本記事は2018年に最初に書いたものですが、2023年現在まで少しずつ更新しております。
本記事について
Azure Log Analytics や関連サービスを使い始める際に、Kusto (KQL) という独特のクエリ言語を学ぶことが必要になります。2023年時点で学習用コンテンツはかなり充実してきていますが、本記事では、すぐにアクセス可能なデモ環境を用いて、最も基本的なクエリの書き方を見ていきます。
応用編となる、スカラオペレーターや Join の利用方法については、本シリーズの第二弾、第三弾、でそれぞれ解説しております。
Azure Monitor Log / Log Analyticsとは?
Azure Monitor Log (通称 Log Analtyics) とは、Azure上でログの保管や分析ができる SaaS 型のログ管理ソリューションです。オンプレミス環境やクラウド環境の Windows Server/Clientのイベントログ・パフォーマンスカウンターや Linux サーバーの Syslog・パフォーマンスカウンターのデータを一括して収集して Azure 上のデータベースに保存し、それを Kusto(Kusto Query Language)というクエリ言語を使って分析することができます。また、Azure の各サービスのログをまとめて格納し、ログ管理を行うこともできます。Log Analyticsは、他のAzureのサービス(Microsoft Sentinel, Application Insights, Defender for Cloud など)の基盤としても利用されています。
(公式)Log Analytics - クラウドのIT分析ツール
(公式)Azure Log Analyticsとは?(公式ドキュメント)
Log Analyticsのクエリ言語 - Kusto Query Language とは?
Log Analytics のクエリ言語 (Kusto Query Language, KQL) は、クエリをシンプルに書くことができる、Azure のサービスでは Log Analytics をベースとしたサービスの他、Azure Data Explorer や Azure Resource Graph でも利用可能な言語です。そのほか、Microsoft 365 Defender の Advanced Hunting 機能でも利用されています。Kusto は高速に検索できるよう各基盤が整えられています。
Kusto (KQL) の学習用コンテンツ
Kusto (KQL) は最近 Web 上の学習用コンテンツが充実してきています。
クエリ言語のリファレンス
Kusto の概要
- KQLのチュートリアルや言語リファレンスがまとめられています。サンプルクエリも多く用意されています。
Pluralsight オンラインレクチャー
Pluralsight "Kusto Query Language (KQL) from Scratch"
- こちらも英語ですが、テクノロジー学習用サイト Pluralsight で、イントロダクションから高度なオペレーターの利用方法まで、一通り学べるコースが用意されています。
Kusto 100+ Knocks
https://azure.github.io/fta-kusto100knocks/ja/
: Microsoft 社の Fast Track for Azure チームから、Kusto の Basic から Advanced な内容まで、大量のサンプルクエリとともに学べるサイトが提供されています
本記事で利用するデモサイト
本記事では、こちらのデモ環境を利用していきます。
すでにログが収集され、実際にクエリをたたくことができる Azure Portal へアクセスできる方であれば誰でも利用可能なデモ環境が提供されています。上記のリンク先がLog Analyticsの分析ポータルになっており、すぐにクエリの実行が可能です。Windows セキュリティログ、AAD サインインログ、Monitor ログ(VM, コンテナー)、NSGフローログ、Azureリソースログ(SQL DB, AppGWなど)などが収集されており、様々なクエリをデータを実際に集めることなく試すことができます。
よく使われるオペレーターの使い方を実際のクエリとともに見ていく
本稿では、上記 Pluralsignt のコースでも "80% of the Operators You'll Ever Use" として紹介されている Log Analytics でよく使われるオペレーターを中心に見ていきたいと思います。
search - 特定の文字列を検索するオペレーター
文法:特定のキーワードを含むレコードを抜き出す
search <keyword>
例:SigninLogs テーブルから"Alex"という単語が入っているレコードを取り出す
SigninLogs | search "Alex"
または
search in (SigninLogs) "Alex"
正規表現もサポートしており、例えば以下のようなクエリを書くこともできます。(ただしアスタリスクはクエリのパフォーマンス観点であまり利用しすぎないことが推奨になっています。)
例:SigninLogs テーブルから"And"で始まる単語が入っているレコードを取り出す
SigninLogs | search "And*"
where - 条件を加えていくオペレーター
文法:特定の条件を満たすレコードを抜き出す。
| where <条件>
例1:SigninLogs テーブルから、1時間以内のログを抜き出す。
SigninLogs
| where TimeGenerated > ago(1h)
・TimeGenerated:ログの生成時間
・ago (<時間;1m(1分)、1h(1時間)、1d(1日)など>):現在時刻から<時間>前、上記のように使われます。
例2:SigninLogs テーブルから、特定の時間内のログを抜き出す。(実際に利用する際は、datetimeの中を直近のものに変更してください。)
SigninLogs
| where TimeGenerated > datetime(2023-01-01) and TimeGenerated < datetime(2023-01-02)
・datetime:datetime 型の定数を定義するためのリテラル。ISO 8601 形式で使うのが推奨。
・and:where 句の中で条件を複数並列で利用する際に利用。
例3:上の時間設定を満たし、かつサインインロケーションが"JP"のものに絞る。
SigninLogs
| where TimeGenerated > datetime(2023-01-01) and TimeGenerated < datetime(2023-01-02)
| where Location == "JP"
take - テーブルからの N 個のレコードをランダムに取ってくるオペレーター
文法:N個 だけレコードを取ってくる
take <N>
例:SigninLogs テーブルから10レコードだけ取ってくる
SigninLogs | take 10
*注意点:takeではどのレコードが取られるかは保証されません。サンプルを簡単に確認したい際にクエリ時間を短く取ってくることができます。
sort - 特定の列でソートするオペレーター
文法:あるフィールドの値で昇順・降順でソート
sort N by <フィールド> [asc | desc] [nulls first | nulls last]
例:SigninLogs テーブルから TimeGenerated フィールドで降順でソート
SigninLogs | sort by TimeGenerated desc
結果のフィールドをクリックしてもソート可能ですが、クエリ内で書いてしまうこともできます。
top - 上位N個のレコードを抜きだすオペレーター
文法:あるフィールドの値で上位N個を抜き出す
top N by <フィールド> [asc | desc] [nulls first | nulls last]
例:SigninLogs テーブルから TimeGenerated フィールドを参照し、直近10個のレコードを取り出す。
SigninLogs | top 10 by TimeGenerated desc
count - レコードの数を数えるオペレーター
文法:レコードを数える
count
例:SigninLogs テーブルのレコード数を数える
SigninLogs | count
・count はアラートを上げる時によく利用されます(例、特定の単語を含むログが1個以上出てきたら、アラートを出すなど)。
project - 表示するフィールドを選択するオペレーター
文法:表示するフィールドを指定
project <フィールド名>
例:SigninLogsテーブルから、TimeGenerated, UserDisplayName, Location, RiskState, RiskLevelDuringSignIn のみを表示
SigninLogs
| project TimeGenerated, UserDisplayName, Location, RiskState, RiskLevelDuringSignIn
project-away - 表示しないフィールドを指定
文法:表示しないフィールドを指定
project-away <フィールド名>
例:OperationVersion と Category をテーブルで表示しないようにする
SigninLogs
| project-away OperationVersion, Category
・各種ログは実利用では不要なフィールドもあるため、必要に応じて project と project-away を使い分けます。
project-rename - 表示するフィールド名を変える
文法:もともとのフィールド名を新しいフィールド名に変える
project-rename <新しいフィールド名> = <古いフィールド名>
例:"Location"フィールドを、"Country" フィールドに変更する
SigninLogs | project-rename Country = Location
extend - 新しいフィールドを作成するオペレーター
文法:新しいフィールドを追加する
extend <新しいフィールド名> = 計算式
例:LocationDetails の中に入っている値を parse_json 関数を用いて抽出し、LocationDetails_parsed という新しいフィールドを作成。さらに、City = LD.City として、フィールドを整理。
SigninLogs
| extend LocationDetails_parsed = parse_json(LocationDetails)
| project TimeGenerated, UserDisplayName, Location, City=LocationDetails_parsed.city
・新しいフィールドを作成する extend は最も良く使うことになるオペレーターの一つです。たとえば、上記では JSON で入っているフィールドの値から、新しいフィールドを別建てで用意しています。
・parse_json:JSON 形式で格納された String データをパースし、Kusto 上で JSON (Dynamic 型) として扱えるようにするものです。上記では、LocationDetails_parse は Dynamic 型のフィールドとなり、LocationDetails_parsed.city で Key=city のデータを簡単に扱えています。
summarize
summarizeは、アグリゲーションを行う、重要なオペレーターです。
文法:アグリゲーション関数、条件に沿って集約を行う
summarize [新しいフィールド名 =] <アグリゲーション関数> by <条件>
例1:Location ごとのサインインのログレコードの数を Singin_Count として集計する
SigninLogs | summarize Singin_Count = count() by Location
例:特定のロケーションのサインインのログレコードの数を、Hourly_Singin として 1時間ごとに集計する
SigninLogs
| where Location in ("AU", "CN", "JP", "US", "KR")
| summarize Hourly_Singin = count () by Location, bin(TimeGenerated, 1h)
・in:ここでは、where句の絞り込みで、要素のいずれかに等しいとできる in を利用しました。
bin - 丸め込みを行うオペレーター(よくsummarize と一緒に利用される)
文法:特定の単位にまとめる
bin(ターゲットの値、丸め込みの単位)
例:数字を丸め込む
bin(4.5, 1)
--> 4.0
例:日にちを丸め込む
bin(datetime(1970-05-11 13:45:07), 1d)
--> datetime(1970-05-11)
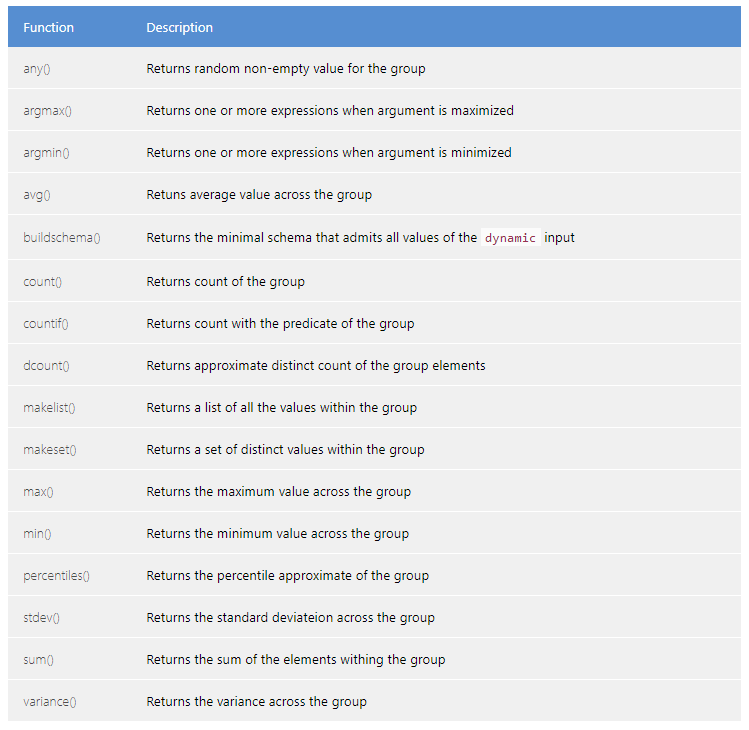
summarize で使われるアグリゲーション関数
count () の他にも多くのアグリゲーション関数が用意されています。
render
上記のクエリは、グラフにすることができます。折れ線グラフだと時間変化が簡単に追えます。
文法:グラフのタイプを指定し、表ではなくグラフで表示
render <グラフのタイプ>
例:さきほどの SigninLogs のサインイン回数の時間ごとの表を折れ線グラフ化。
SigninLogs
| where Location in ("AU", "CN", "JP", "US", "KR")
| summarize Hourly_Singin = count () by Location, bin(TimeGenerated, 1h)
| render timechart
render のあとの値を変えることで他のタイプのグラフに変えられます。また、GUI でグラフの書式設定で変えることもできます。
distinct - 重複排除し、特定の組み合わせ表を作成するオペレーター
文法:あるフィールドに関して重複排除した表(複数の場合は組み合わせ表)を表示する
distinct <フィールド1>, <フィールド2>, ‥
例:ぱっと見分かりにくいかもしれないですが、たとえば下記のクエリだとアクセス元の国一覧を簡単に取ることができます。
SigninLogs | distinct Location
join - 2つのテーブルを結合するオペレーター
join を使うことで2つのテーブルを結合し、1つのクエリで両方のテーブルのデータを参照できます。join で複数のテーブルの行を1つの結果として結合します。
文法:各テーブルに一致する値を持つ列を基にレコードを結合
Table1
| join (Table2) on <共通の列名> // または $left.<Table1の列名> = $right.<Table2の列名>
例:VMComputer テーブル (Azure Monitor for VMs で各仮想マシンの基本情報を収集しているテーブル)と InsightsMetrics (Azure Monitor で各サービスのメトリックを収集しているテーブル)を結合。仮想マシンの物理メモリ容量と利用中に空いているメモリ容量を一行にまとめて、メモリ利用率を計算し表示するようにする。(こちらのドキュメントから拝借。)
VMComputer
| distinct Computer, PhysicalMemoryMB
| join kind=inner (
InsightsMetrics
| where Namespace == "Memory" and Name == "AvailableMB"
| project TimeGenerated, Computer, AvailableMemoryMB = Val
) on Computer
| project TimeGenerated, Computer, PercentMemory = AvailableMemoryMB / PhysicalMemoryMB * 100
・join の kind:内部結合、完全外部結合など、結合の種類を設定することができます。デフォルトは、左側の重複を除去する内部結合になっています。
let - 変数を定義し、数やテーブルの計算結果を代入するオペレーター
文法:変数名を定義し、数やテーブル名を代入
let val1 = <具体的な数や文字列など>
let table1 = Table 1 (| where ~ | project ~ )
例1:時刻を予め定義して条件式で利用
let startTime = datetime(2023-01-01);
let endTime = datetime(2023-01-02);
SigninLogs
| where TimeGenerated > startTime and TimeGenerated < endTime
例2:テーブルを変数に代入し、joinのクエリを簡潔にする
let PhysicalComputer = VMComputer
| distinct Computer, PhysicalMemoryMB;
let AvailableMemory = InsightsMetrics
| where Namespace == "Memory" and Name == "AvailableMB"
| project TimeGenerated, Computer, AvailableMemoryMB = Val;
PhysicalComputer
| join kind=inner (AvailableMemory) on Computer
| project TimeGenerated, Computer, PercentMemory = AvailableMemoryMB / PhysicalMemoryMB * 100
最後に
詳細は以下のリファレンスで各オペレーターの説明をご参照ください。
本稿が、Log Analytics など Kusto (KQL) を利用して検索を行うサービスを使い始める際の一助となれば幸いです。また、次稿・次々稿ではさらに色々な演算子を見ていただき、Kusto でも複雑なクエリを扱えることをご体験いただければと思います。
*本稿は、個人の見解に基づいた内容であり、所属する会社の公式見解ではありません。また、いかなる保証を与えるものでもありません。正式な情報は、各製品の販売元にご確認ください。