当初、多項式近似だけをまとめようとしてましたが
追記式のRTipsにします
参考ページ
ODBCを利用宣言
library(RODBC)
MSAccessへのODBC接続とSQL発行例
fpath = file.path('C:/Users/Yoshitaka/Desktop/xxx.accdb')
cn = odbcConnectAccess2007(fpath)
res = sqlQuery(cn, 'SELECT * FROM M_TABLE')
res$Count = 1 # Tips 最後尾にカウント集計用の列を「新規追加」して '1' を振っとく
odbcClose(cn)
ディレクトリの変更
setwd('C:/Users/Yoshitaka/Desktop')
CSVまとめ読み1(rbind)
rbindはMSAccessでいう「Union」。1月データ、2月データ・・・12月データという割れたデータをひとつに集積してから加工処理がしたいという場面に。
なお、最終行に改行が含まれてないときに警告が表示される
csv = rbind(
read.csv('sampledata1.csv', fileEncoding='CP932', header=T),
read.csv('sampledata2.csv', fileEncoding='CP932', header=T)
)
CSVまとめ読み2(for)
ファイルをひとつひとつ読み込んでひとつひとつ加工処理、ひとつひとつ保存していくという場面に。
for(i in 1:10)
{
#「%02」は「整数2桁出力(0埋めあり)」を for文の i で代替
fpath = sprintf('sampledata%02d.csv', i) # sample01.csv, sample02.csv ...
csv = read.csv(fpath, fileEncoding='CP932', header=T)
}
ベクトル演算
# forをかまさずに「全体がけ」ができる。ベクトルって便利だなぁ~
> vec1 <- c(4,5,2,3)
> vec2 <- c(1,2,1,2)
>
> vec1 / 2
[1] 2.0 2.5 1.0 1.5
> vec1 - vec2
[1] 3 3 1 1
> vec1 * vec2
[1] 4 10 2 6
データフレーム(表形式)に変換
1次元配列(YYYYとかheightとかweight)をくっつけて表形式にできる
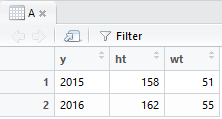
# 材料
# 年度
YYYY = c(2015,2016)
# 身長
height = c(158,162)
# 体重
weight = c(51,55)
# くっつけるー
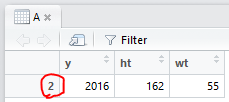
A = data.frame(y=YYYY, ht=height, wt=weight)
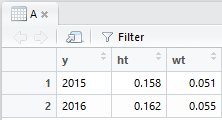
# 数値列だけ割り算して戻す
A[2:3] = A[2:3]/1000
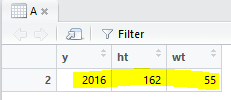
# WHERE条件をかける(後ろにカンマつけないとAに返したあとにオカシクなる)
A = A[A$y >=2016,]
列の追加
表形式のデータなどに "宣言されていない列名" を指定すると勝手に列が追加される
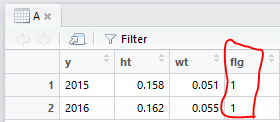
A$flg = 1
列名の付与
列名をつけて美しい成果物にしよう。CSVに出力するときとか大事ネ
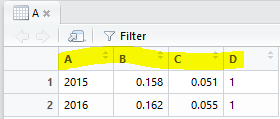
colnames(A)=c('A','B','C','D')
Function定義1:中央値集計
GetMedian = function(key, data, newcolname){
# 中央値集計後データの取得
agg = data.matrix(tapply(data, key, median))
# データ列に名前をつける
colnames(agg) = newcolname
# matrixで返す
return(agg)
}
Function定義2:単純集計
GetSum = function(key, data, newcolname){
# 合計値集計後データの取得
agg = data.matrix(tapply(data, key, sum))
# データ列に名前をつける
colnames(agg) = newcolname
# matrixで返す
return(agg)
}
Function定義3:日付計算
get_add_y = function(i){
y = 1900 + as.POSIXlt(Sys.Date())$year # 現在の年
return (y + i)
}
get_add_ym = function(i){
y = 1900 + as.POSIXlt(Sys.Date())$year # 現在の年
m = as.POSIXlt(Sys.Date())$mon + 1 # 現在の月
# 加算して12を超えた
if (m + i > 12) {
m = (m + i) %%12 # 加算後の12の剰余を取る
y = y + 1
}else{
m = (m + i)
}
return (as.integer(paste0(y, formatC(m, width=2, flag="0"))))
}
get_add_y2 = function(yyyy, i){
y = yyyy # 任意の年
return (y + i)
}
get_add_ym2 = function(yyyymm, i){
y = as.integer(substr(yyyymm, 1, 4)) # 任意の年
m = as.integer(substr(yyyymm, 5, 6)) # 任意の月
# 加算して12を超えた
if (m + i > 12) {
m = (m + i) %%12 # 加算後の12の剰余を取る
y = y + 1
}else{
m = (m + i)
}
return (as.integer(paste0(y, formatC(m, width=2, flag="0"))))
}
> 1900 + as.POSIXlt(Sys.Date())
[1] "2019-07-15 00:31:40 UTC"
> get_add_y(6)
[1] 2025
> get_add_ym(1)
[1] 201908
> get_add_ym(2)
[1] 201909
> get_add_ym(3)
[1] 201910
> get_add_ym(4)
[1] 201911
> get_add_ym(5)
[1] 201912
> get_add_ym(6)
[1] 202001
> get_add_y2(2019, 1)
[1] 2020
> get_add_ym2(201912, 1)
[1] 202001
yearの1900とかmonの1ってなんやねんってときの参考は こちら
まぁおまじない定数です。
要約
summary(v)
グラフ(棒グラフ・折れ線グラフ・散布図)
CSV出力
key集計したあとだから row.names が欲しい。タテのレコード量が同じであればcbindでヨコツナギできる(row.namesはアカマル)quoteはFALSEにすることで文字型に勝手につくダブルクォーテーションがキャンセルされる。
write.csv(cbind(col1, col2, col3, col4), 'output.csv', row.names = TRUE, quote = FALSE)
多項式近似のベーシックプラクティス
# 素材
x = c(0.3, 1.0, 2.3, 3.3, 3.7, 5.0, 6.2, 7.2, 7.8, 9.2)
y = c(14.8, 58.3, 96.8, 87.8, 64.8, 43.5, 50.9, 77.1, 108.3, 143.5)
df = data.frame(x,y)
# 散布図
plot(x,y)
mdl = lm(y ~ I(x^4) + I(x^3) + I(x^2) + x, data = df)
summary(mdl)
# 0~10の範囲を解像度100にした数字(等差数列)を作成(これによりxが0.1きざみになり、曲線がなめらかになる
x_new = seq(from=0, to=10, length=100)
# mdlを使って解像度100の予測値を算出
mdl.predict = predict(object=mdl, newdata=data.frame(x = x_new))
# 解像度100の予測値曲線を描画
lines(mdl.predict ~ x_new, col = "red")
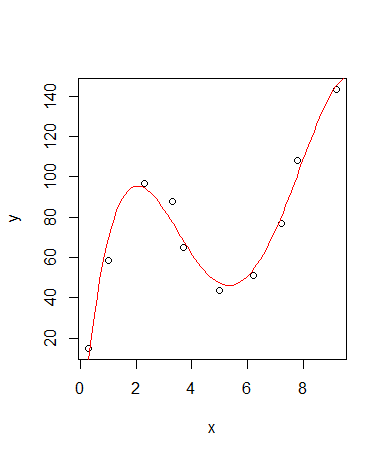
多項式近似
今回は12個の虫食いデータから20個のデータを錬金する話。
例えばこんなデータをもらうとする。よくあるよね。
10年分は数字があるけど途中で虫食いになってて11年~20年の分は数字をあぶりださないといけないようなやつ。
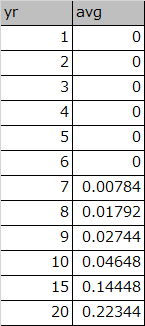
とある業務では、いままではこれをExcelを使ってやっていた。
1.データに対して「散布図」を描く(Excelの多項式近似グラフ作成の参考)
※ ![]() コメントでのご指摘で「折れ線グラフ」を描いてましたが「散布図」です。
コメントでのご指摘で「折れ線グラフ」を描いてましたが「散布図」です。
※ ![]() 折れ線グラフと散布図のちがい
折れ線グラフと散布図のちがい
2.数式をセルに転記「y = 6E-07x5 - 3E-05x4 + 0.0007x3 - 0.0046x2 + 0.0113x - 0.0078」
3.テキスト編集で項に割る(4つのセルに分離する)
4.1-20をxに代入して数字をあぶりだす
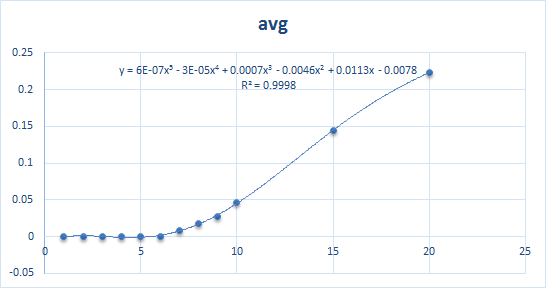
...悪かないんだけど...
グラフを描かないと式が取り出せない時点でやっぱり Poor だよね。それを脱出するために3か月ぐらいかけてRを覚えたのでそのメモ
StackOverflow:predict関数の警告について
# ディレクトリの変更
setwd("C:/Users/Yoshitaka/Desktop")
# CSVデータの読み込み処理
df = data.frame(read.csv('data.csv', fileEncoding='CP932'))
# この詰め替えが地味に重要
avg = df$avg
yr = df$yr
# CSVデータのプロット。期間(=データ数)は12
plot(avg ~ yr, data = df)
# CSVデータを使った多項式MODELの計算
mdl = lm(avg ~ I(yr^4) + I(yr^3) + I(yr^2) + yr, data = df)
# 新しい期間のガワは20
df_yr_new = 1:20
# lm関数を当ててつくったmdlを使ったpredict(予測の意)関数は newdata で「同じ名前」を見つけることを試みる(期間を延ばす代償)。
# 同じ名前を強要するのでつまり「$」を使った指定ができない。df_yr_new を yr とカンチガイさせよう
mdl.predict = predict(mdl, newdata = data.frame(yr = df_yr_new))
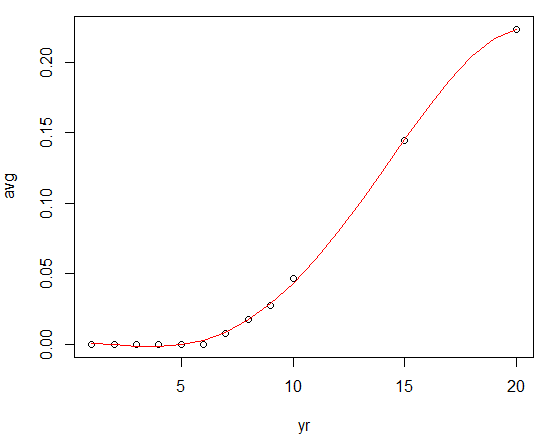
# mdlデータのプロット。期間(=データ数)は20
lines(mdl.predict ~ df_yr_new, col = "red")
これで12個のデータから20個のデータを錬金できた。
やっぱり目的があると覚えるよね
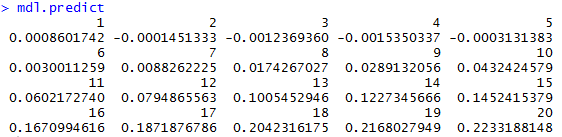
この20個のデータをCSVに吐いてさらに計算加工できるようにもなった。
マルは実測値12個。赤い線が推測値20個で実測値にできるかぎり沿うように再現した線
定量データと定性データのセンス
定量データは事実、定性データも事実なんだけど...
例えば、日経ビジネス2016年12月26日号「次の次まで考えろ」から。
売上高が定量データ。これだけ見ててもしょうがなくて
2代変わった後の売上高がどうなったか。。。とかね
そういう見方でデータは変わってくるんだ
この号の日経ビジネスはおもしろいぞ(ステマ)
あとは[トヨタが電通の広告不正を見破った話] (http://www.goodbyebluethursday.com/entry/dentsu-fraud) とかかなぁ。
こういうのも、漫然と数字眺めてるだけじゃわかんないんだよね。
そこでモノをいうのが定性的なモノ言い。
仕事に情熱がないと見破るのは難しいかもね。現実ってやつは。
定量と定性、どっちかだけじゃーだめ。
(てきとーにググってきたやつ)
「定量調査」と「定性調査」の違いを理解して、アンケートやユーザーインタビューの成果を最大化しよう!