Azure Form recognizerというサービスがあります。
https://azure.microsoft.com/ja-jp/services/cognitive-services/form-recognizer/
帳票をいい感じに読み取って狙ったデータを抽出してくれる優れものです。APIもあるので複数の帳票をまとめて処理できるPython scriptを書いてみました
https://github.com/yosukearaiMS13/formrecognizerbatch/blob/master/fy.py
以下、スクリプトの中身と使い方について説明します
スクリプトの中身
スクリプトは、ドキュメントにあるサンプルを拡張して作っています
https://docs.microsoft.com/ja-jp/azure/cognitive-services/form-recognizer/quickstarts/python-labeled-data?tabs=v2-0
スクリプトは4つのsectionから構成されています
https://github.com/yosukearaiMS13/formrecognizerbatch/blob/master/fy.py
# Configurations: 各種設定パラメータ
# Post 分析対象pdf section
## Form recognizerに対し、分析対象データを一旦全部postします
# Get analyze results section
## 先ほどpostしたデータの分析結果(抽出されたデータ含む)を取得します。
# 抽出結果のcsv出力 section
## 抽出結果を出力します。余計な空白の除去と、信頼性が低い抽出値の置き換え
## (しきい値以下の場合抽出値は採用せず、代わりに信頼度を[]囲みで出力)
## を行っています
Get analyze resultsと抽出結果のcsv出力sectionでは、Form recognizerから返されたjsonをパースしています。jsonのフォーマットはこちらです
https://github.com/Azure-Samples/cognitive-services-REST-api-samples/blob/master/curl/form-recognizer/Invoice_1.pdf.ocr.json
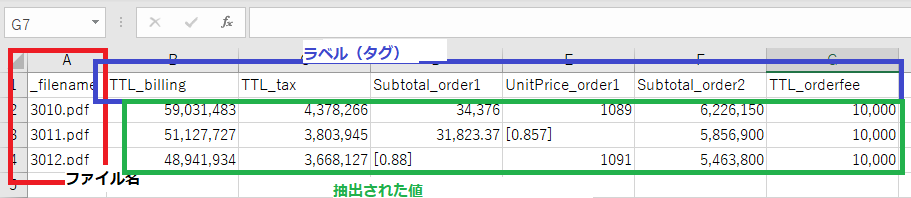
出力されるcsvのフォーマットは以下です。
- 先頭列: 分析対象の帳票ファイル名
- 2列目以降: 分析モデルに設定した全ラベル(タグ)と、それに対応する抽出値
各セクションで利用しているAPIは以下です
- Post 分析対象pdf: Analyze Form
- Get analyze results: Get Analyze Form Result
- CSV出力section: Get Custom Model
- 当該APIにて定義済みの全ラベルを取得し、csvのヘッダの値として使用しています
スクリプトの使い方
1. 環境
Win10 Enterprise, Python 3.8.5, IDEは任意
2. データ抽出準備
(※前提作業~データ抽出準備1までは、こちらのQiita記事も参考になります)
-
前提作業: 以下を先にやっておきます
- Form Recognizer リソースの作成
- Azure blobの作成(ストレージアカウントの作成->コンテナの作成まで)
-
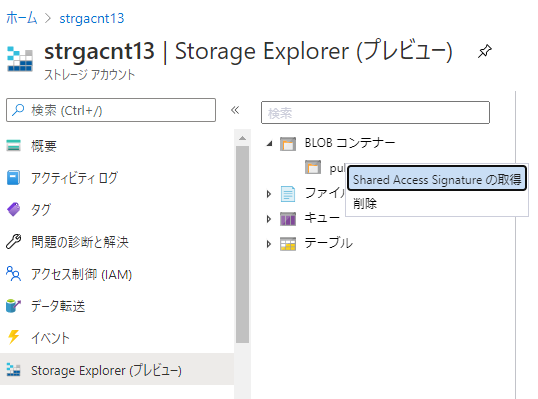
Azure blobの設定(Shared Access Signatureの作成)(Azure PortalのStorage Explorerメニューを使うと便利です)
- (アクセス許可の欄は全てcheckします)
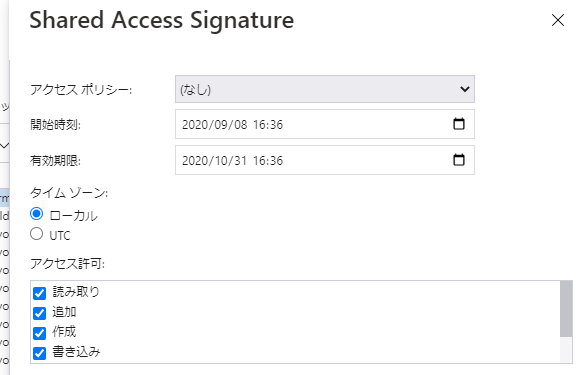
- (生成されたURL値を後から使いますので、保存しておいてください)

-
データ抽出準備1(初回のみ実施)
-
モデル作成用のトレーニングデータをAzure blobに格納する: 以下の形で最低5ファイル(この場合invoice_1~5.pdf)を配置ください(xx.jsonは後から作られるファイルですのでここでは無視)
-
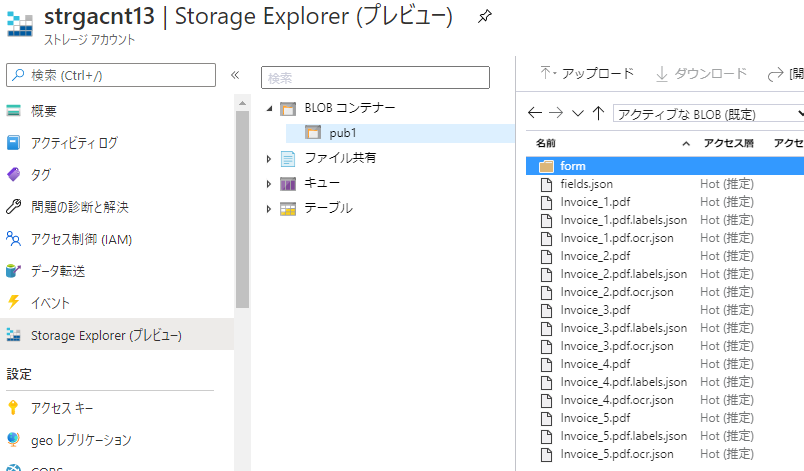
-
ラベル(タグ)付けツールの設定:
- ラベル付けツールはこちら https://fott.azurewebsites.net/
- ラベル付け手順: 以下ドキュメントの手順に従い、ラベル付けツールへの接続->プロジェクト作成、まで実施
-
pythonスクリプトへの設定#1
-
## Configurations
endpoint = r"https://xxxxx.cognitiveservices.azure.com/"
apim_key = "xxxxx"
model_id = "xxxxx"
sourceDir = r"C:\xxxxx\*"
confidence_setting = 0.9 # 0~1. 信頼性がこの値以下の場合採用しない
- endpoint: Form Recognizerのエンドポイント
- apim_key: Form Recognizerのキー1 or 2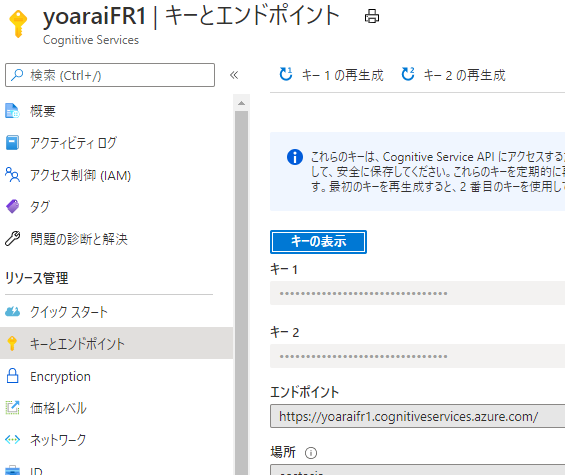
- sourceDir: 分析対象の帳票ファイルの配置場所をフルパスで記述
- confidence_setting: 0~1の値を設定(※スクリプトの仕様として、信頼性がこの値以下の場合抽出された値は採用せず、代わりに信頼性の評価値を[]囲みで出力する仕様にしています)
- データ抽出準備2(ラベルを追加修正する度に実施)
- ラベル(タグ)付けツール(https://fott.azurewebsites.net/)にて、読み込まれたトレーニングデータ(帳票)にラベルをつけていく。つけ終わったらTrainして、モデルを生成する
- 以下ドキュメントの手順: フォームにラベルを付ける-> カスタム モデルをトレーニングする、まで実施
- こちらのQiita記事 の手順も参考になります
- Train後Model IDが生成されます(以下)。この値は後で使います
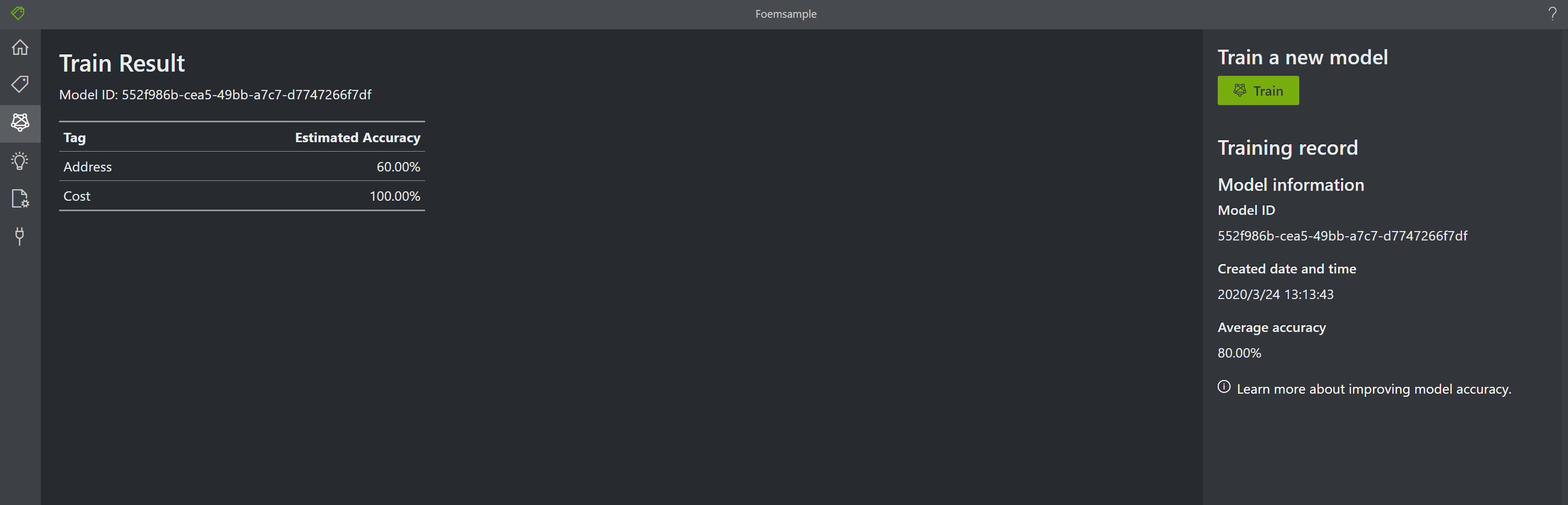
- pythonスクリプトへの設定#2: model_id
- ラベル(タグ)付けツール(https://fott.azurewebsites.net/)にて、読み込まれたトレーニングデータ(帳票)にラベルをつけていく。つけ終わったらTrainして、モデルを生成する
## Configurations
endpoint = r"https://xxxxx.cognitiveservices.azure.com/"
apim_key = "xxxxx"
model_id = "xxxxx"
sourceDir = r"C:\xxxxx\*"
confidence_setting = 0.9 # 0~1. 信頼性がこの値以下の場合採用しない
- Model_id: 上記で取得したModel IDをセットします
3.データ抽出実施
- sourceDirに分析対象の帳票ファイルを配置する
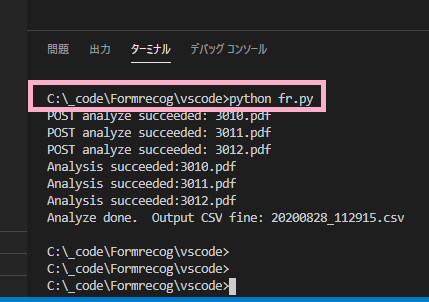
- fr.pyを実行
- スクリプトと同じフォルダにデータ抽出結果csvが出力されます
4. 制約など
- トレーニング及び分析対象帳票のファイル形式ですが、PDFしか試していません
- Form recognizerの現行バージョンv2.0ベースで作っています。他バージョンで使う場合、APIのURLの適宜変更と、Form recognizerが返すjsonフォーマット変更への対応が必要になると思います