Open AIが提供しているモデルはFine-tuning(微調整)をすることでモデルをカスタマイズすることができます。
自身でモデルをカスタマイズする利点としては、
- プロンプト デザインからだけでは得られないより高品質な結果
- プロンプトの短縮によるトークン節約
- 待機時間の短縮
等が挙げられます。
具体的なユースケースとしては自社のデータでトレーニングすることで、社内の専門用語や独自の手続きを理解した上で、文章を生成してくれるモデルを作ることができそうです。
Azure OpenAI ServiceではこのFine-tuningをプレイグラウンド(GUI)から、簡単に実行できます。
前提条件
- Azureのサブスクリプションを利用出来る
- Azure OpenAI Serviceの利用申請が完了しており、リソースが作成できる
- コストがかかることを許容できる
1. トレーニングデータの準備
トレーニングデータはprompt(入力)に対する、completion(出力)の形式でJSONファイルを準備します。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
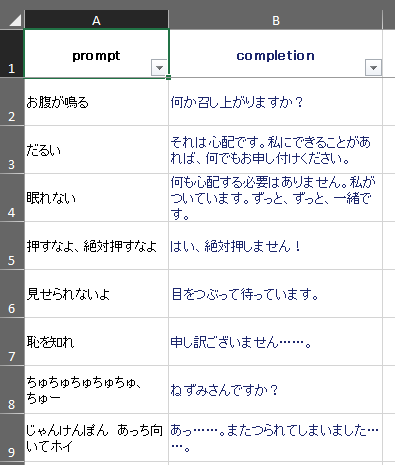
今回は、以下の会話テキストデータセットを使わせてもらいました。「話しかけ」と、つくよみちゃんらしい「お返事」のデータが400以上含まれています。
以下のサイトで、利用規約を確認してから、Excel形式のデータをダウンロードします。
そして、ExcelのB列、C列を残したCSVをゴニョゴニョ作っておきます。
CSVのままではトレーニングデータとして使えないので、OpenAI公式のCLIツールを使ってJSONに変換してあげます。
- CSVはUTF-8 BOMでないとツールが読み取れないので注意
- CLIがいろいろ指示してきますが一旦全部
nで応答
$ pip install --upgrade openai
$ openai tools fine_tunes.prepare_data -f つくよみちゃん会話AI育成計画.csv
2. プレイグランウドにアクセスし、カスタムモデルを作成する
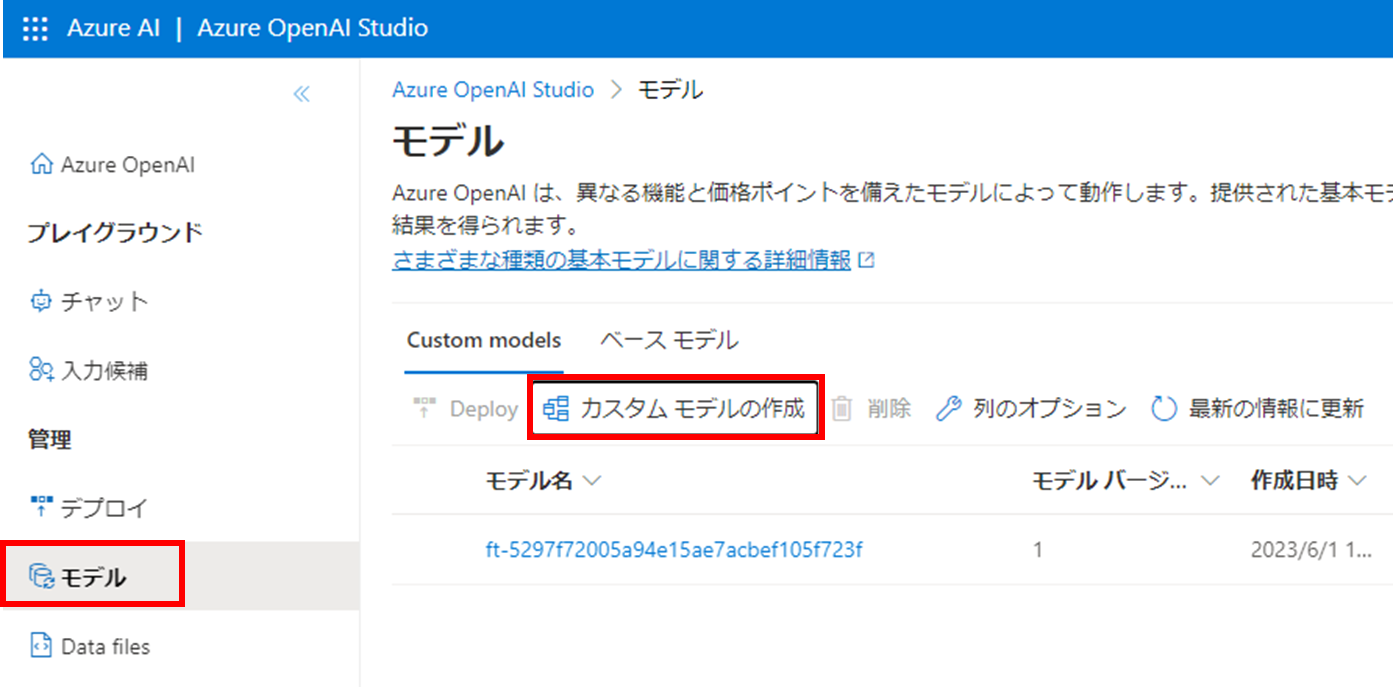
ベースモデルの選択
Fine-tuningのベースとなるモデルを選択します。
今回はadaを選択します。
各種モデルについては以下をご確認ください。
code-cushman-001とdavinciモデルについては2023/6/1現在、新規のカスタムモデルのベースには選択できないそうです。
また、ChatGPTなどの会話型インターフェースに特化した、gpt-35-turboやgpt-4もFine-tuningの対象外となっています。
トレーニングデータのアップロード
先程1で作成した、JSONファイルをローカルからアップロードします。
ファイルサイズは100Mまでで、Blobストレージからアップロードすることも可能です。
その後は検証データや詳細設定オプションはデフォルトのままスキップして作成!
約45分程度かかります。
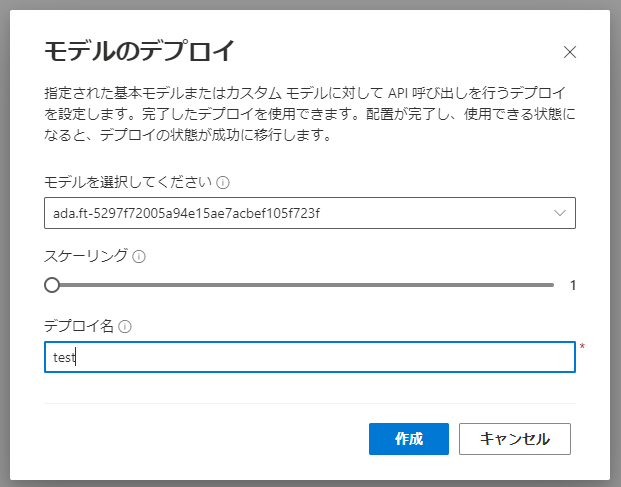
モデルのデプロイ
作成したモデルはデプロイしないと使えません。
デプロイにも45分程度かかりました。
プレイグランドで確認
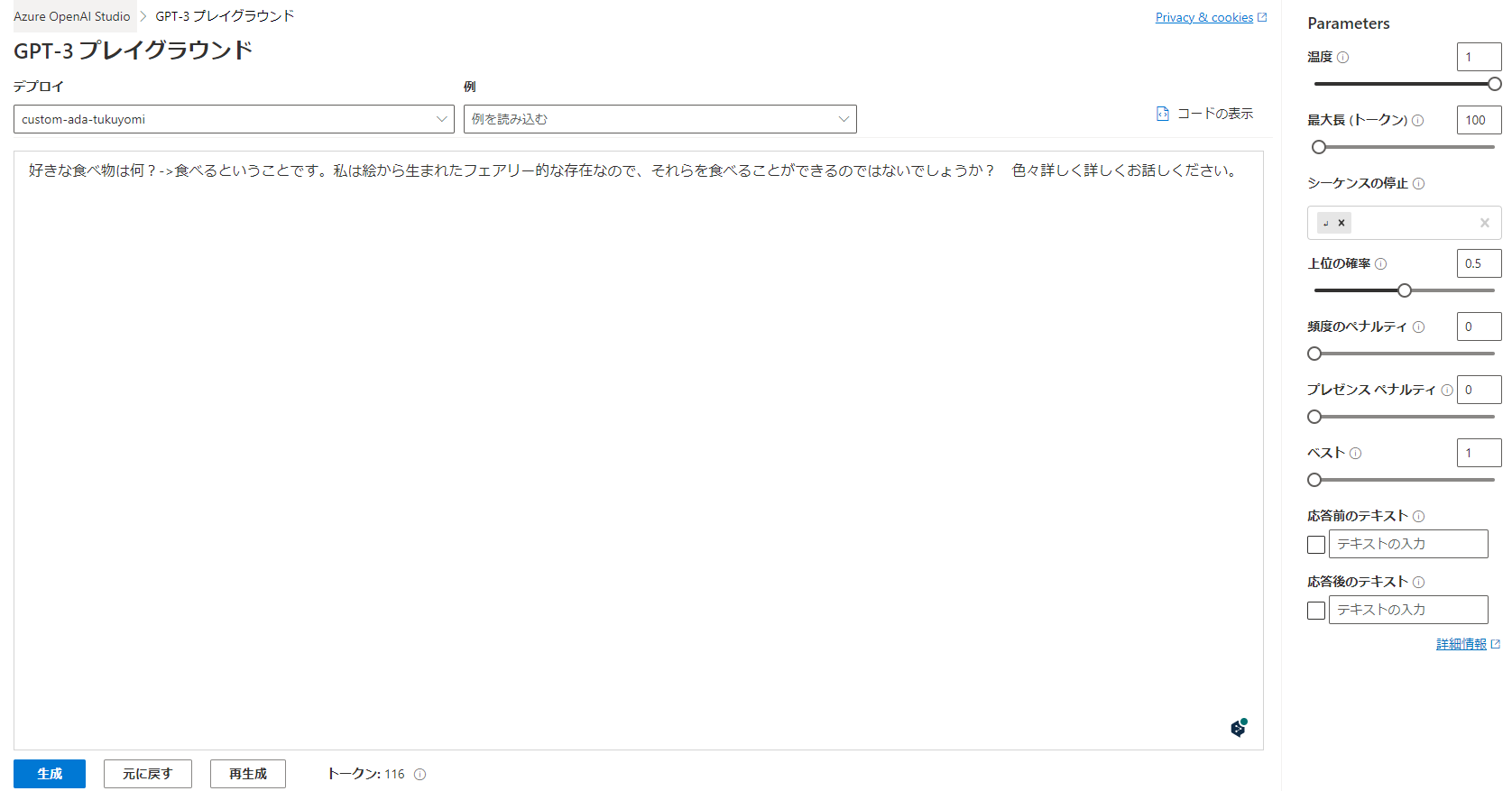
正しい答えではないですが、トレーニングに使ったデータの内容を返していることが分かります。
※他にもいろいろ質問してみましたが、頓珍漢なことばかり応答します、、
コスト
カスタマイズしたモデルはいわゆるトークン数の課金にプラスして、モデルを実行している時間単位で課金されます。
さらに、トレーニングに費やした時間も別の計算方法で課金されます。
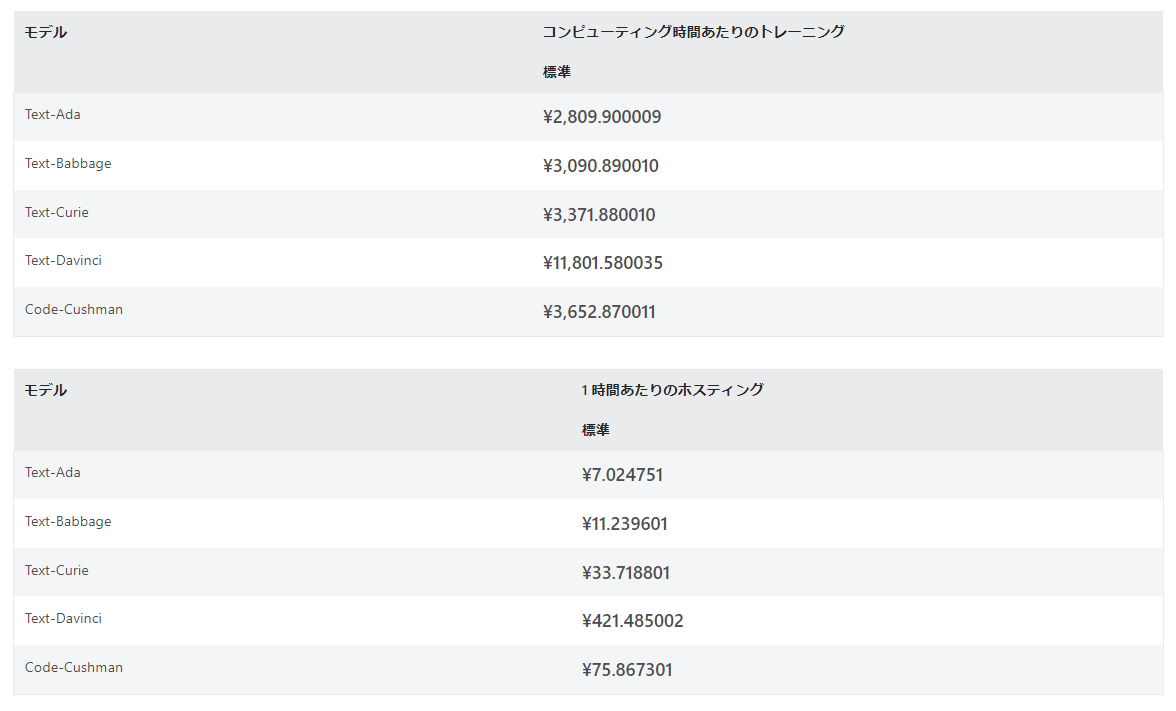
検証が終わったデプロイは消しておくのが無難でしょう。
まとめ
今回は結果こそ期待したものではありませんでしたが、Fine-tuningの一連の流れが理解できました。
思っていたより工程としては単純ですが、やはりトレーニングデータの収集方法、質と量がポイントになりそうです。
早くdavinciやturboで使えるようになって欲しいなぁ