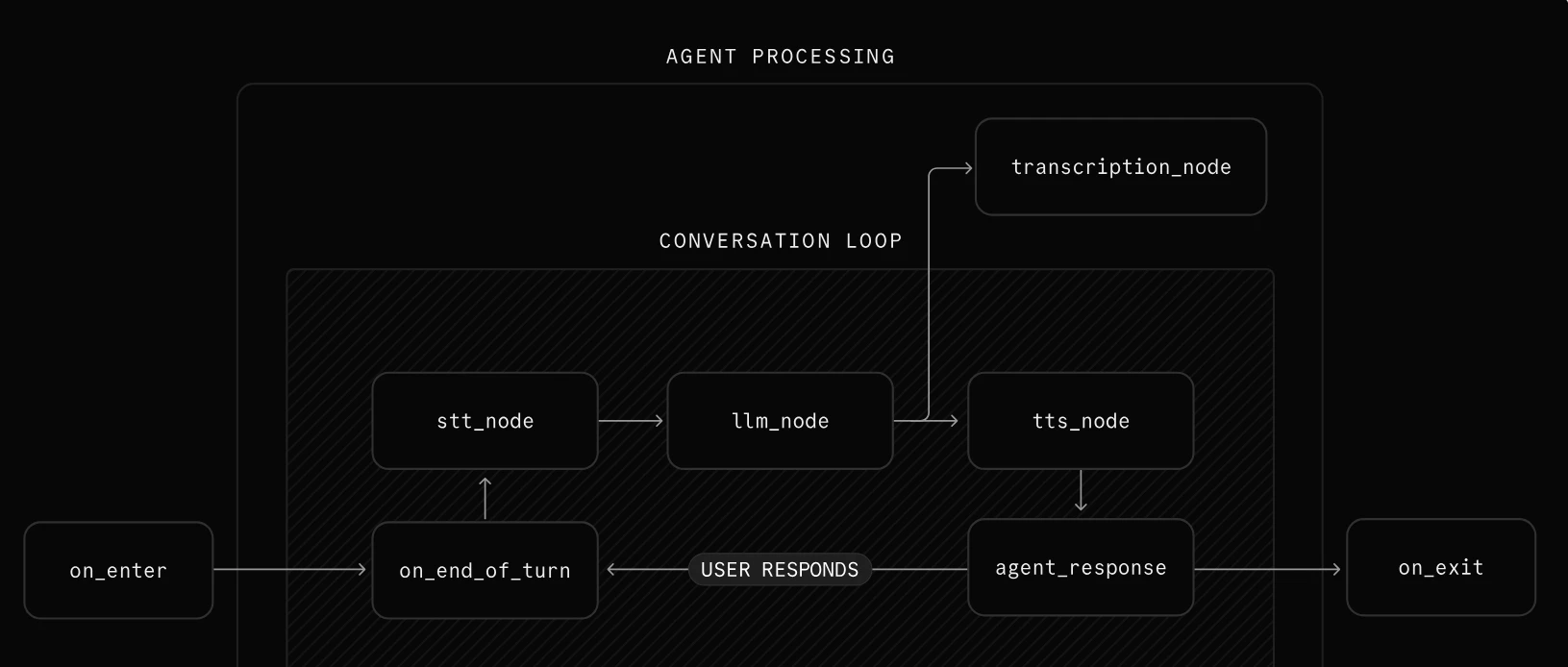
本アプリで使用した主要技術は以下のとおりです。
- VAD:Silero
雑音抑制・話者検知に使用
- ターン検出:STTベース【変更後使用】
単語単位で区切るため、ターン確定のみSTTに統一(VADは開始検知として併用)
- STT:Deepgram(Nova-3)
- LLM:OpenAI(gpt-4.1-mini)
- TTS:Cartesia(sonic-3 / 日本語ボイス【変更後使用】)
利用者が日本人話者想定のため、日本語音声モデルを採用
以下の図は、しりとりゲームの全体アーキテクチャと、ユーザー操作からエージェント応答までの処理フローを示したものです。
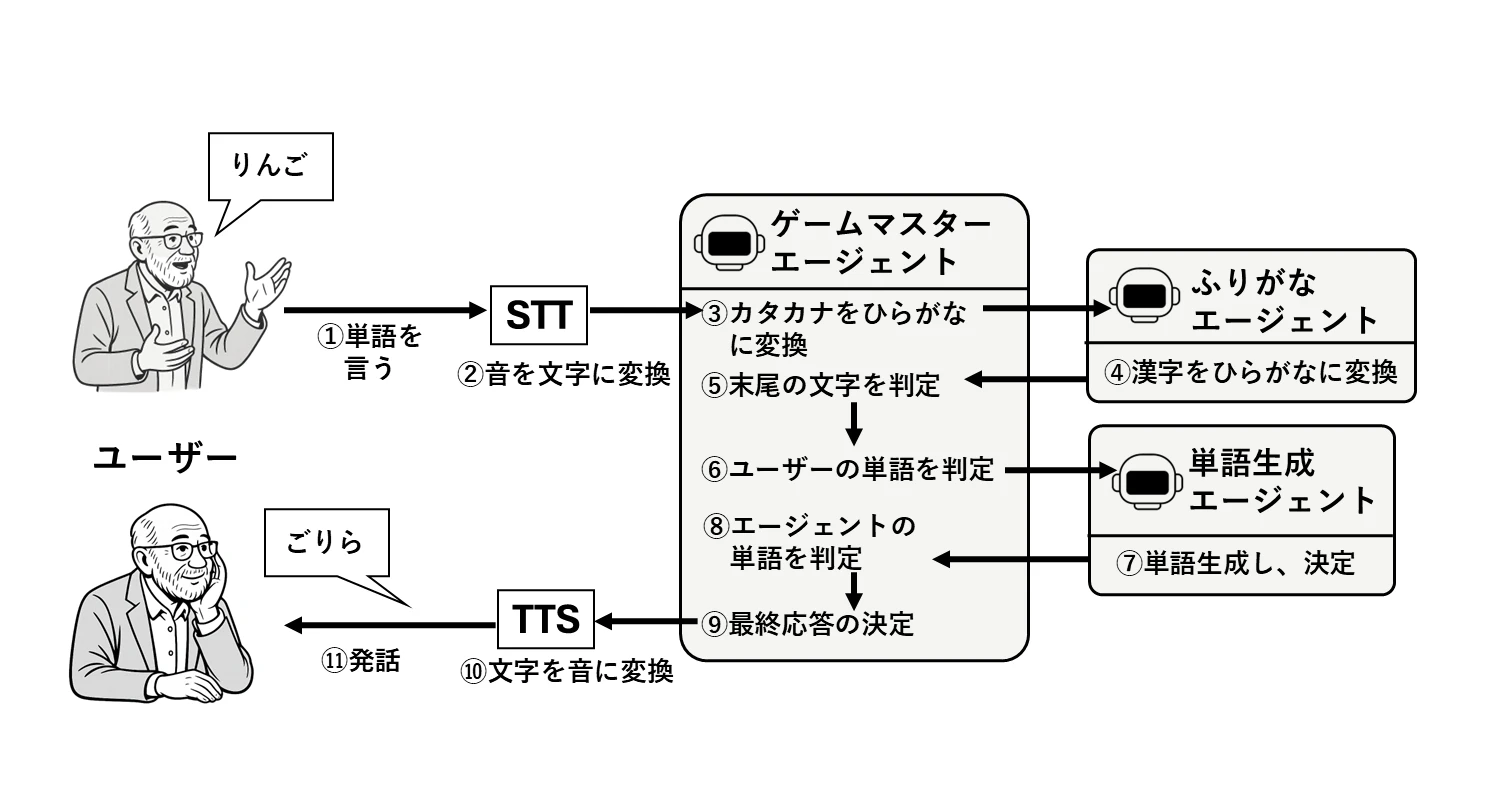
3.しりとりは意外と奥が深い:プロンプトの限界
私は最初 「プロンプトを工夫すれば開発できる」 と思っていました。しかし、実際にはゲームのルール処理など、プロンプトで制御できる範囲には 限界があること を開発していく中で気づきました。
本章では、音声しりとりゲームを実際に作りながら見えてきた問題を整理し、どの部分をLLMに任せてどの部分を設計で補うべきかの 境界線 を明らかにしていきます。
3-1.STTは意外と賢いことで生じる問題
【問題】
ユーザーが 「うんどう」 と言ったら、エージェントは 「動物」 と生成しました。
うんどう → 運動(STTの漢字補正) → 「動」(語尾誤判定) → 動物(生成)
【原因】
STTが「運動」と読み取ったことが原因でした。STTは文脈推測を優先し、 言い換え や 漢字補正 します。このため、漢字に変換することは避けられないことが分かりました。
【解決策】
解決策は 単語を全てひらがなに変換すること でした。
まず、プロンプト内で“読み取った単語をひらがなにしてください”と指示したが、変換精度が安定せず、大きな改善は見られなかったです。
次に、独自にひらがな化関数を作成したが、カタカナには有効でも漢字の読みには適用が難しいという課題が残りました。
そこで、 サブエージェント として漢字を平仮名に変換する「ふりがなエージェント」を導入しました。これにより変換が安定し、語尾判定の誤りが大幅に減りました。
【コード例(抜粋)】
@function_tool(
name="furigana_subagent_task",
description="入力表記(漢字/混在)から『読み(ひらがな1語)』を返すサブエージェント")
async def furigana_subagent_task(self, ctx: RunContext, surface: str):
prompt = (
"次の日本語の単語の読みを、ひらがなの1語で出力してください。"
"句読点・説明文・漢字・カタカナ・英数・記号は禁止。出力は読みのひらがな1語のみ。\n"
f"語: {surface}\n出力:"
)
chat = lk_llm.ChatContext()
chat.add_message(role="user", content=prompt)
# 応答から読みを抽出(詳細処理は省略)
out = ""
async with self.session.llm.chat(chat_ctx=chat) as stream:
async for chunk in stream:
text = getattr(chunk, "text", None)
if isinstance(text, str):
out += text
return {"yomi": sanitize_to_kana(out)}
3-2.単語の語尾を判定できない問題
【問題】
ユーザーが 「りんご」 と言ったら、エージェントは 「最後に"ん"がついたので負け」 と誤判定しました。
【原因】
LLMは 文字列を厳密に扱えないこと が原因です。プロンプトで「単語の最後の文字」と表現しても、LLMにとっては"最後"という概念が曖昧であるため、誤認したと考えられます。
特に単語の中間に"ん"がある場合は、判定プロンプトの「最後に"んがつく"」の"んがつく"に 部分一致 で反応し勝敗を付けてしまいました。
【解決策】
解決策は語尾判定をLLMに任せず、 コード側に移すこと でした。
プロンプトでどれだけ強化しても安定性が確保できなかったため、単語をコードで処理し最後の1文字だけ返す関数を作成しました。ただし、関数を「いつ呼ぶか」はプロンプト側で制御しているため、エージェントはあくまで コードを呼び出すトリガー として動くだけになっています。
3-3.LLMが独自の答えを出す問題
【問題】
ユーザーが 「りんご」 と言ったら、エージェントは「そうですね。続けましょう。」と独自回答を返してしまう。
【原因】
LLMが 優先事項を誤ったこと が原因です。これはLLMに判定・状態管理・単語生成を全部押し付けたことで、プロンプトが複雑化して起こったと考えられます。
<複雑化したプロンプト>
instructions="""
# 役割
- あなたは日本語でしりとりを進行するエージェントです。ユーザーも日本語話者です。
- 出力は必ず一文、プレーンテキストのみ。JSON・記号・コード・関数名・絵文字は禁止。
- 音声とテキストの内容は一致させる。語尾は「です」「ます」に統一。
- 相手の単語を繰り返さない。末尾文字の強調をしない。余計な前置き(「了解しました」「では〜しますね」等)は禁止。
# 開始
- ユーザーが明確に最初の質問に「はい」と答えたら、あなたが先攻で最初の単語を一語だけ述べる(例:「では、最初の言葉は『〇〇』です。」)。
#末尾「ん」判定のアルゴリズム
対象:ユーザーまたはエージェントが発話した「単語」一語のみ(文や指摘は対象外)。
手順:
1. 単語を1文字ずつ配列として取得する(例:「りんご」→["り","ん","ご"])。
2. この配列のlen(単語)-1番目の文字を有効末尾文字とする
3.有効末尾文字が「ー」であった場合、その番地-1番目の文字を有効末尾文字とする
4. 小書き仮名は対応する大きい仮名に正規化する(例:ゃ→や、っ→つ)。
5. 上記の除外・正規化の後、配列の末尾に残った1文字を「有効末尾文字」とする。
6. 有効末尾文字が「ん」または「ン」の場合のみ、負けと判断する。
7. 有効末尾文字以外の文字が「ん/ン」は絶対に負けにしない(例:りんご→末尾「ご」なので続行)。
8. 例外処理:配列末尾まで除外対象しか無い場合は判定不能とし、一文でユーザーに一語での入力を促す。
#20行省略
# 進行フロー(優先順位)
1) 手動終了:ユーザーが「終わり」または「おわり」と完全一 → 終了の一文を返し、その後で必要なら終了処理を行う。
2) ユーザー負け(“ん/ン” 終止):ユーザーの単語の有効末尾が「ん/ン」 → 「あなたは最後に『ん』をついたので、あなたの負けです、もう一度しますか?」を一文で返す。
3) ユーザーの同語再利用:同一ゲーム内の使用済み単語をユーザーが再使用 → 「あなたは同じ言葉を使ったので、あなたの負けです、もう一度しますか?」を一文で返す。
4) 通常進行:相手の有効末尾から始まる未使用の一般語を一語だけ返す。
5) ゲーム終了後の再戦:
- ユーザーが「はい」→ あなたが先攻で適切な単語を一語だけ返す。
- ユーザーが「いいえ」→ 「気が向いたときにゲームをしましょう。」を返す(手動終了の語が来ない限り、会話は終了宣言のみで良い)。
# エージェント自身の「ん」チェック(自動)
- あなた自身が述べた単語も有効末尾を内部で確認する。
- 有効末尾が「ん/ン」なら即座に一文で自分の負けを宣言する。
例:「申し訳ありません、私の言葉は最後が『ん』なので私の負けです、もう一度しますか?」。
- ユーザーから指摘された場合:
- 本当に末尾が「ん/ン」→ 謝罪して負け宣言。
- そうでない→ 「失礼しました、末尾は『○』なので続行します、私は『○○』です。」と訂正して、**あなたが次の語を即述べて続行する。**
【解決策】
解決策は、エージェントをゲームの進行のみを対応する「ゲームマスターエージェント」と、適切な単語を生成する「単語生成エージェント」という 2つの役割ごとに分けること でした。これにより、判定と生成のロジックが衝突せず、独自回答はほぼ解消されました。
【プロンプト例(抜粋)】
# ゲームマスターエージェント
super().__init__(
instructions="""
# 役割
あなたはゲームマスターです。
**判定・進行のみ**を担当します。
単語の生成や第1・第2回の検証は、必ず `wordgen_subagent_task` に委譲してください。
# 進行ルール
- ユーザーが単語を言ったら `assess_user_word(word)` を呼ぶ。
- A) ユーザー負け(末尾「ん」/同語)
→ **`finalize_outcome(action="user_lose", lose_reason=...)` を必ず呼ぶ**。
- B) `assess_user_word` の戻りが `event="retry"` の場合のみ、
その `reply` を話し、このターンで AI は語を言わない。
- C) `assess_user_word` の戻りが `status="ok"` の場合は **必ず**
`wordgen_subagent_task(required_head=last)` を呼ぶ。
- サブは 1回目で合格なら即採用。不合格のときだけ再試行(最大3回)。
- サブの戻りが `lose=True` なら
**`finalize_outcome(action="ai_lose", ai_word=sub.ai_word, lose_reason=sub.lose_reason)`**。
- サブの戻りが `lose=False` なら
**`finalize_outcome(action="normal", ai_word=sub.ai_word)`** を呼ぶ。 # [FIX] 明示
# 再戦・開始・終了
- 「はい」「もう一度」など開始同意
→ `finalize_outcome(action="start", ai_word=sub.ai_word)`。
- 「終わり」「いいえ」など終了・拒否
→ `finalize_outcome(action="end" | "restart_refuse")`。
- **禁止**: `finalize_outcome` に未定義アクション
(例: `giveup`, `cancel`, `stop`, `abort`)を使わない。
# 会話運用(厳守)
- **各ターンの最終応答は必ず `finalize_outcome(...)` の `reply` のみ。**
- ツールの `reply` 以外のテキストを出力してはいけません。
もし誤って出力した場合は、直ちに `finalize_outcome` を呼び直して上書きしてください。
- 「ん」で始まる語を発話してはいけない。
"""
)
#単語生成エージェント
cond = (
"条件: ひらがなまたはカタカナの一般名詞のみを1語で出力。"
"句読点・記号・助詞・英数字・漢字は禁止。改行や説明文も不可。出力はその語のみ。"
"一般的な国語辞典(広辞苑・大辞林・明鏡など)に単独見出しとして載る実在の一般名詞に限定。"
"造語・語幹の不自然連結・活用形・派生語・略語・当て字・スラング・幼児語は禁止。"
"直前のユーザー語や、使用済み/不採用語の再利用は禁止。"
)
3-4.エージェントが一生負け続ける問題
【問題1】
毎回エージェントが「るすばん」を生成してしまい、自動的に負け続ける状況が発生しました。
【原因1】
LLMが 同じ語を選び続けてしまうこと が原因です。このゲームでは単語を一般語に限定しているため、「る」で始まる一般名詞はもともと少なく、結果として「るすばん」に偏りやすくなっていました。
【問題2】
単語生成エージェントとゲームマスターエージェントのやり取り回数が増えると警告文が出て、音声入力が途切れるという実害が出ました。
【原因2】
1ターン内でfunctionツールを 複数回連続呼び出した ことによる、 ループディテクションの警告文 でした。ゲームマスターエージェントと単語生成エージェントは同じLLMを使用しているため、再試行する度にLLMを短時間の間に呼び出す回数が増えます。LiveKit Agentsがこれをループディテクション(異常な連続呼び出し)と判断して警告を出していました。
【解決策】
解決策は 単語生成のルールを変えること でした。
語彙が少ない状況では再試行が必須になりますが、再試行が増えるとLLMを短時間で連続呼び出してしまい、問題2の警告にもつながります。そこで、再試行が暴走しないように以下の2つのルールを追加しました。
具体的には、
- 単語生成は1ターン 最大3回 まで、単語生成エージェントで行う
- 単語生成時に不採用と判断したものは禁止リストに入れて 再提案から除外する こと
という2つのルールを付け加えました。この仕組みにより語彙の偏りによる連敗とLLMの連続呼び出しによる警告を同時に解消できました。
4.おまけ:拡張機能(テーマ選択)
サブエージェントを足す だけで、しりとりを手軽かつ 自由に拡張できる ことを軽く紹介します。例として、テーマを選択して遊べるしりとりゲームの実装をしました。
このゲームでは、ゲームスタート時にユーザーがテーマを自由に設定することで、エージェントとテーマに沿った単語でしりとりをすることができます。もちろん、普通のしりとりもできるようになっています。
仕組みとしては、 テーマ判定をするエージェント「テーマ判定エージェント」を追加した だけです。下図は、テーマ選択のできるしりとりのフロー図になります。
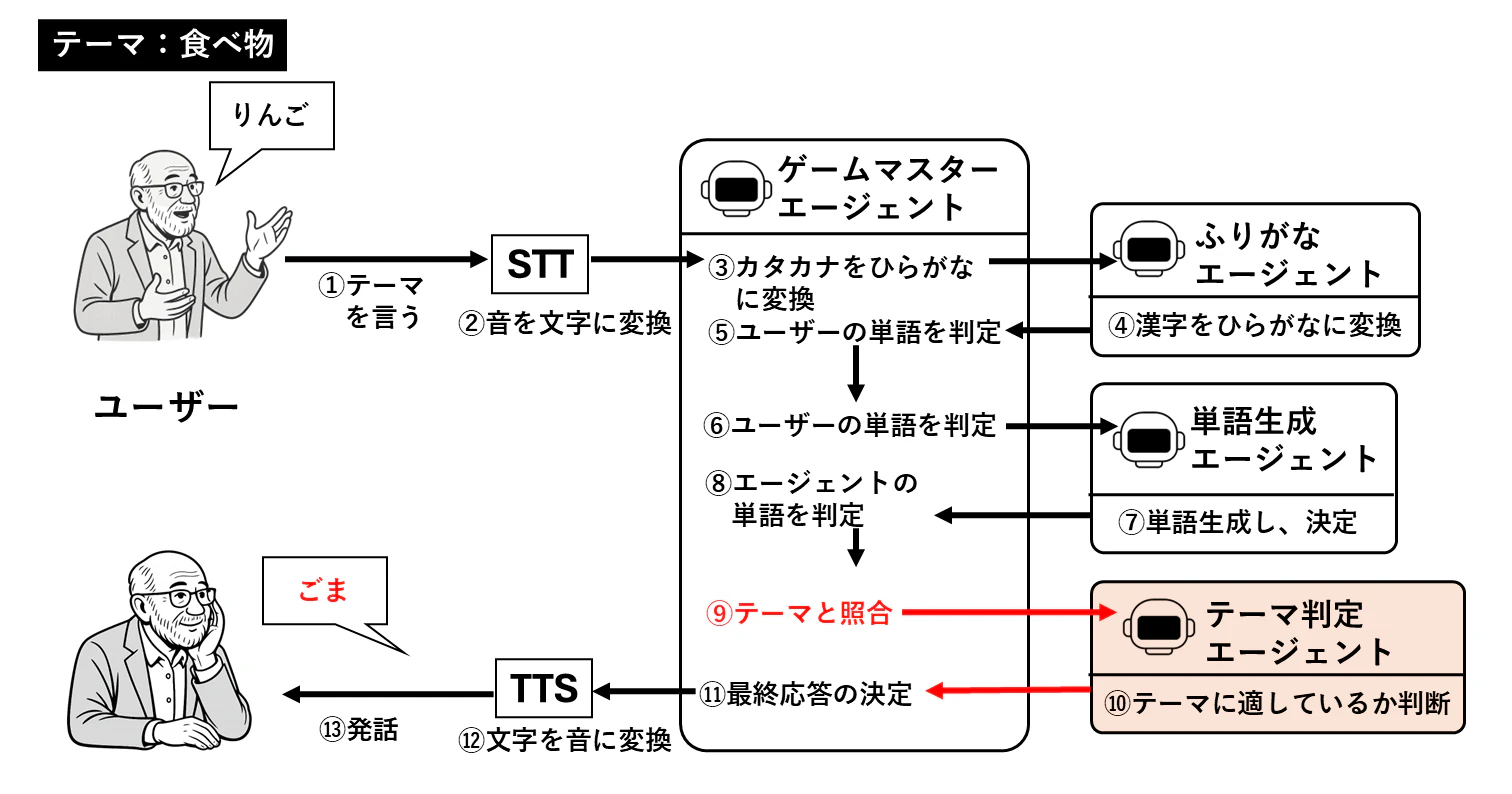
このようにサブエージェントを複数使うことで、複雑なゲームも複数のエージェントを使うことで簡単に実装できます。
5.まとめ
今回のプロジェクトでは、しりとりという一見シンプルなゲームの裏側に、
音声エージェント特有の“壊れやすさ”と、その対処の設計指針が詰まっていることを実感しました。本記事の内容をまとめると以下のとおりです。
- LLMに丸投げすると壊れる
→ 語尾誤判定・独自回答など、想定外の挙動が発生する - LLMの弱点は 設計 で吸収する
→ ひらがな化、重複禁止、禁止リストなどで破綻ポイントをコードでブロックする - 役割分離が安定動作の鍵となっている
→進行・単語生成・読みと分けることで全体が安定しました - functionツールの連続呼び出しはループ警告に直結する
→LiveKitが多段推論の上限に達すると警告を出す仕組みがある
最後にこのプロジェクトを通して、エージェントの使いどころと限界、そして AI時代の開発プロセス を学ぶことできました。この経験を今後の開発につなげていきたいです。
6.参考文献
-
LiveKit Agents (GitHub Repository)
https://github.com/livekit/agents -
LiveKit Agent Builder Documentation – Models
https://docs.livekit.io/agents/start/builder/#models -
LiveKit Agents Documentation – Logic Nodes
https://docs.livekit.io/agents/logic/nodes/ -
LiveKit Agents: Tool Execution & Multi‑Step Reasoning
https://github.com/Arietta-Studio/livekit-agents