追記20180611
このページはあくまでWindowsでスタンドアローンを前提にした説明ですが、さくらのVPSを使ったセットアップの最新版を書きました。ゆっくり見ていってね!![]()
LAMP+WP+Pyのセットアップメモ2018
追記20180816
Windowsでスタンドアローン環境構築の2018最新版(by VisualStudio)できました!ゆっくり見ていってね!![]()
Pythonの環境構築とDBへのSQL実行例のメモ2018
追記20190201
なんか閲覧数が多いので内容全見直します。さすがに3年も経つとずいぶん日本語ページも増えたね![]()
参考ページ
Python3のインストール
C:\Python
ダウンロード(64bit版)
https://www.python.org/downloads/windows/
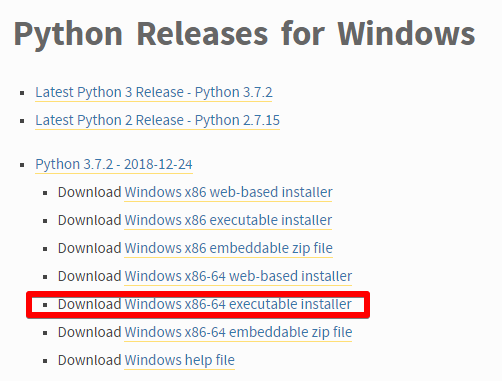
環境変数にPathを追加してからインストール
"Add Python 3.x to PATH" をチェックします。そうすると、コマンドプロンプトがpythonを認識できます。
インストール先を変更したかったので、僕は Customize installation を選びました。
確認
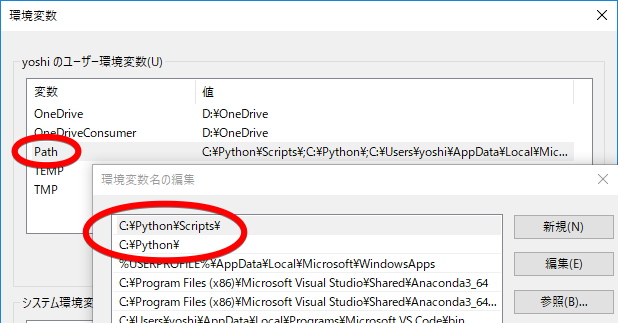
環境変数(超重要)
スタートボタンを押して「en」(=environment)と打ち込むと「システム環境変数の編集」が出てくるので、インストール場所が記録されていることを確認。
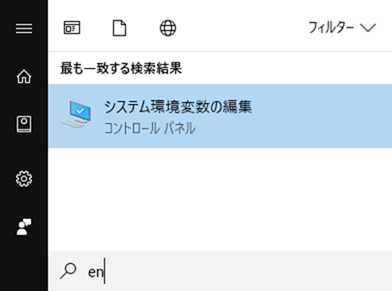
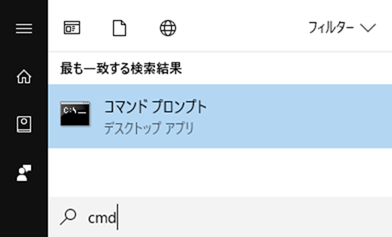
コマンドプロンプト
スタートボタンを押して「cmd」と打ち込むと「コマンドプロンプト」が出てくる。環境変数を設定したことにより、pythonナントカというコマンドが通るようになっている
Microsoft Windows [Version 10.0.17134.523]
(c) 2018 Microsoft Corporation. All rights reserved.
C:\Users\yoshi> python -V
Python 3.7.2
C:\Users\yoshi> pip freeze
C:\Users\yoshi>

使用頻度鬼のパッケージのインストール
pyodbcはdb接続に使います
pandasはcsvとかxlsを簡単に読み込んで分析処理するライブラリ
C:\Users\yoshi> python -m pip install --upgrade pip
C:\Users\yoshi> pip install pandas
C:\Users\yoshi> pip install pyodbc
C:\Users\yoshi>pip freeze
numpy==1.16.1
pandas==0.24.0
pyodbc==4.0.25
python-dateutil==2.7.5
pytz==2018.9
six==1.12.0
ディレクトリの移動
MS-DOSの基礎。pythonプログラムを実行するようなときに移動させる
C:\Users\yoshi> cd/d "D:\OneDrive\ドキュメント\Project\Python"
D:\OneDrive\ドキュメント\Project\Python>
プログラムの実行方法
実行するプログラムのあるディレクトリに移動「cd C:\xxxx\xxxx..」
「python xxxx.py」と打ち込むことでプログラムの実行が可能。
print("Hello world!")
D:\OneDrive\ドキュメント\Project\Python> python main.py
Hello world!
独自にライブラリを作ったら
Pythonのimportについてまとめる
例えば「PyUtils.py」という便利ライブラリを作って、「lib」というディレクトリにしまいこんだとするじゃん?そうしたら main.py から「Import」の予約語で便利ライブラリ(=ユーザー定義関数と言ったほうがいいか?)を呼べるんだけど、その方法は2種類ある。2のほうが短い詠唱で済むんだけどどっちもどっちかなぁ。
D:\OneDrive\ドキュメント\Project\Python> tree /F
D:.
│ main.py
└─ lib
PyUtils.py
importの仕方1
import lib.PyUtils
print("Hello world!")
instance = lib.PyUtils.HelloClass()
instance.HelloWorldByPyUtils()
class HelloClass:
def HelloWorldByPyUtils(self):
print("Hello PyUtils")
D:\OneDrive\ドキュメント\Project\Python> python main.py
Hello world!
Hello PyUtils
importの仕方2
from lib.PyUtils import *
print("Hello world!")
instance = HelloClass()
instance.HelloWorldByPyUtils()
class HelloClass:
def HelloWorldByPyUtils(self):
print("Hello PyUtils")
D:\OneDrive\ドキュメント\Project\Python> python main.py
Hello world!
Hello PyUtils
読み込むcsvをUTF-8で作る
VisualStudioCodeほんとすこ![]()
あ、これ名前ジェネレーターで作ってあるからテキトーな名前です(このジェネレーターはこれでまた便利よね)
(コピペできるやつ置いとくね)
| 所属 | 氏名 | 氏名(かな) | メールアドレス | 住所 | 誕生日 |
|---|---|---|---|---|---|
| リクルート | 本多 守 | ほんだ まもる | 1@gmail.com | 北海道 | 2019/2/1 |
| リクルート | 早坂 健吾 | はやさか けんご | 2@gmail.com | 青森県 | 2019/2/2 |
| リクルート | 立石 晋 | たていし すすむ | 3@gmail.com | 岩手県 | 2019/2/3 |
| リクルート | 鷲尾 崇之 | わしお たかゆき | 4@gmail.com | 宮城県 | 2019/2/4 |
| リクルート | 郭 卓司 | かく たくじ | 5@gmail.com | 秋田県 | 2019/2/5 |
| リクルート | 大串 幹男 | おおぐし みきお | 6@gmail.com | 山形県 | 2019/2/6 |
| リクルート | 島貫 典彦 | しまぬき のりひこ | 7@gmail.com | 福島県 | 2019/2/7 |
| リクルート | 古城 英孝 | こじょう ひでたか | 8@gmail.com | 茨城県 | 2019/2/8 |
| リクルート | 鯨井 健史 | くじらい けんじ | 9@gmail.com | 栃木県 | 2019/2/9 |
| リクルート | 来栖 源太 | くるす げんた | 10@gmail.com | 群馬県 | 2019/2/10 |
| リクルート | 塩井 崇浩 | しおい たかひろ | 11@gmail.com | 埼玉県 | 2019/2/11 |
| リクルート | 諸田 清人 | もろた きよひと | 12@gmail.com | 千葉県 | 2019/2/12 |
| リクルート | 神宮寺 善文 | じんぐうじ よしふみ | 13@gmail.com | 東京都 | 2019/2/13 |
| リクルート | 池水 了 | いけみず さとる | 14@gmail.com | 神奈川県 | 2019/2/14 |
| リクルート | 香椎 悠祐 | かしい ゆうすけ | 15@gmail.com | 新潟県 | 2019/2/15 |
| リクルート | 真 修吾 | ま しゅうご | 16@gmail.com | 富山県 | 2019/2/16 |
| リクルート | 西薗 浩彦 | にしぞの ひろひこ | 17@gmail.com | 石川県 | 2019/2/17 |
| リクルート | 鑓田 伸洋 | やりた のぶひろ | 18@gmail.com | 福井県 | 2019/2/18 |
| リクルート | 根塚 政晴 | ねづか まさはる | 19@gmail.com | 山梨県 | 2019/2/19 |
| リクルート | 中室 一起 | なかむろ かずき | 20@gmail.com | 長野県 | 2019/2/20 |
| リクルート | 三俣 健士 | みつまた けんじ | 21@gmail.com | 岐阜県 | 2019/2/21 |
| リクルート | 目崎 千裕 | めさき ちひろ | 22@gmail.com | 静岡県 | 2019/2/22 |
| リクルート | 滝田 祐吾 | たきだ ゆうご | 23@gmail.com | 愛知県 | 2019/2/23 |
| リクルート | 八本 真実 | やもと まこと | 24@gmail.com | 三重県 | 2019/2/24 |
| リクルート | 織井 章広 | おりい あきひろ | 25@gmail.com | 滋賀県 | 2019/2/25 |
| リクルート | 能丸 裕孝 | のうまる ひろたか | 26@gmail.com | 京都府 | 2019/2/26 |
| リクルート | 順 恭 | じゅん やすし | 27@gmail.com | 大阪府 | 2019/2/27 |
| リクルート | 幸島 樹一郎 | こうじま きいちろう | 28@gmail.com | 兵庫県 | 2019/2/28 |
| リクルート | 下津浦 光也 | しもつうら みつや | 29@gmail.com | 奈良県 | 2019/3/1 |
| リクルート | 安土 たかゆき | あんど たかゆき | 30@gmail.com | 和歌山県 | 2019/3/2 |
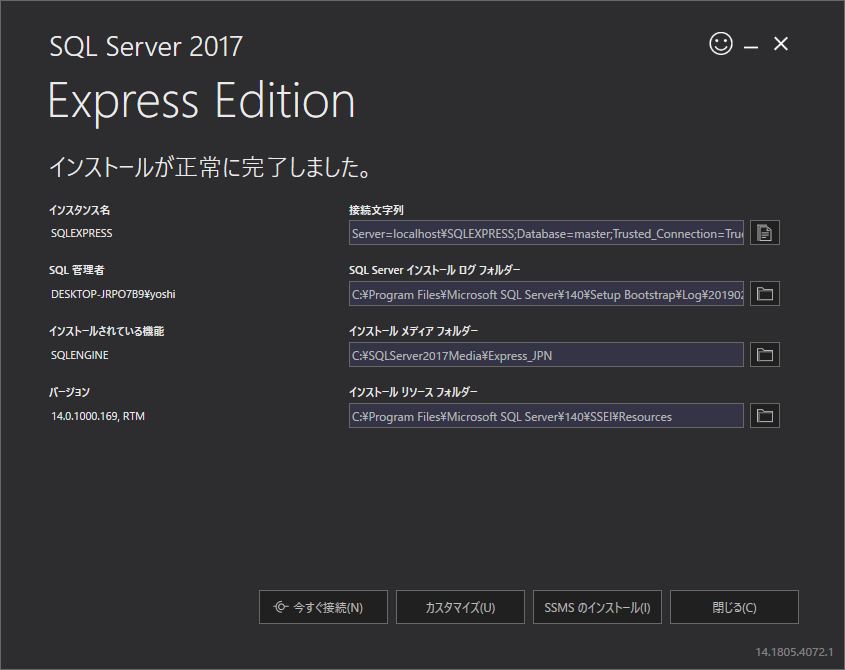
SQLServerセットアップ
dbはSQLServerを使用
SQLServerのエンジンとManegementStudio(操作するクライアントソフト)は違うんやで
SQLServerEngineダウンロード
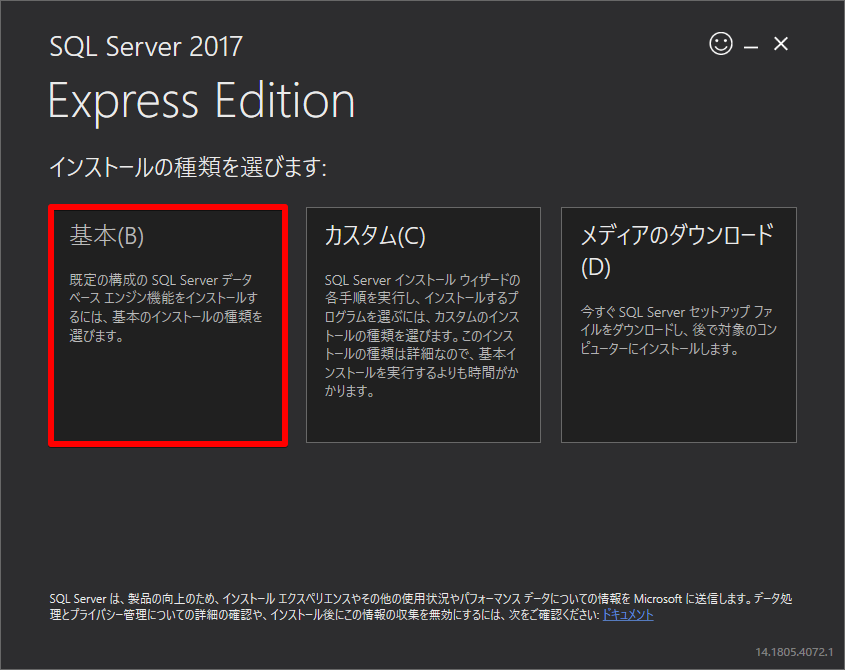
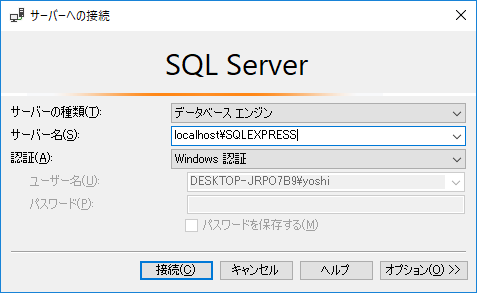
SQLServerローカル接続
ユーザーの追加
ユーザー名:python
パスワード:python
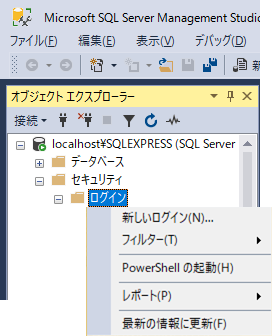
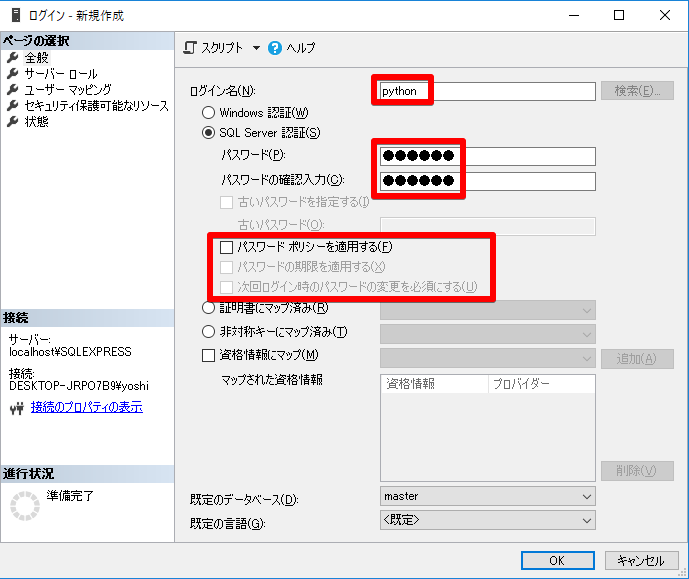
追記:Djangoやるときは、ここで「db_ddladmin」もチェックしましょう(CREATE TABLE などが発行できる)
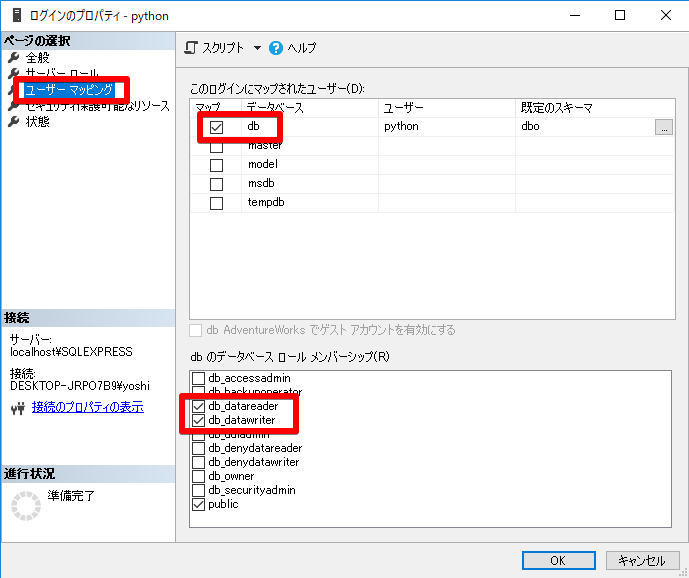
トラブルシューティング
pythonっていうユーザーを増やしてもSQLServer認証のモードにしないとログインできない。これ変えたらサーバーの再起動を忘れないこと。
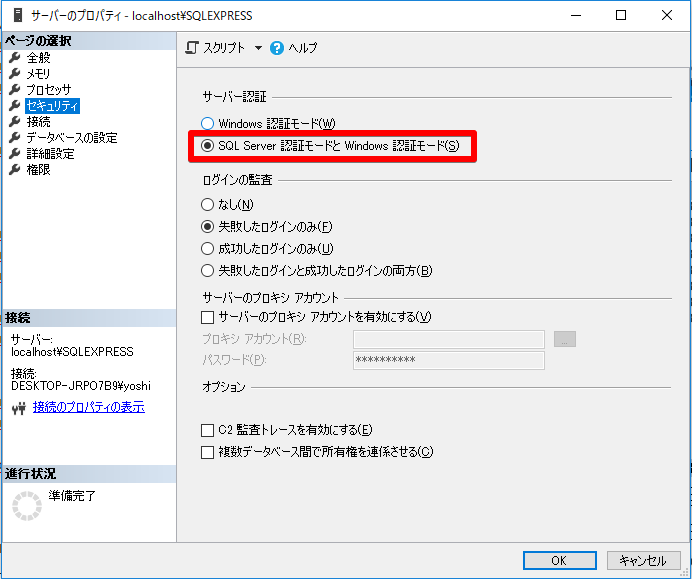
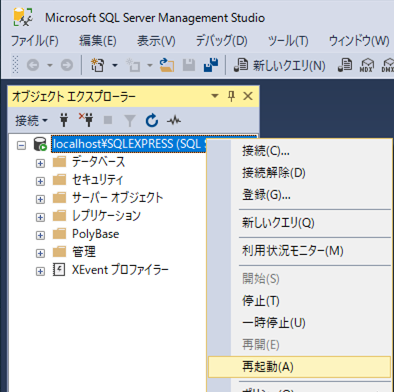
db作成
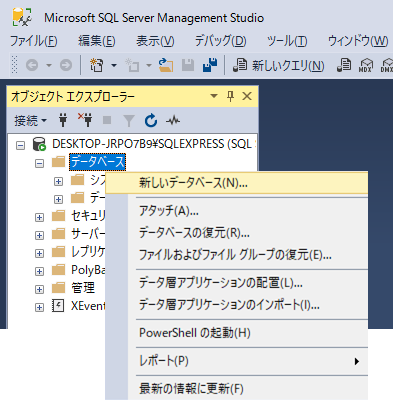
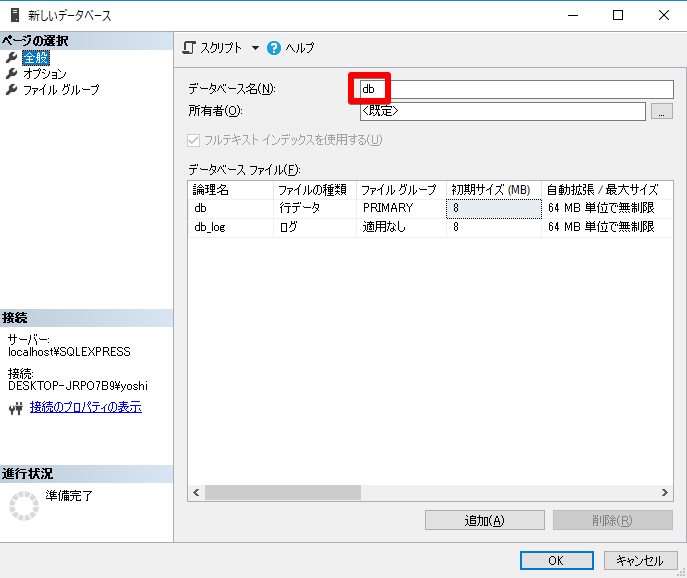
テーブル作成
CREATE TABLE 顧客 (
[所属] NVARCHAR(20) NULL
, [氏名] NVARCHAR(20) NULL
, [氏名(かな)] NVARCHAR(20) NULL
, [メールアドレス] NVARCHAR(20) NULL
, [住所] TEXT NULL
, [誕生日] NVARCHAR(20) NULL
);
これが超具体的なdb操作の例だ!
import pyodbc
import pandas as pd
import lib.PyUtils
# データ削除クエリを発行
SQL_TEMPLATE = "DELETE FROM [dbo].[顧客]" # SQL原本
editSql = SQL_TEMPLATE # SQL原本に置換をかける
lib.PyUtils.ExecuteSQLBySQLServer(editSql) # DELETE文の発行
# dbに突っ込むデータが入っているCSVはUTF-8
df = pd.read_csv(r"data\customer.csv")
# データ追加クエリを発行
SQL_TEMPLATE = "INSERT INTO [dbo].[顧客]([所属],[氏名],[氏名(かな)],[メールアドレス],[住所],[誕生日]) VALUES ('{0}','{1}','{2}','{3}','{4}','{5}')"
for line in df.values:
editSql = SQL_TEMPLATE # SQL原本
for i,col in enumerate(line): # SQL原本に置換をかける
editSql = editSql.replace('{' + str(i) + '}', col)
lib.PyUtils.ExecuteSQLBySQLServer(editSql) # INSERT文の発行
# 選択クエリを発行
SQL_TEMPLATE = "SELECT * FROM [dbo].[顧客]" # SQL原本
editSql = SQL_TEMPLATE # SQL原本に置換をかける
df = lib.PyUtils.ReadQueryBySQLServer(editSql) # SELECT文の発行
for line in df.values:
print(','.join(line)) # SQL結果を調理して提供
import pyodbc
import pandas as pd
def ExecuteSQLBySQLServer(sql):
con = pyodbc.connect(r'DRIVER={SQL Server};SERVER=localhost\SQLExpress;DATABASE=db;UID=python;PWD=python;')
cur = con.cursor()
cur.execute(sql)
con.commit()
con.close()
def ReadQueryBySQLServer(sql):
con = pyodbc.connect(r'DRIVER={SQL Server};SERVER=localhost\SQLExpress;DATABASE=db;UID=python;PWD=python;')
df = pd.io.sql.read_sql(sql,con)
con.close()
return(df)
確認
D:\OneDrive\ドキュメント\Project\Python> python main.py
リクルート,本多 守,ほんだ まもる,1@gmail.com,北海道,2019/2/1
リクルート,早坂 健吾,はやさか けんご,2@gmail.com,青森県,2019/2/2
リクルート,立石 晋,たていし すすむ,3@gmail.com,岩手県,2019/2/3
リクルート,鷲尾 崇之,わしお たかゆき,4@gmail.com,宮城県,2019/2/4
リクルート,郭 卓司,かく たくじ,5@gmail.com,秋田県,2019/2/5
リクルート,大串 幹男,おおぐし みきお,6@gmail.com,山形県,2019/2/6
リクルート,島貫 典彦,しまぬき のりひこ,7@gmail.com,福島県,2019/2/7
リクルート,古城 英孝,こじょう ひでたか,8@gmail.com,茨城県,2019/2/8
リクルート,鯨井 健史,くじらい けんじ,9@gmail.com,栃木県,2019/2/9
リクルート,来栖 源太,くるす げんた,10@gmail.com,群馬県,2019/2/10
リクルート,塩井 崇浩,しおい たかひろ,11@gmail.com,埼玉県,2019/2/11
リクルート,諸田 清人,もろた きよひと,12@gmail.com,千葉県,2019/2/12
リクルート,神宮寺 善文,じんぐうじ よしふみ,13@gmail.com,東京都,2019/2/13
リクルート,池水 了,いけみず さとる,14@gmail.com,神奈川県,2019/2/14
リクルート,香椎 悠祐,かしい ゆうすけ,15@gmail.com,新潟県,2019/2/15
リクルート,真 修吾,ま しゅうご,16@gmail.com,富山県,2019/2/16
リクルート,西薗 浩彦,にしぞの ひろひこ,17@gmail.com,石川県,2019/2/17
リクルート,鑓田 伸洋,やりた のぶひろ,18@gmail.com,福井県,2019/2/18
リクルート,根塚 政晴,ねづか まさはる,19@gmail.com,山梨県,2019/2/19
リクルート,中室 一起,なかむろ かずき,20@gmail.com,長野県,2019/2/20
リクルート,三俣 健士,みつまた けんじ,21@gmail.com,岐阜県,2019/2/21
リクルート,目崎 千裕,めさき ちひろ,22@gmail.com,静岡県,2019/2/22
リクルート,滝田 祐吾,たきだ ゆうご,23@gmail.com,愛知県,2019/2/23
リクルート,八本 真実,やもと まこと,24@gmail.com,三重県,2019/2/24
リクルート,織井 章広,おりい あきひろ,25@gmail.com,滋賀県,2019/2/25
リクルート,能丸 裕孝,のうまる ひろたか,26@gmail.com,京都府,2019/2/26
リクルート,順 恭,じゅん やすし,27@gmail.com,大阪府,2019/2/27
リクルート,幸島 樹一郎,こうじま きいちろう,28@gmail.com,兵庫県,2019/2/28
リクルート,下津浦 光也,しもつうら みつや,29@gmail.com,奈良県,2019/3/1
リクルート,安土 たかゆき,あんど たかゆき,30@gmail.com,和歌山県,2019/3/2
D:\OneDrive\ドキュメント\Project\Python>
pandas is 便利
データフレームとは「SQLでテーブルをいじるように配列データを加工できる概念状態」のことです。列の削除もできるし、NaNを0に置き換えるとかもできる。だから慣れれば配列より使いやすいと思う。R言語とかでよく使うんだよねデータフレームって。
Pandas公式リファレンス
import pyodbc
import pandas as pd
import lib.PyUtils
# データ削除クエリを発行
SQL_TEMPLATE = "DELETE FROM [dbo].[顧客]" # SQL原本
editSql = SQL_TEMPLATE # SQL原本に置換をかける
lib.PyUtils.ExecuteSQLBySQLServer(editSql) # DELETE文の発行
# dbに突っ込むデータが入っているCSVはUTF-8
df = pd.read_csv(r"data\customer.csv")
##################################
# ここで pandas でデータ加工します #
##################################
データの加工 Lv1
ここからは文字列加工なので、Pythonコンソールでやる
業務的にデータフレームを操作するのはだいたい以下の3つじゃないかな(4つ目も頻度としては少ないよね)
Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import numpy as np
>>> import pandas as pd
# サンプルデータを用意
>>> df = pd.DataFrame([np.nan, 2, np.nan, 0])
>>> df
0
0 NaN
1 2.0
2 NaN
3 0.0
# No.1 NaN(欠損値)を0へ置換
>>> df = df.fillna(0)
>>> df
0
0 0.0
1 2.0
2 0.0
3 0.0
# No.2 文字に変換して5桁ゼロ埋め
# astype(str) ...stringに型変換
# .str. ...strメソッドへのアクセサ(.splitとかのコマンドが使えるようになる)
>>> df[0] = df[0].astype(str).str.zfill(5)
>>> df
0
0 000.0
1 002.0
2 000.0
3 000.0
# No.3 dbが理解できるNullに変換
# NULLは無いこと(未定義),NaNは使えないこと(Not Available,欠損値)
# 標準ライブラリではNoneがNullに相当する.Sqlite3にNULLを入れたいときはNoneを渡す.
>>> df = pd.DataFrame([np.nan, 2, np.nan, 0])
>>> df = df.where(pd.notna(df), None)
>>> df
# No.4 列の削除(axis(意味:軸)を1にすると「列の...」の意味合いになるようだ)
>>> df = df.drop([0], axis=1)
>>> df
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]
データの加工 Lv2 グループごとに指定する値で欠損値を埋める
統計データの前処理には、欠損値(≒Null値)にとりあえず平均値入れとけ、とか中央値入れとけ、とかいうものがある。
例えば これは Kaggle の住宅価格予想の回帰分析のページ で、欠損値をグループ別の中央値で埋めたいというパート。業務的には超ありそう。SQLだとすぐにやり方思いつくんだけど...
- 集計後のテーブルまたはビューを作る
- Left Join で null の明細だけに更新をかける
LotFrontageは「間口の広さ(家屋の正面の幅)」です。LotFrontageが欠損している場合、どのような値を埋めれば良いでしょうか。一例としては「近隣の家々、つまり『近くの通りの名前(Neighborhood)』が同じ家々のLotFrontageの値とほぼ同じになる」という考え方です。そこで今回は、補充する値として「Neighborhoodが同じ家々のLotFrontafeの中央値(median)」を採用します。
以下のセル状のものが、『近くの通りの名前(Neighborhood)』を中央値で集計した値だ。
na を見つけ次第、以下の「groupby項目の中央値」でもって埋めたい。
| Neighborhood | LotFrontage(median) |
|---|---|
| Blmngtn | 43 |
| Blueste | 24 |
| BrDale | 21 |
| BrkSide | 52 |
| ClearCr | 80 |
| CollgCr | 70 |
| Crawfor | 74 |
| Edwards | 64.5 |
| Gilbert | 65 |
| IDOTRR | 60 |
| MeadowV | 21 |
| Mitchel | 73 |
| NAmes | 73 |
| NoRidge | 91 |
| NPkVill | 24 |
| NridgHt | 88.5 |
| NWAmes | 80 |
| OldTown | 60 |
| Sawyer | 71 |
| SawyerW | 66.5 |
| Somerst | 73.5 |
| StoneBr | 61.5 |
| SWISU | 60 |
| Timber | 85 |
| Veenker | 68 |
Group化の仕組みはsplit-apply-combine
# LotFrontageのNAを、近隣の家(Neighborhood)単位でLotFrontageのmedianを取って、その値で埋める
print(data['LotFrontage'].isnull().sum()) #欠損値259
data["LotFrontage"] = data.groupby("Neighborhood")["LotFrontage"].apply(lambda x: x.fillna(x.median()))
print(data['LotFrontage'].isnull().sum()) #欠損値0
Pythonのlambdaについてはここを見て Pythonのlambdaって分かりやすい
これは「タテにフルスキャン(=全量が処理対象)しつつ na を見つけ次第、任意のgroupby項目の中央値で埋める」というイメージだ。
# lambda 仮引数: 返り値
# この lambda関数 で使用する引数を x と定義する
# x は グループ別に split されたうちの 1つ の明細が全量引き渡される
# つまるところ、全量の na に対して中央値で埋める となる
lambda x: x.fillna(x.median())
『近くの通りの名前(Neighborhood)』は Blmngtn から始まって Veenker まで25レコードある。これが groupby されると、内部処理的にはいったんグループ別に 25テーブル に split される(25テーブルの明細数を全部足し算すると全量明細数になるのね)。そして、25テーブルそれぞれに apply関数 のカッコの中身が適用される。あらまぁやってることはSQLと同じどころか見方さえわかってしまえばステップが少ない(「apply」には「適用する」という意味がある)というのがオライリーの図として書いてあるが、詳しくはちゃんと本買えw かなりわかりやすいぞ。
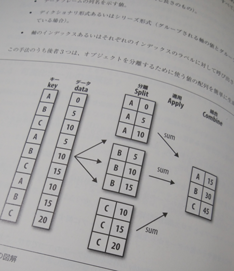
統計処理チートシート
このチートシートは簡単そうに書いてあるけど、やっぱり統計は最初の敷居が高いよな。わかってからコピペしないと結局なにしてるのかがわからないのは一般的なプログラミングでもいっしょ。僕は統計ができなかったので Techacademy のデータサイエンスコース(4週間 139,000円)をやってみた。基本的には Pythonで学ぶあたらしい統計学の教科書 をなぞる形になるが、Kaggleでの戦い方を学ぶところまでいけるので、オンライン教材としてのオススメはできるね。「いまこの問題を解くためにどこの数学に戻らなければならないか」といった逆追いの質問など、本に書かれてないようなことをたくさん質問できました。独学でがんばってるけどなんだか本のドクターショッピングになっちゃって結局すすまねーなぁ。。いまどこだ?みたいになってるならお金出しちゃったほうがいい(そのステップを踏んでいれば実は「ダンジョンで迷ってレベルを上げすぎた状態」になっていて、鋭い質問ができる![]() )。とはいえ、やってやれないこたないけど仕事やりながら4週間で456ページ(1冊全部)ってシビれるわぁ笑
)。とはいえ、やってやれないこたないけど仕事やりながら4週間で456ページ(1冊全部)ってシビれるわぁ笑
チート1(データ読み込み・可視化・欠損値点検・欠損値埋め・過相関点検・モデル作成・回帰直線・総点検までの基本的な流れ)
モデルを作るってのは要は数学的な関数を作るってこった(y = x^2 みたいなのを作ってあとはパソコンがその算式に対してゴリ押しの当て込み計算を行う)
# ◆インポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%precision 3 # 小数点3桁表記
%matplotlib inline # jupyterのみ
sns.set()
# ◆データを読み込む
data = pd.read_csv(r'data/kaggle_housing_price_revised.csv')
# ◆確認1 データの可視化
# 【pairplot】
sns.pairplot(data, hue='Category') # hueは指定したグループごとに色分けしてくれる
# 【ヒストグラムつきの散布図】
sns.jointplot(x = 'temperature', y = 'beer', data = beer, color = 'black')
# 【箱髭図】
sns.boxplot(x = 'Line', y = 'Density', data = data, color = 'gray')
# 【散布図】
fig, ax = plt.subplots()
ax.scatter(x = data['GrLivArea'], y = data['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()
# ◆確認2 各データに占める欠損値の割合をグラフで
all_data_na = (data.isnull().sum() / len(data)) * 100
# 全部値が入っている(=0)レコードを削除し、降順に並べる
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
f, ax = plt.subplots(figsize=(15, 12))
plt.xticks(rotation='90')
sns.barplot(x=all_data_na.index, y=all_data_na)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
plt.ylim([0,100]) # 最大値を100としてスケールを固定
# ◆欠損値を埋める(確認2といったりきたり)
# None埋め:
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
# 0埋め:
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
# 中央値埋め:
data["LotFrontage"] = data.groupby("Neighborhood")["LotFrontage"].apply(lambda x: x.fillna(x.median()))
# ◆強い相関関係にある変数の削除
threshold = 0.8
# data から相関行列(Correlation Matrix)を作成して表示する。その際、絶対値を適用して負の値をプラスに変換すること(corr()は数値列のみを演算対象にするため、corr_matrix.columns は目減りする)
corr_matrix = data.corr().abs()
# 対角線上は絶対に 1 になること、および、対角線より下の部分は、上の部分と情報が重複していることから 相関行列を上三角行列に変換 (corr_matrixを 0 or !0 でbool型と見立てて !0 を where で抜き出した、ということか)
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# 上三角行列から SalePrice以外の列について threshold 以上の値が1つ以上ある列を抽出
to_drop = [column for column in upper.columns if any(upper[column] > threshold)]
print('There are %d columns to remove.' % (len(to_drop)))
to_drop.remove('SalePrice')
data_dropped = data.drop(columns = to_drop)
# ◆ダミー変数化
data_dummied = pd.get_dummies(data_dropped)
data_dummied.head()
# ◆モデルの作成
# 【最小二乗法】
lm_model = smf.ols(formula = 'beer ~ temperature', data = beer).fit()
lm_model.summary()
# 【一般化線形モデル】
glm_model = smf.glm(formula = 'beer ~ temperature', data = data, family=sm.families.Binomial()).fit()
glm_model.summary()
# 【AIC点検】NULLモデルよりもAICが小さくなるかを見る
null_model = smf.ols('beer ~ 1', data = beer).fit()
print('null_model.aic: ', null_model.aic)
print('lm_model.aic: ', lm_model.aic)
print('気温という説明変数が入ったほうがAICが小さくなったので予測精度は高くなるのではないか')
# ◆(点検1)回帰直線
sns.lmplot(x = 'temperature', y = 'beer', data = beer, scatter_kws = {'color': 'black'}, line_kws = {'color': 'black'})
# 【確認1】気温0度の予測値は切片(intercept)と一致する
lm_model.predict(pd.DataFrame({'temperature':[0]}))
# 【確認2】気温20度の予測値は seaborn 回帰直線の位置に一致する
lm_model.predict(pd.DataFrame({'temperature':[20]}))
# ◆(点検2)選択したモデルを用いてQ-Q プロットで残差の正規性を確認
sm.qqplot(lm_model.resid, line = 's')
# 予測値と実際の SalePrice を 散布図で重ねて表示できる
x = range(len(data))
y = data['SalePrice']
plt.scatter(x, y)
plt.scatter(x, lm_model.predict(data))
チート2(ランダムフォレスト)
ランダムフォレストをかます事自体は簡単だけど「何が起こったのか」という解釈が重要
# ランダムフォレストを実行し、検証用データでMSEを算出
model_random_forest = RandomForestRegressor(criterion='mse').fit(X_train, y_train)
mean_squared_error(y_test, model_random_forest.predict(X_test))
> 1322565474.5486445
# 何だよこの数字!?って思ったら「検証用データと予測値の平均二条の差」で検算できる
# ◆mse(平均二乗誤差) 対 手動mse による検算で納得感を得る
np.mean((y_test - model_random_forest.predict(X_test))**2)
> 1322565474.5486445
# modelを作ったら y と y^ を散布図に並べる
fig, ax = plt.subplots()
ax.scatter(x = y_test, y = model_random_forest.predict(X_test))
plt.ylabel('predict', fontsize=13)
plt.xlabel('SalePrice', fontsize=13)
plt.show()
◆ランダムフォレストのプロットされたもの。SalePriceと予測値が直線上に並んでいる(予測性能がそれなりにある)
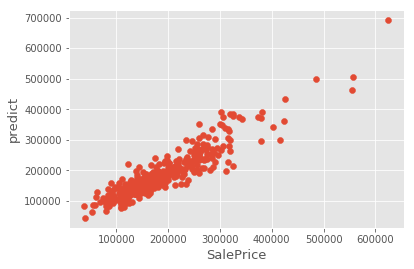
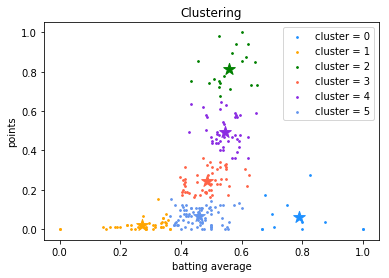
チート3(クラスタリング)
クラスタリングも、かます事自体は簡単だけど「何が起こったのか」という解釈が重要
# モジュールの読み込み
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
# データ読み込み
dataset = pd.read_csv('data/baseball_salary.csv')
# 中身を'打率'と'打点'の列のみにする
dataset = dataset[['打率', '打点']]
# MinMaxScalerで正規化を実施
dataset_scaled = MinMaxScaler().fit(dataset).transform(dataset)
# 正規化後の打率と打点の散布図を描画する
fig, ax = plt.subplots()
ax.scatter(x = dataset_scaled[:,0], y = dataset_scaled[:,1])
plt.ylabel('points', fontsize=13)
plt.xlabel('batting average', fontsize=13)
plt.show()
# エルボーを見てクラスタ数を決定する(6だな...)
# WCSS: ノードから最短クラスタ中心への距離の総和(within-cluster sum of squares)
wcss = []
n_comps = np.arange(1, 10)
for k in n_comps:
# KMeansの初期化。initはデフォルトで"k-means++"
km = KMeans(n_clusters=k, init='k-means++').fit(dataset_scaled)
# inertia_属性に、WCSSの値が入っている
wcss.append(km.inertia_)
fig = plt.figure(figsize=(6, 4))
plt.plot(n_comps, wcss)
plt.xlabel("# of clusters")
plt.ylabel("WCSS")
plt.show()
# fitさせて散布図にプロットする(for文はクラスタのカラーリング)
km = KMeans(n_clusters=6, init='k-means++').fit(dataset_scaled)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
colors = ['dodgerblue', 'orange', 'green', 'tomato', 'blueviolet', 'cornflowerblue']
cluster_ids = list(set(km.labels_))
for k in range(len(cluster_ids)):
average = dataset_scaled[km.labels_ == k, 0]
points = dataset_scaled[km.labels_ == k, 1]
ax.scatter(average, points, c=colors[k], s=3, label=f'cluster = {cluster_ids[k]}')
ax.scatter(average.mean(), points.mean(), marker='*', c=colors[k], s=150)
ax.set_title('Clustering')
ax.set_xlabel('batting average')
ax.set_ylabel('points')
ax.legend(loc='upper right')