この記事はNextremer Advent Calendar 2018の15日目の記事です。
AIゴーちゃん。とは
Nextremerでは、日頃より様々なプロジェクトで対話AIを搭載したインタラクティブなサイネージ開発を行っているのですが、『AIゴーちゃん。』プロジェクトはテレビ朝日さんと共同で、昨年からスタートしました。
この記事では、
- SXSW 2018
- テレビ朝日夏祭り・Digital Content Expo 2018
の2バージョンにおけるAIゴーちゃん。の技術的仕組みについてお話します。
前提として、
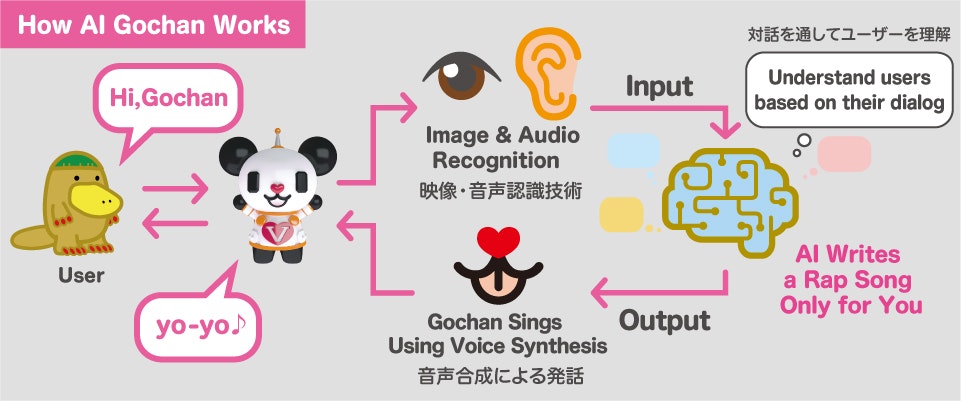
いずれのイベントにおいても、以下のようなフローで来場者はAIゴーちゃん。を体験することができます。
- ゴーちゃんの目の前に設置されたマイクに話しかける
- ゴーちゃんがいくつか質問をしてくるので、それに答える
- 質問への回答内容に合わせて、ゴーちゃんがラップや歌を考えて歌ってくれる🎤🎉
SXSW2018 (2018/03)

–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
僕がAIゴーちゃん。の開発に始めて参加したのは今年の1月頃でしたが、
その時課せられたミッションは、
『どうにかゴーちゃん。がラップを歌えるようにしてほしい。
🔥🔥🔥英語で🔥🔥🔥』
というもので、本番まで2ヶ月というスパンの中、
うっすらと『コレハ、タイヘンダナァ』と思いました。
AIによるラップやDJは国内外にいくつか例がありますが、ある程度リサーチした時点で、
いくらNextremerが対話を専門にしている会社とは言えど、
この領域で真っ向勝負するのは分が悪いことが見えました。そこで、
「まるで人間のようにリアルなラップ」を目指すよりも、
「ロボットにしか出来ない超高速ラップ」を売りにしていく方針で勝負をかけました。
幸いにしてラップにはメロディがないので(※暴言)、
「歌う」という行為に関しては、
ビートに合わせて単語を分割して発話すればいいというだけのことなので、
その部分の実装は非常に簡単でした。(※逃げました)
バックトラックは予め用意した固定の曲なので、テンポを解析しておいて、Max7で簡単なパッチを作れば準備はOKです。
発話に関しては、サードパーティの音声合成APIを使用して音声合成してダウンロードしたmp3ファイルを、タイミングよく拍に合わせてポンポンと再生していきます。
とはいえ、コンテンツ全体としては、
- 音声認識をする
- ユーザーの発話内容に基づいて、返答を考える(Nextremerのコア技術)
- 返答を音声合成する
- 返答をリズムに合わせて再生する
- 歌詞をリズムに合わせてモニターに映し出す
- ユーザーの顔認識をする(※楽曲の盛り上がった箇所で、ユーザーの顔をモニターに映し出す為)
- 発話内容や楽曲のタイミングに応じて、ゴーちゃんの顔をアニメーションする
など様々なシステムを同期的に動かさなければいけないので、なかなか大変な開発でしたが、
結果的には、女性や子供を中心に大きな笑顔を持って受け入れられました🎉。
テレ朝夏祭り・デジタルコンテンツエキスポ (2018/08・2018/11)
ゴーちゃんと会話した内容に基づいて歌詞を考えて、
— 余湖 雄一 (@yuichi_yogo) 2018年8月12日
曲を作って歌ってくれる謎のスゴイ技術! pic.twitter.com/szn5ov9LPi
–––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
さて、盛況で終わったSXSW 2018から帰国後の打ち上げにて、次はどうするかが話題に上がりました。
- 『単調なラップは出来たけど、やっぱりメロディを歌ってほしい』
- 『毎回同じBGMじゃなくて、1人1人全く違うオリジナルの曲を歌ってほしい』
- 『8月にテレビ朝日の夏祭りイベントで、2週間ほど連続稼働させてほしい』
僕は、やっぱり、
うっすらと『コレハ、タイヘンダナァ』と思いました。
幸いBGMの生成については、先のSXSW 2018でAmper MusicというAI作曲サービスを運営する会社と仲良くなっていた為、そこのAPIを使わせてもらうことで、ある程度解消しそうな目処が立ちました。
しかし
Amper Musicはあくまでインスト曲(歌のない曲)しか生成してくれないので、
-
歌詞を考えて、(来場者との会話の内容に基づいて)
-
メロディーを作って、(Amper Musicの生成した曲のリズムとコードに乗るように)
-
それを歌う。(ゴーちゃん。の声で)
-
リアルタイムで。(わーい)
ゴーちゃん。の声で、、、
歌う??????
これはもう自分で歌声合成エンジン(ボー○ロイド的なやつ)を作るしかありません。
歌声合成: 録音・編集
実は僕はひょんなことから以前に一度、
自分の声を50音録音して、
自由に歌わせるシステムを趣味で作ったことがありました。
この時の経験から、一つのひらがなについて何個か高さのパターンを録っておかないと、ピッチシフトをした時にフォルマントが崩れてケロケロとした声になることが分かっていました。
そこで下記の図のように、

全音音階で1オクターブ分収録し、それぞれの音についてピッチシフトを100セントずつ許容することで、 G#3-A#4までの15音高を均一に獲得することができました。
オカリナより少し狭いぐらいの音域ですが、このぐらいあれば十分メロディを奏でられますね。
実際には、「あ」〜「ん」までの他に、濁音などを追加で収録したので、音声ファイルは合計で700ぐらいになりました。
しかしながら勿論このままの状態だと、それぞれの音声のレベルがバラバラだったり、ピッチが揺れていたりして、とても歌詞を聞き取れる状態ではないので、全てのサウンドファイルについて、ノーマライズ、イコライジング、ピッチの平坦化などを行いました。
これらの調整は、最後にはバッチ処理で全てのファイルに自動でかけられるようにしましたが、その前の検証段階では、Cubase(音楽制作ソフト)で実際にサウンドファイルを切り貼りして、地道な検証が続きました。
何も処理をせずに音声ファイルを並べた時の様子。
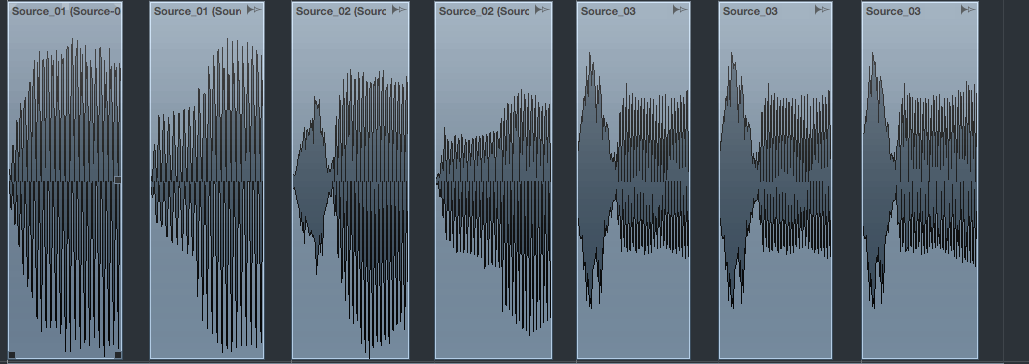
生のファイルだと音量がまばらなことがわかります。慣れてくると波形を見るだけでだいたい何の音か分かるようになってくるので、人間とは不思議な生き物です。
おまけ:
ちなみに、後日「てぃ」を収録し忘れた事が発覚して冷や汗をかいたのですが、「て」と「い」の波形を人工的に合成してみたらうまくいきました。私たちの中ではキメラ音と呼ばれています。
歌声合成: システム
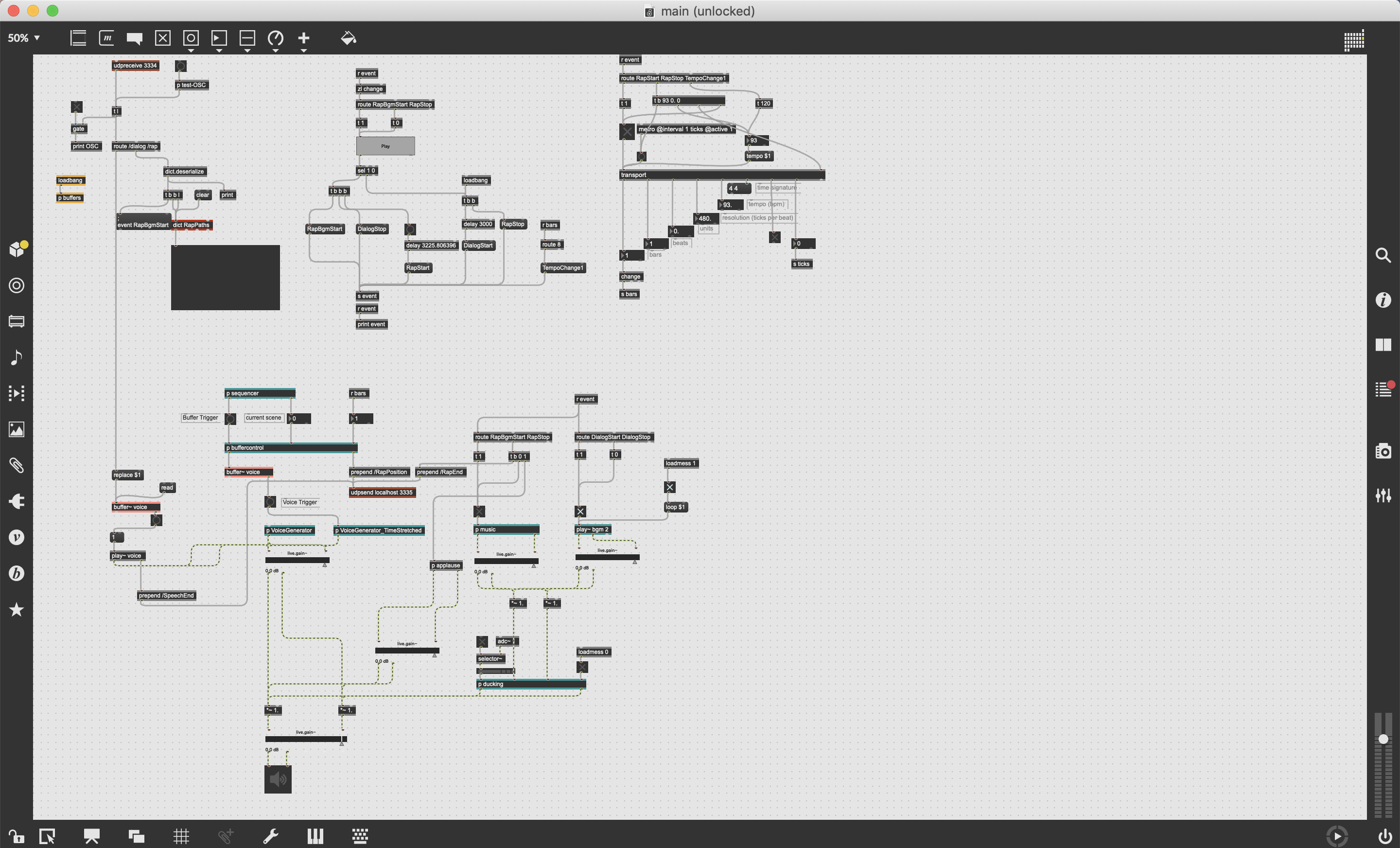
さて、これらの入念な下処理をしたサウンドファイル群を、必要に応じてロードし、ピッチシフトし、クロスフェードをかけ、タイミングよく鳴らして止めるシステムが必要です。
AIゴーちゃん。のメインシステムから歌詞やコードの情報など受け取りやすく、尚且つ、本番用のコンピューターにデプロイしやすい方法として、Webの技術を選択しました。
Web Audio API自体も既に使いやすく素晴らしい技術なのですが、サンプラーやトランスポートの実装をより素早くする為に、Tone.jsを使ってみました。
そしてこれは、大正解でした。
というのも、
var sampler = new Tone.Sampler({
"C3" : "path/to/C3.mp3",
"D#3" : "path/to/Dsharp3.mp3",
"F#3" : "path/to/Fsharp3.mp3",
"A3" : "path/to/A3.mp3",
}, function(){
//sampler will repitch the closest sample
sampler.triggerAttack("D3")
})
このように書くだけで、勝手にサウンドファイルを音域上にマッピングしたサンプラーが出来上がる為(Kontaktみたいな感じ)、自分でピッチシフトの制御を書かずに済み、しかもローダーが一瞬で出来上がりました。
メロディを生成する
歌を歌うのに必要な条件ってなんでしょうか?
- 歌詞
- 音の高さ
- 音の長さ
- タイミング
この辺りが揃っていれば、最低限の"スコア"と呼ぶ事ができそうです。
そこで、
{
notes: [
{
char: 'あ',
pitch: 'C4',
dur: '8n',
position: [0, 0, 0]
},
{
char: 'い',
pitch: 'C4',
dur: '8n',
position: [0, 1, 0]
},
{
char: 'う',
pitch: 'G4',
dur: '8n',
position: [0, 2, 0]
}
]
}
↓↓↓

このような形でスコアのオブジェクトを定義し、これを受け取って再生する部分をまず実装しました。
厄介なのは、メロディそのものです。
メロディを生成する方針として、
- 歌詞は小節ごとに区切って生成されるので、1小節ずつ処理する
- その小節に割り当てられた歌詞の音節数からリズムを作る。
- たとえば"わ・た・し”なら、「4分音符・4分音符・2分音符」など
- メロディラインを作る
- まず、
-1.0 ~ 1.0に正規化された数値の連続でメロディの動きを作る- たとえば
[-0.5, 0, 0.5]というメロディはまっすぐに上行するメロディを示す
- たとえば
- 次に、メインシステムから送られてくるAmper Musicのメタデータにコード進行の情報が入っているので、そのコードに合わせて、
ゴーちゃんの音域の範囲で実際のピッチを決定する- たとえば
C majorというコードが入っていたら、[-0.5, 0. 0.5] => ['C4', 'E4', 'G4']のように変換される
- たとえば
- まず、
- 2.で作ったリズム(=発音タイミング)と3.で作ったピッチを合成し、スケジューラーに登録する
メロディを作るシステムとしては幾分プリミティブですが、どのみちこのぐらいの尺と音域だとあまり凝っても意味がないので、今回はこのような形で実装しました。
オペレーションについて
歌のバージョンのAIゴーちゃん。は、若葉台キャラクターランドで行われる夏祭りイベントの為に作られました。稼働期間が2週間と長かった為、安全に稼働する為にいくつか留意する点がありました。
- 実際には起動しっぱなしにするものの、万が一落ちた時の為に、ワンクリックで全てのアプリケーションが立ち上がるように起動スクリプトを用意する
- なんらかの事情で重くなった時の為に、叩くとリロードできるUSBのボタンを用意する(現場スタッフ用)
- 歌声合成アプリはwebで動かしている為、何もしないとクラッシュ時の原因がリモートで把握できないので、
console.logやconsole.errorを改造して外部のサーバーに全てのログを飛ばすようにする - どうしようもなくなった時の為に、本番機にリモートログインできるようにしておく
- 熱でコンピューターがやられないように、外付けの冷却ファンを常に2台回す
このように万全な準備を重ねたおかげで、初めての試みだったにも関わらず、
本番期間中ほとんどクラッシュすることもなく無事に沢山の子供たちに歌と笑顔を届けることができました🎉🎉