今回は Microsoft の AI、Form Recognizer の新機能である「カスタマイズ」を試してみたいと思います。この機能は 2020 年 3月 17 日の Azure Blog で紹介された新しい機能です。
(参考Blog) New features for Form Recognizer now available
https://azure.microsoft.com/ja-jp/blog/new-features-for-form-recognizer-now-available/
そもそも Form Recognizer 自体、 2019 年 5 月からプレビューリリースされている新リソースとなるので、そもそも何ができるのかという点から触れていきたいと思います。
Form Recognizer とは
Form Recognizer は 2019 年 5月よりプレビューリリースされて Azure の Cognitive Service のひとつです。Microsoft の公式ドキュメントには以下の様な記載があります。
Azure Form Recognizer は、機械学習テクノロジを使用して、フォーム ドキュメントからテキストや、キーと値のペア、テーブル データを識別して抽出するコグニティブ サービスです。 フォームからテキストを取り込んで、元のファイル内の関係を含む構造化データを出力します。 手作業による操作やデータ サイエンスに関する専門知識があまりなくても、特定のコンテンツに合わせた正確な結果がすばやく得られます。 Form Recognizer は、カスタム モデル、あらかじめ構築されたレシート モデル、Layout API から成ります。 REST API を使用して Form Recognizer モデルを呼び出すことにより、複雑さを軽減し、自分のワークフローやアプリケーションに統合することができます。
(参考)Form Recognizer とは
https://docs.microsoft.com/ja-jp/azure/cognitive-services/form-recognizer/overview
要は、「Form Recognizer は、フォームに入力された内容を認識してくれる AI で、人がいままでやってきた面倒な作業を代わりにやってくれる優れモノ☆」ということです。(笑)
ちょっと長くて読むのめんどくさいなと思った方は、以下のリンクにコンセプト動画あります。英語ですが良く纏まっているので是非ご覧ください。
(参考) Learn about AI-powered robotic process automation with Form Recognizer
https://channel9.msdn.com/Shows/AI-Show/Learn-about-AI-powered-robotic-process-automation-with-Form-Recognizer
Form Recognizer には現在3つの機能があります。
- カスタム モデル - フォームからキーと値のペアおよびテーブル データを抽出します。 これらのモデルは自分が用意した独自のデータでトレーニングされるため、実際のフォームに合わせて調整されます。
- あらかじめ構築されたレシート モデル - 事前構築済みモデルを使用して米国のレシートからデータを抽出します。
- Layout API - テキストおよびテーブルの構造を、対応する境界ボックスの座標と共にドキュメントから抽出します。
これまで「カスタムモデル」を作成するためには Python 環境をローカルに準備し、Python のコードベースで開発をする必要がありました。ですがこの3月にリリースした新機能「カスタマイズ」によってかなり簡単な UI でカスタムモデルを作成することが可能になりました。それでは実際に試して見ましょう!
新機能「カスタマイズ」を使ってみる
新機能「カスタマイズ」を実際に試してみます。具体的な方法は以下の Microsoft の GitHub に纏まっていますが、英語だったりところどころ省略している部分があったので、ちょっと詳しく見ていきたいと思います。
(参考) OCR Form Labeling Tool
https://github.com/microsoft/OCR-Form-Tools/blob/master/README.md
リソースを作成する
まずはリソースを作成します。今回 Azure 上で必要なリソースは以下の二つです。
- Form Recognizer リソース
- Azure Storage Account (Blob Storage リソース)
まず一つ目の Form Recognizer リソースですが、Azure Portal から「新しいリソースの作成」から選択することが可能です。(ちょっと前までは Dev に利用申請をする必要がありましたが、プレビュー版として Portal から作成出来る様になりました。)
二つ目の Blob も Azure Portal から作成します。この Blob はこれから Form Recognizer で使用するトレインデータやモデルを格納する場所となるので、Form Recognizer と同じリソースグループに纏めておくと便利です。
Azure Blob の設定を確認する
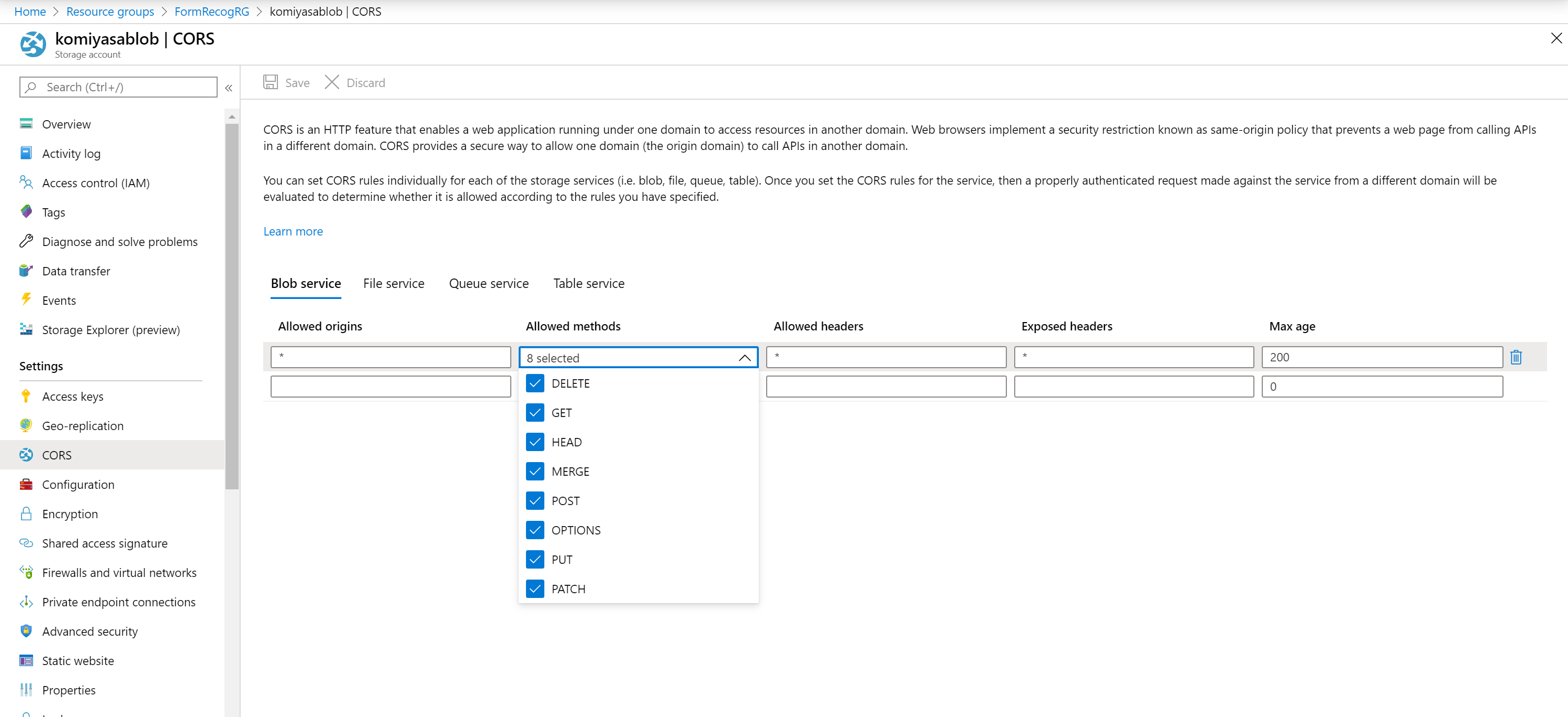
次に Azure Blob の設定を確認します。Form Recognizer が Blob を使用できるようにするには、CORS (cross-domain resource sharing) の設定が必要です。CORS は必要なだけ正しく設定するのが常套手段ですが、今回はドキュメントに従い以下の設定をします。
Allowed origins = *
Allowed methods = [select all]
Allowed headers = *
Exposed headers = *
Max age = 200
設定は Azure Storage Account の中の、「Settings」の「CORS」から設定することが出来ます。
次に Blob を準備します。Azure Storage Account の Container から Blob を作成します。名前は任意で大丈夫です。
ここまで完了したら、あとで Form Recognizer から使う SAS URI をコピーします。Storage Account の 「Shared access signature」にアクセスし、「Generate SAS and Connection String」をクリックすることで生成されます。
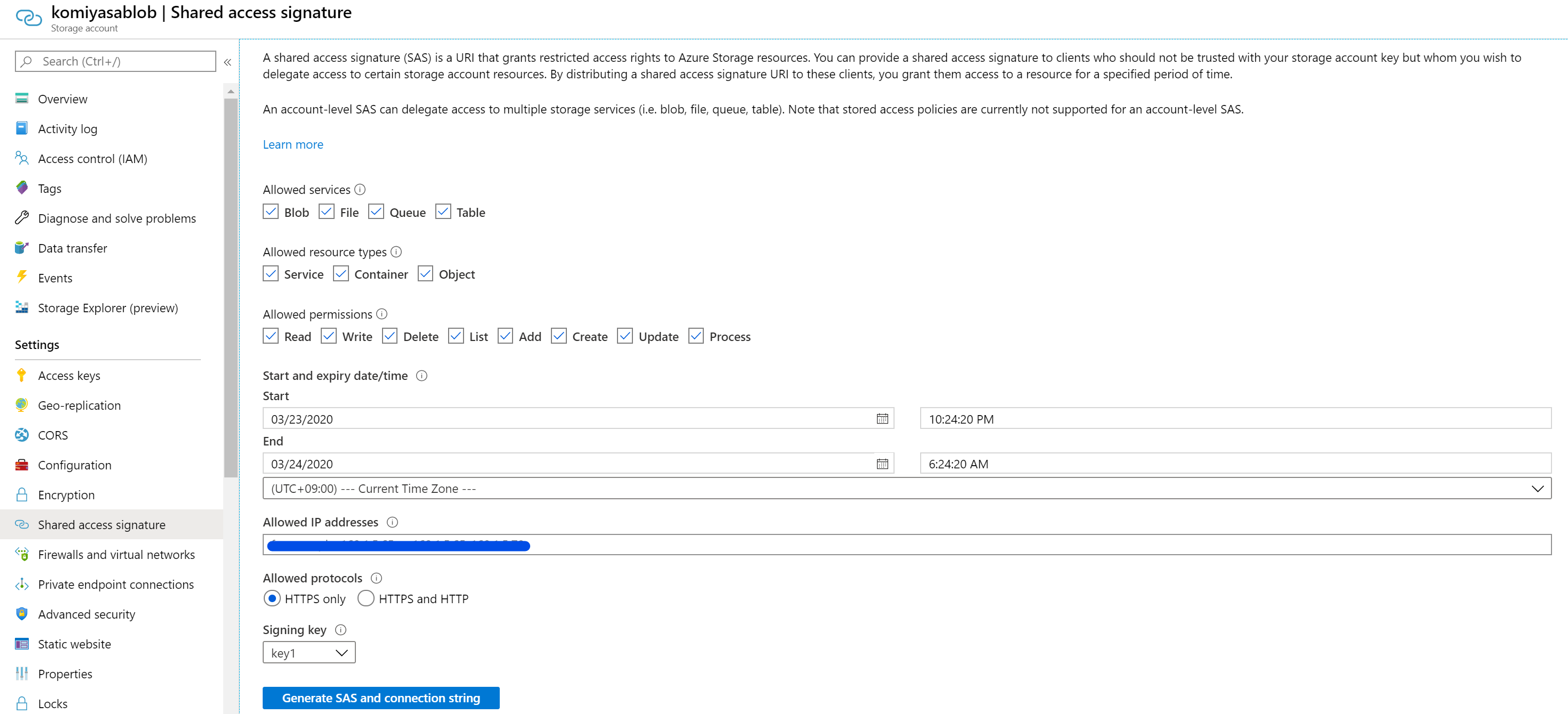
SAS については以下のドキュメントに説明が纏めてあります。
(参考) Shared Access Signatures (SAS) を使用して Azure Storage リソースへの制限付きアクセスを許可する
https://docs.microsoft.com/ja-jp/azure/storage/common/storage-sas-overview
このドキュメントにもあるように、SAS URI は以下のような構造になっています。

今回は 作成した Blob を指定するので、SAS Token の前の Storage Resource URI に「/作成した Blob の名前」を追加します。例えばこのような形です。
https://XXXXXXXXXXXX.blob.core.windows.net/komiyasablob(作成した Blob)?sv=SAS Token XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
URI が準備できたらメモ帳にでもコピペしておきましょう。
トレインデータを準備する
次に Form Recognizer に学習させるトレインデータを準備します。現在日本語はサポートしていないので、英語で、かつフォームが一定のデータを準備します。今回はサンプルということで、Microsoft の GitHub に公開されている領収書のサンプルデータを用意します。
(参考)MS GitHub に公開されている領収書データ
https://github.com/Azure-Samples/cognitive-services-REST-api-samples/blob/master/curl/form-recognizer/sample_data.zip
これらをローカルにダウンロードし、先ほど作成した Blob にアップロードしておきましょう。これでリソース類の準備は完了です。
カスタマイズするためのラベリングツールを準備する
カスタマイズを実行する方法としては、3点あります。ローカルに Node.js 環境が既にある場合は以下のコマンドを実行するだけでカスタマイズするための Modern UI の ラベリングツール が立ち上がります。今回はこの方法で実行しました。
git clone https://github.com/Microsoft/OCR-Form-Tools.git
cd OCR-Form-Tools
npm install
npm run build
npm run react-start
もし環境がない場合は、テスト試験的には以下のサイトで試すことも出来るみたいです。
(参考) ラベリングルーツの Web Site
https://fott.azurewebsites.net/
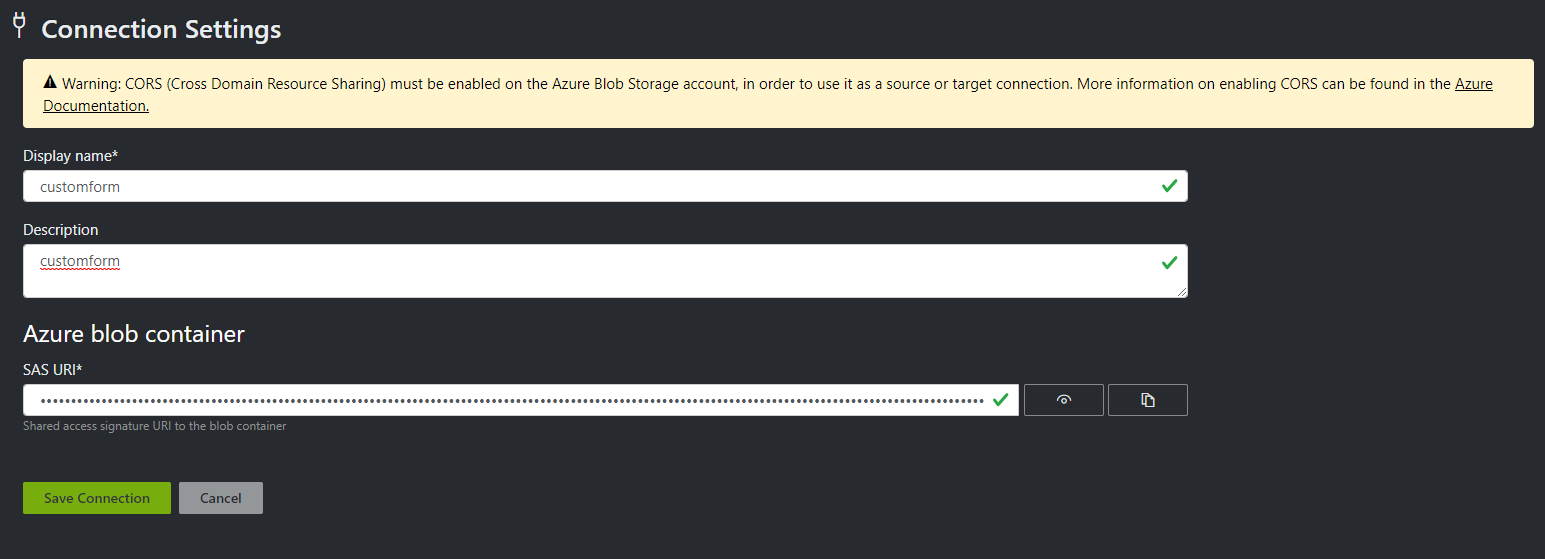
Azure Blob の Connection を設定する
まずは Connection String を設定する必要があります。Display Name は同一環境で識別するためのものなので任意で大丈夫です。Azure Blob Container のところに、先ほどメモ帳にコピペした SAS URI をコピペします。コピペできたら Save をしておきます。
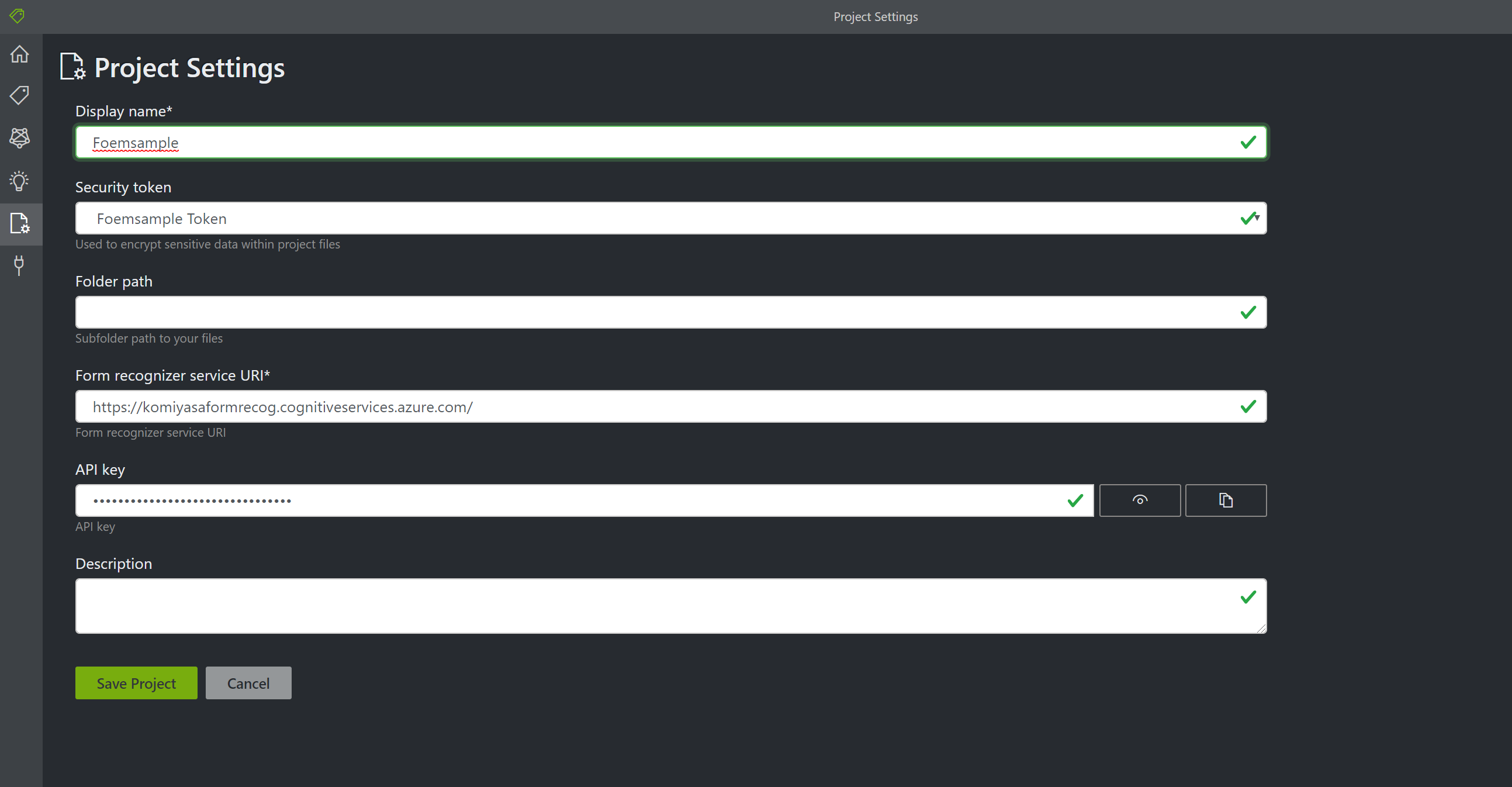
Project の設定をする
ラベリングツールの一番上のページに戻り新しいプロジェクトを作成します。ここで Form Recognizer を作成した際に発効された EndPoint URL と Key をコピペします。
Save Project をクリックすると、Azure Blob に格納されているフォームデータを基にしたトレーニングが始まります。自動的にモデルも作成され、Azure Blob 上に格納されます。(非常に便利ですね!)
カスタマイズを実行する
左のメニューの「Tag」を選択します。Tag を選択すると右側のメニューバーに新しい Tag を作成する「+」ボタンが見えます。今回は例えば「Cost」というタグを作成してみました。
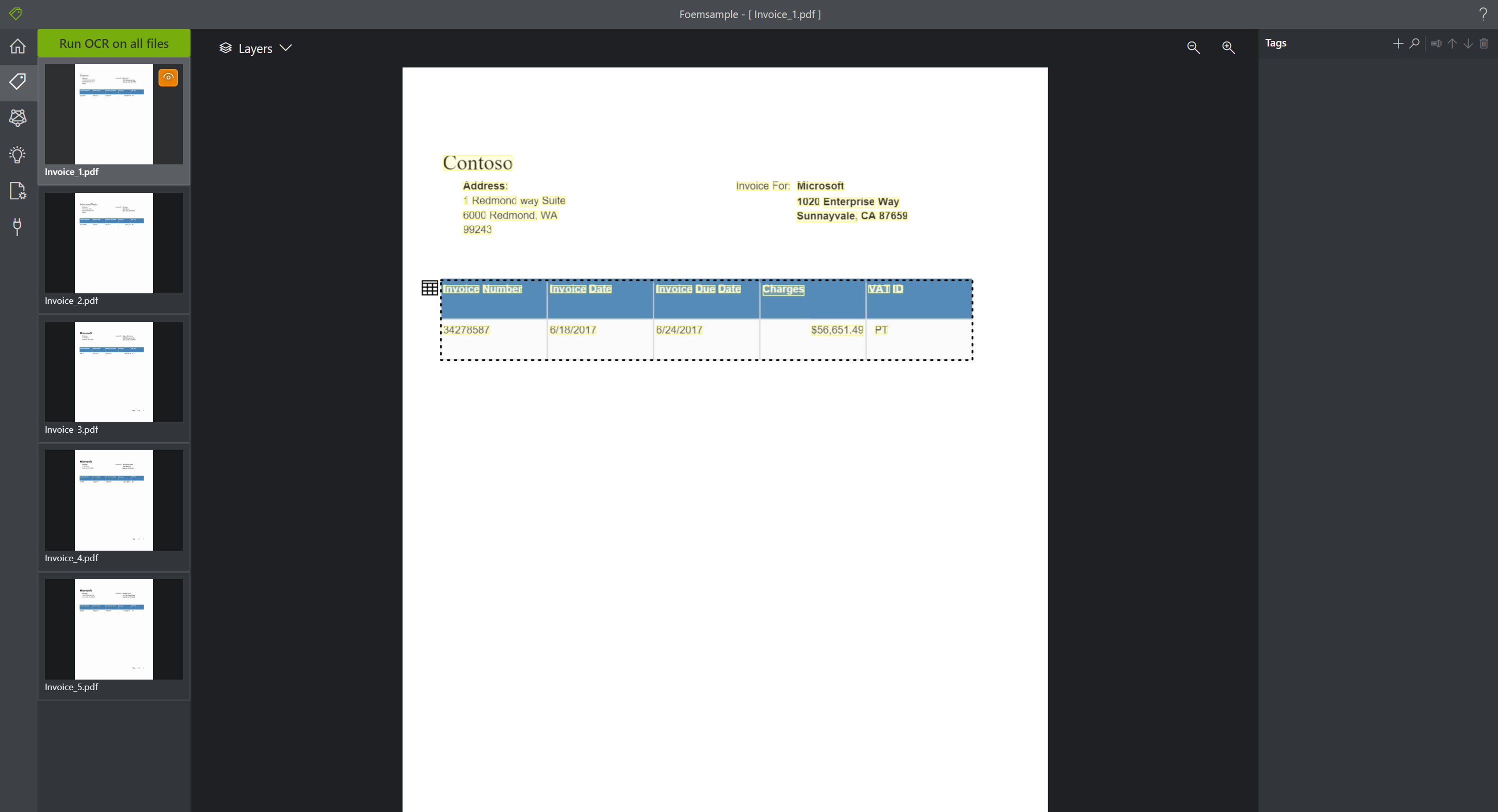
タグを作成できたら、真ん中の PDF の領収書が見えているところで、価格の書かれている文字を選択します。選択すると蛍光ペンでなぞったような色に変わります。蛍光ペンでフォーカスされているところを確認できたら、先ほど作成した左にある Tag の「Cost」をクリックします。このようにすると、領収書の中にある数字が、「Cost」というタグとして認識されます。他の4つのドキュメントについても同様の処理を加えます。
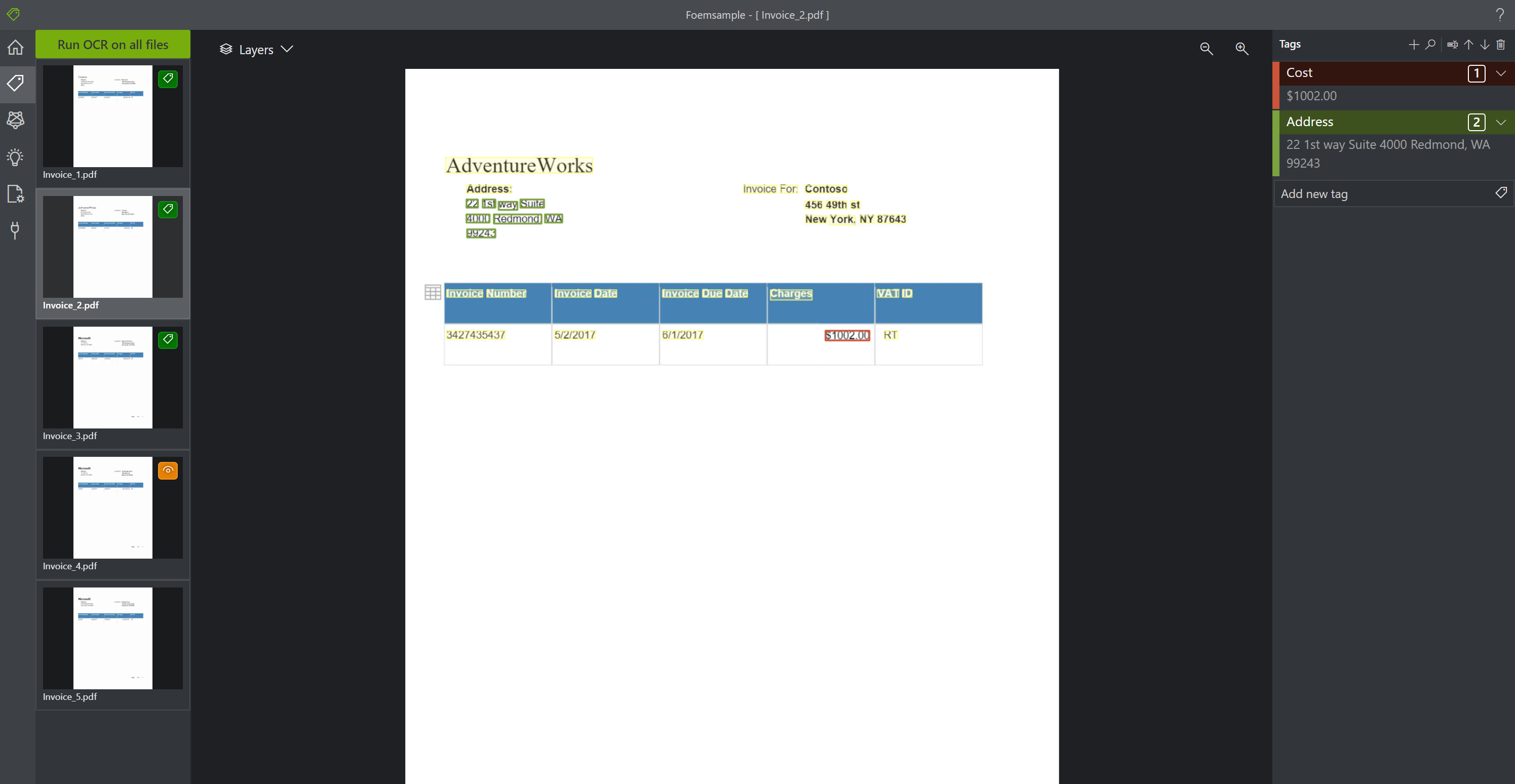
さらにもう一つ「address」という Tag を作成します。上記と同様の手順で、領収書のアドレスの部分を蛍光ペンでフォーカスし、作成したタグをクリックします。他のドキュメントについても同様の処理を加えます。
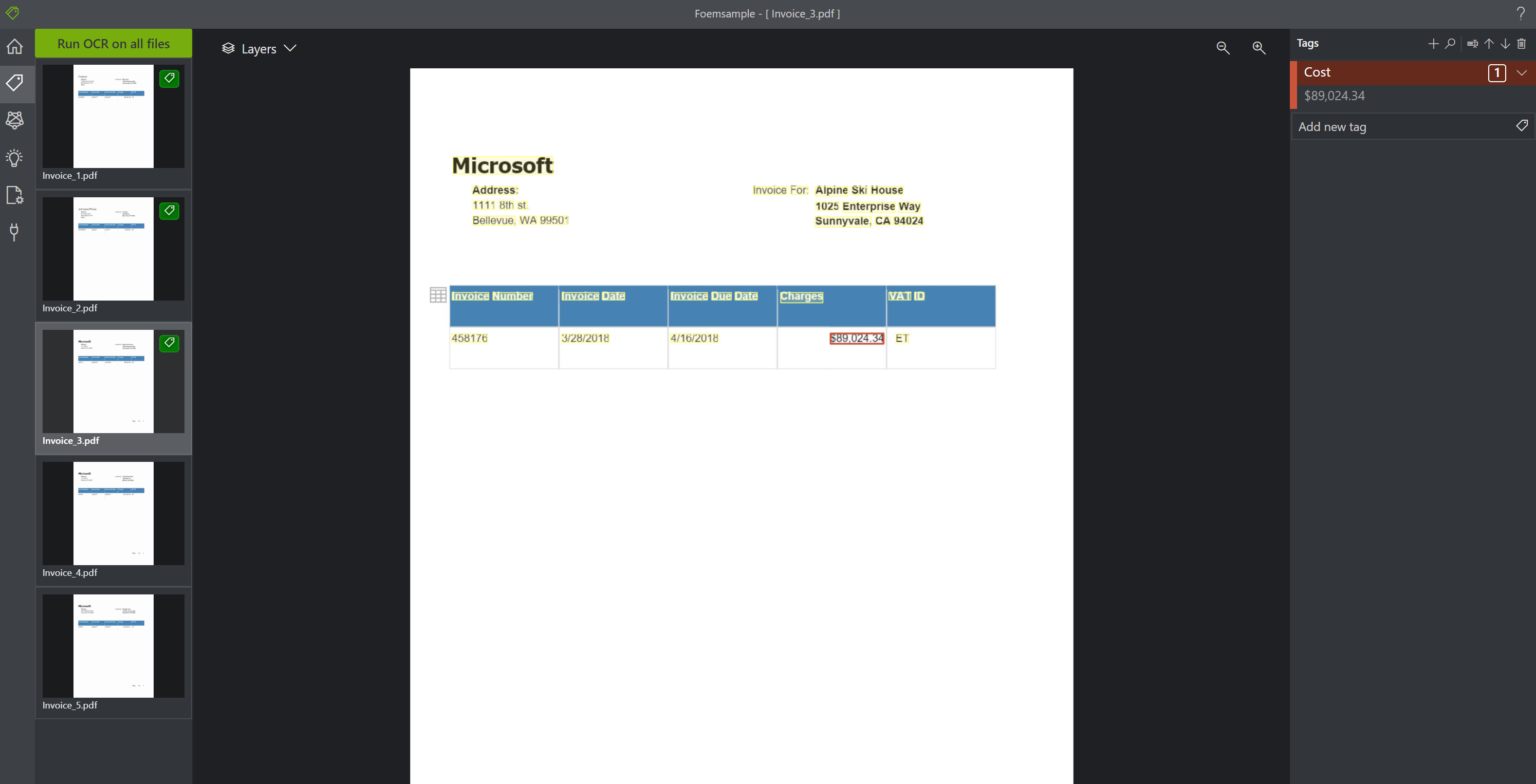
ここまでできたら左のバーの Tag の下にある Train をクリックします。この Train を実行することで、これまで入力した Tag のデータからトレインモデルが生成され、指定した Azure Blob にモデルが格納されます。
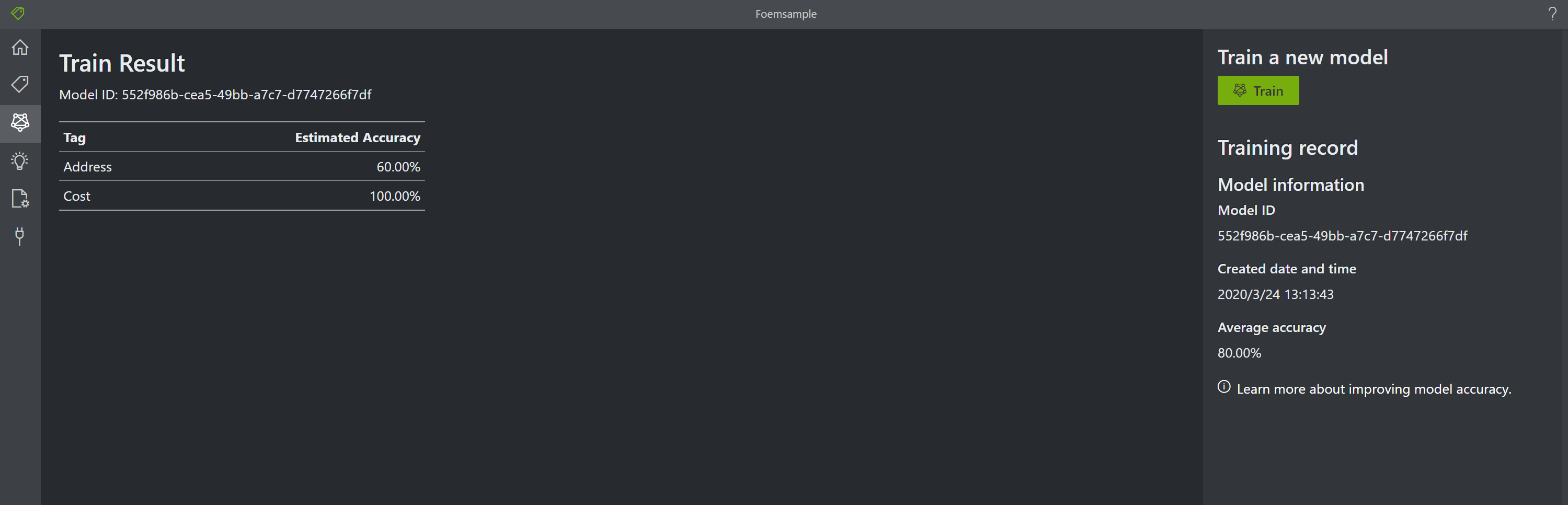
新しい領収書を読み込ませて見ましょう。すると、Tag として指定した「Cost」と「address」がしっかりと認識されていることが分かります。カスタマイズしたモデルが作成され、ドキュメント記載の内容にタグがつけられたということが確認できました。
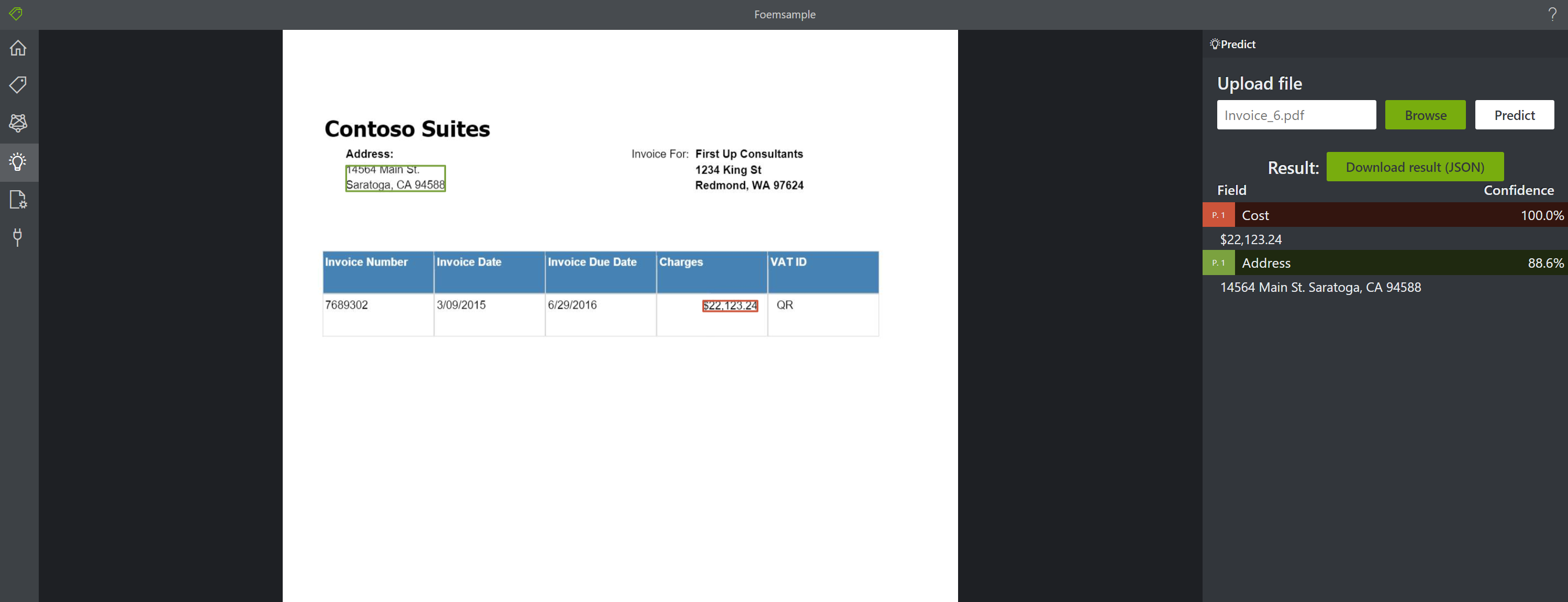
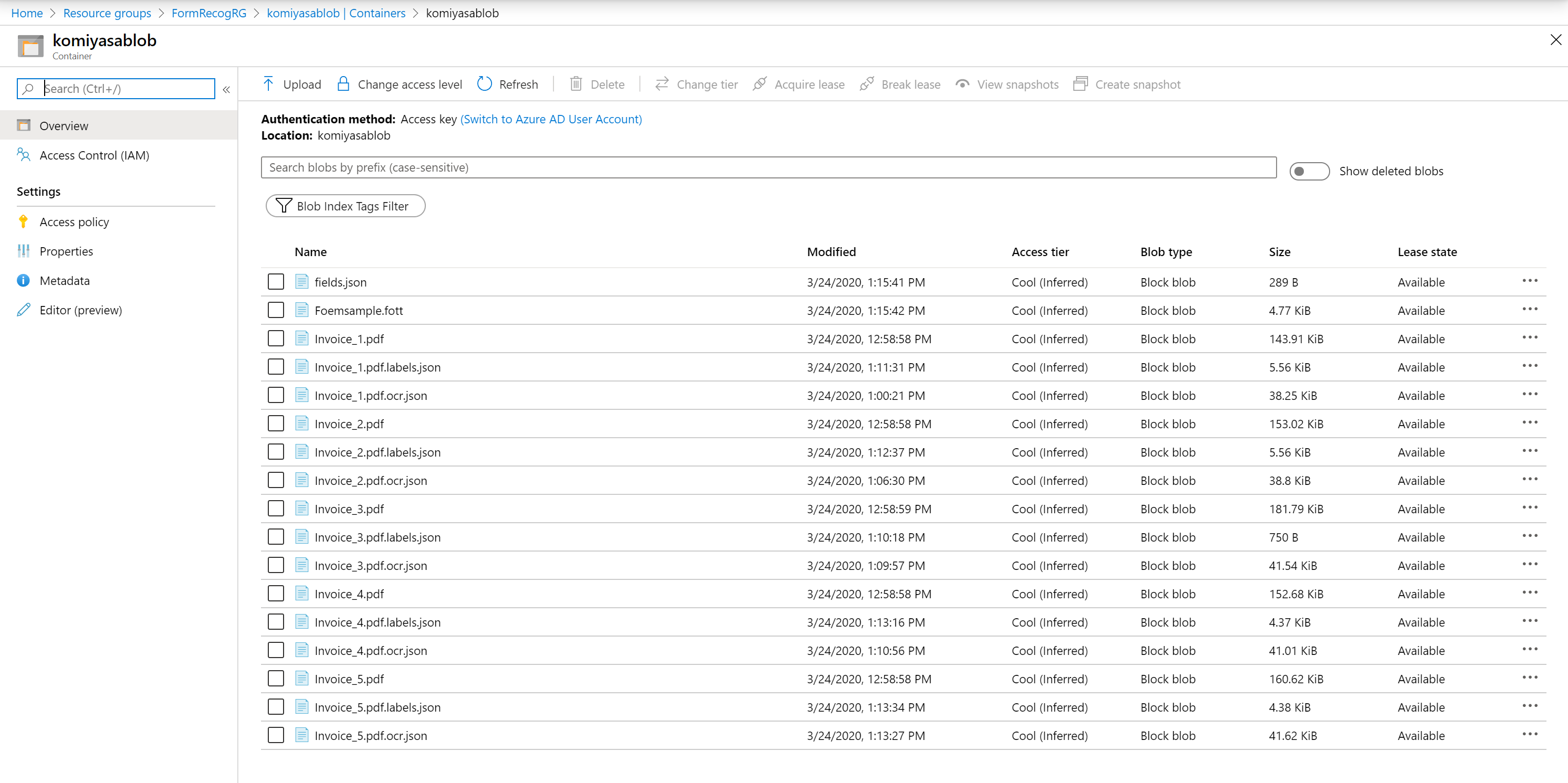
作成されたモデルは Azure Blob に格納されているので、他のアプリからこのモデルを使用したいときはこの Azure Blob を指定する事でカスタマイズしたモデルを使用することが可能です。とっても簡単ですね!!
まとめ
これまで Python のコードベースで書かなくてはならなかったカスタムモデルですが、この UI が公開されたことでかなり簡単にモデルを作成できるようになりました。これまで人の手で実施していた領収書の文字起こしも、Form Recognizer をつかえばローコストで素早く処理することが出来ると思います。リリースされて間もない機能なので、今後日本語への対応や手書きドキュメントへの対応など、進化が非常に楽しみです!
参考
過去に Logic App と Form Recognizer の連携について書いた記事があるのでこちらもよければー
(参考) Azure Form Recognizer を使って領収書の値を AI に認識させる
https://qiita.com/komiyasa/items/32f91996b6c7c4cc64ce