こんにちは、Mottyです。
最近kaggleを初めましたので、必須であるPandasを使ったデータ加工の簡単な操作を記事にまとめていきたいと思います('`)。
・Kaggle公式HP
https://www.kaggle.com/
・Pandas UserGuide
https://pandas.pydata.org/docs/user_guide/index.html
概要
PandasはPythonのデータ加工ライブラリです。テーブルの操作や集計、欠損値の補完などが簡単に行えます。他にも列を結合したり相関行列を表示したり、クロス集計できたり・・・と様々です。

使用するデータ
kaggle定番ですが、タイタニックの生存状況に関するデータを使用します。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib.inline
import pandas as pd
df_train = pd.read_csv("train.csv")
データの確認
df_train.columns #項目リスト
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
df_train.shape #サイズ
(891,12) 行列のサイズですね。
先頭の5行だけ覗いてみましょう。
df_train.head()
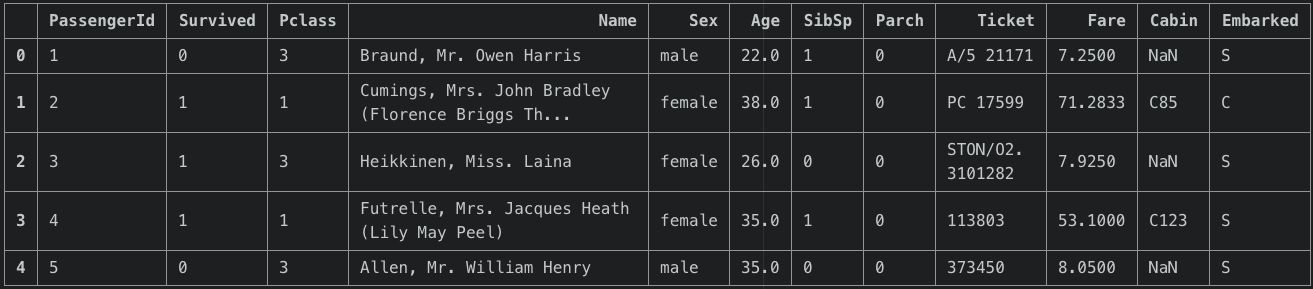
量的データと質的データが混在していますね。(PClassも互いに量的な関係ではないので質的データと見なせますね!。)
列/行の抽出
df_train["Name"] #1列抽出
df_train.loc[:,["Name","Sex"]] #複数列抽出
df_train[10:15] #行抽出
df_train[10:20:2] #1行飛ばし
df_train[df_train["Age"] < 20] #値指定
df_train[1:300].query('Age < 20 and Sex == "male"') #queryで複数条件指定
集計
df_train["Pclass"].value_counts()
3 491
1 216
2 184
Name: Pclass, dtype: int64
各項目についての集計結果を返してくれます。
欠損値の確認
df_train.isnull() #True→欠損値
df_train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
各列項目のNaNの合計数が一覧で得られます。これを基に欠損値補完の方針を立てていきます。
相関行列の表示
相関行列は各変数間の相関係数です。
df_train.corr() #相関係数の表示
PassengerId Survived Pclass Age SibSp Parch Fare
PassengerId 1.000000 -0.005007 -0.035144 0.036847 -0.057527 -0.001652 0.012658
Survived -0.005007 1.000000 -0.338481 -0.077221 -0.035322 0.081629 0.257307
Pclass -0.035144 -0.338481 1.000000 -0.369226 0.083081 0.018443 -0.549500
Age 0.036847 -0.077221 -0.369226 1.000000 -0.308247 -0.189119 0.096067
SibSp -0.057527 -0.035322 0.083081 -0.308247 1.000000 0.414838 0.159651
Parch -0.001652 0.081629 0.018443 -0.189119 0.414838 1.000000 0.216225
Fare 0.012658 0.257307 -0.549500 0.096067 0.159651 0.216225 1.000000
対角成分は自分自身との相関となるので必ず1となります。しかし量的データだけでなく、文字列(Sex,Embark)や数字を使った質的データ(Pclass)などがありこれらをone-hot表現に変換してあげなければなりません。
dummy_df = pd.get_dummies(df_train, columns = ["Sex","Embarked","Pclass"]) #ダミー変数の取得
dummy_df.columns
Index(['PassengerId', 'Survived', 'Name', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q',
'Embarked_S', 'Pclass_1', 'Pclass_2', 'Pclass_3'],
dtype='object')
dummy_df.corr()
巨大なので書きませんが、先ほどの相関行列は文字列データについては省かれていました。今回は質的変数をダミー(0,1)に置き換えたものとの相関行列が返ってきます。
可視化
seabornのHeatMapを使って相関行列をみてみましょう。カラーパレットは、0を中心として色の濃さが対照的なを選びました。
import seaborn as sns
plt.figure(figsize = (12,10))
sns.heatmap(dummy_df.corr(), cmap = "seismic",vmin = -1 ,vmax = 1, annot = True)
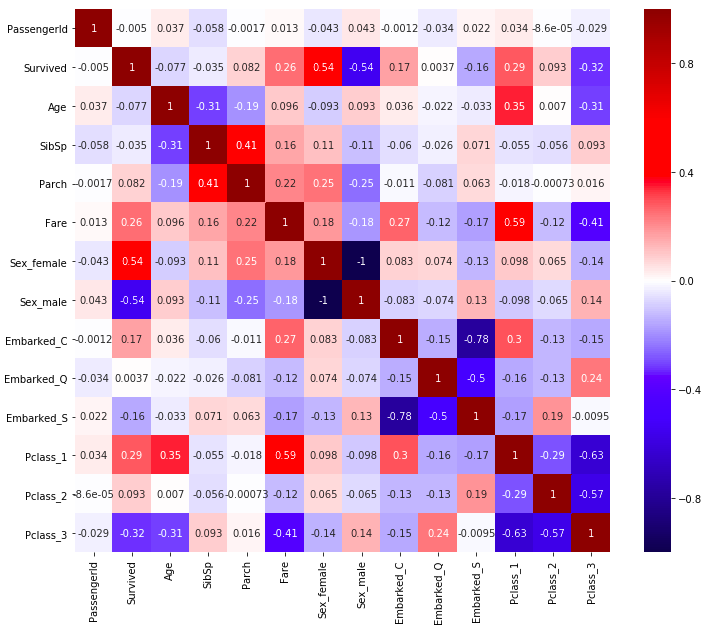
Servivedと高い相関関係にあるものが、Servivedに影響を及ぼしていると考えることができます。Sex_femaleとPclass_1との相関が高いですね。これは女性であったり部屋の階級が1である人の生存率が高いということになります。
うまく使ってあげれば機械学習の前段階で方針の目星はつけることもできるということですね!
参考文献
以下の記事を参考にさせていただきました。
参考URL
・データ分析で頻出のPandas基本操作
https://qiita.com/ysdyt/items/9ccca82fc5b504e7913a
・追伸。そろそろおまえもseabornヒートマップを使うように。 母より
https://qiita.com/hiroyuki_kageyama/items/00d0f52724f16ad7cf77
参考書籍
前処理大全[データ分析のためのSQL/R/Python実践テクニック]
現場で使える!pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法
終わりに
単にデータ処理だけならNumpy配列に入れるだけでもできるんじゃないの?と思っていましたが、データ加工が簡単にできるのが魅力ですね。逆にDataFrameに対して高度な計算を行うのであれば1度配列に移したほうがいいのかも・・・?