初めましての方は初めまして.そうでない方はいつもありがとうございます.
タイトルにもあるように,今更ですが本記事ではかの有名な論文"Attention Is All You Need."を読んでみようというものです.解説したい所ですが,既に偉大な先人方が分かりやすい記事を書かれており,到底,学生の身分である私では太刀打ちできません.
学生なりの理解を見てやっても良いよって方は覗いてみて下さい.
では,前置きはこれくらいにして,見ていきましょう!
本記事では,BackgroundとModel Architectureを見ていきます.
また,以下の英文和訳にはDeepLを使用しています.
Background
先ずは原文を.
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU [20], ByteNet [15] and ConvS2S [8], all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions [11]. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations [4, 22, 23, 19].
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence- aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks [28].
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence- aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [14, 15] and [8].
第1段落 1文目
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU [20], ByteNet [15] and ConvS2S [8], all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions.
逐次計算を減らすという目標は、Extended Neural GPU [20]、ByteNet [15]、ConvS2S [8]の基盤にもなっており、これらはすべて畳み込みニューラルネットワークを基本構成ブロックとして使用し、すべての入出力位置に対して並列に隠れ表現を計算する。
この頃に発表されたモデルは,逐次計算を減らすという目的のものがトレンドだったようです.AbstractやIntroductionで紹介されていたRNNモデルではこれを達成するのが難しいためか,CNNモデルが利用されているようです.
第1段落 2~3文目
In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions [11].
これらのモデルでは、2つの任意の入力または出力位置からの信号を関連付けるために必要な演算の回数は、位置間の距離に応じて、ConvS2Sでは線形に、ByteNetでは対数的に増加する。そのため、離れた位置同士の依存関係を学習することが難しくなる[11]。
逐次計算を克服したCNNモデルにも弱点があるようで,長距離依存関係の学習が難しいみたいです.
演算回数において,ByteNetの対数的に増加することがどれほどの影響を持つのかについては疑問が残りますが,少なくともConvS2Sの線形に増加するのは問題がありそうです.例えば,1000字程度の翻訳(今どきは珍しいものでも無いかなと思っていますが)をおこなうことを考えたときに,テキトーに半分を仮定して,約500字間の単語の関係を学習するのに(ConvS2Sの場合は)500倍の演算回数が必要になるということになります.
第1段落 4文目
In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
Transformerでは、Attentionによって重み付けされた位置が均等になるため、有効な解像度が低下するが、これは3.2節で説明する Multi-Head Attentionによって打ち消される。
Transformerでは,並列計算 & 長距離依存関係の学習を達成したのですね.
第2段落
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations [4, 22, 23, 19].
Self-attention(intra-attentionと呼ばれることもある)は、系列の表現を計算するために、1つの系列の異なる位置を関連付けるattentionメカニズムである。Self-attention は、読解、簡潔な要約、文章含意、課題に依存しない文章表現の学習など、さまざまなタスクでうまく利用されている[4, 22, 23, 19]。
Self-attentionはその名の通りで,1つの系列 (Self) のattentionをおこなうメカニズムということらしいです.また,色々なタスクにも利用できるというのは魅力的ですね.
第3段落
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence- aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks [28].
End-to-endの記憶ネットワークは、配列に沿った再帰ではなく、再帰的なattentionメカニズムに基づいており、単純な言語による質問応答や言語モデリングタスクで優れた性能を発揮することが示されている [28]。
「End-to-endの記憶ネットワーク」の説明の部分はよく理解できませんでしたが,とにかく再帰的なattentionメカニズムが良いということがこれまでの研究で分かっているということなのでしょう.
第4段落
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [14, 15] and [8].
しかし、我々の知る限り、Transformerは、配列整列RNNや畳み込みを使用せずに、入力と出力の表現を計算するためのSelf-attentionに完全に依存した最初の伝達モデルである。以下のセクションでは、Transformerについて説明し、self-attentionを説明し、[14, 15]や[8]のようなモデルに対する優位性について議論する。
RNNの逐次計算を要する性質やCNNの長距離依存関係の計算が困難である性質を解消するのではなく,そもそもそうしたものを使用しないで(ほぼ)全く新しいものを作り上げたということなのですね.これまでの徐々に改良していく流れを断ち切って新しいアークテクチャを提案できたからこそ,こんなにも指示される論文ができたのかなと思いました.
Model Architecture
先ずは原文を.
Most competitive neural sequence transduction models have an encoder-decoder structure [5, 2, 29]. Here, the encoder maps an input sequence of symbol representations $(x_1, ..., x_n)$ to a sequence of continuous representations $\mathbf{z} = (z_1, ..., z_n)$. Given $\mathbf{z}$, the decoder then generates an output sequence $(y_1, ..., y_m)$ of symbols one element at a time. At each step the model is auto-regressive [9], consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
第1段落
Most competitive neural sequence transduction models have an encoder-decoder structure [5, 2, 29]. Here, the encoder maps an input sequence of symbol representations $(x_1, ..., x_n)$ to a sequence of continuous representations $\mathbf{z} = (z_1, ..., z_n)$. Given $\mathbf{z}$, the decoder then generates an output sequence $(y_1, ..., y_m)$ of symbols one element at a time. At each step the model is auto-regressive [9], consuming the previously generated symbols as additional input when generating the next.
ほとんどの競合するニューラル配列伝達モデルは、エンコーダーとデコーダーの構造を持っている[5, 2, 29]。ここで、エンコーダは、入力された記号表現列$(x_1, ..., x_n)$を連続表現列$\mathbf{z} = (z_1, ..., z_n)$に写像する。与えられた$\mathbf{z}$から、デコーダは記号の出力列$(y_1, ..., y_m)$を1度に1要素ずつ生成する。各ステップにおいて、モデルは自己回帰的であり[9]、次の記号を生成する際に、以前に生成された記号を追加入力として受け取る。
先ず,エンコーダ・デコーダについて説明しています.
ここで説明されているようなエンコーダ・デコーダについては,少し検索すれば偉大な先人の方々の非常に分かり易い説明がたくさん出てくるので詳細は触れません.(このシリーズが完結して,それなりに見られていれば補足説明をするかもしれません.)
第2段落
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
Transformerは、図1の左半分と右半分にそれぞれ示されているように、エンコーダーとデコーダーの両方に、重ねたself-attentionとpoint-wise, 全結合層を使用し、この全体的なアーキテクチャを踏襲している。
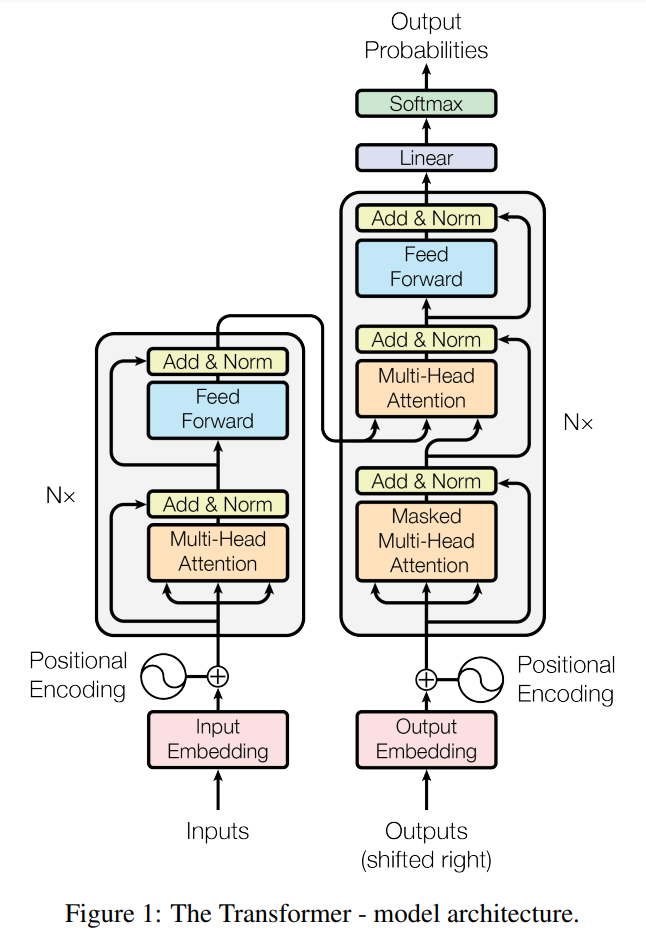
ついに,非常に有名な例の図の登場です.
図の左側がエンコーダ,右側がデコーダです.全く何もかもが新しいというわけではなく,エンコーダ・デコーダアーキテクチャは踏襲しているとのことです.
Encoder and Decoder Stacks
先ずは原文を.
Encoder: The encoder is composed of a stack of $N = 6$ identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection [10] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is $LayerNorm(x + Sublayer(x))$, where $Sublayer(x)$ is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $d_{model} = 512$.
Decoder: The decoder is also composed of a stack of $N = 6$ identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
第1段落 1文目
Encoder: The encoder is composed of a stack of $N = 6$ identical layers.
エンコーダー: エンコーダーは$N = 6$の同一レイヤーの積み重ねで構成される。
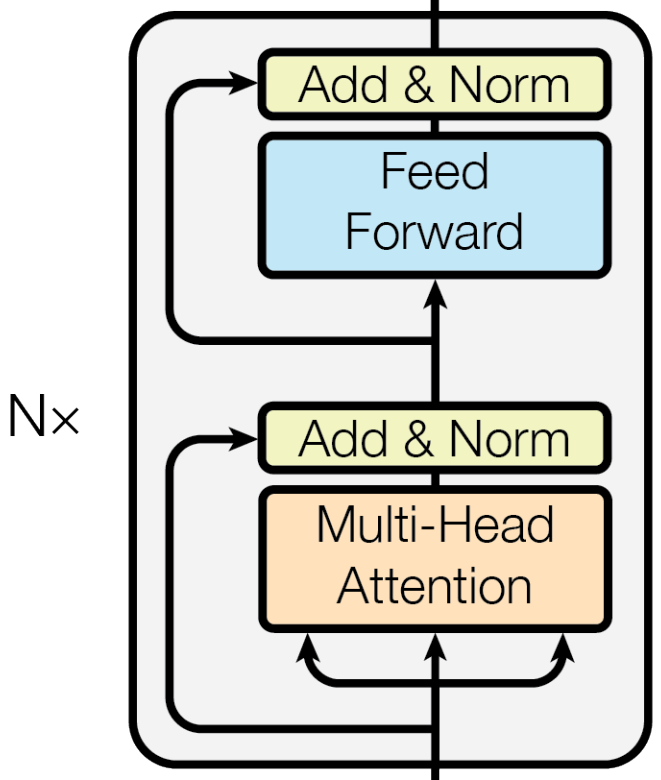
上図のエンコーダブロックは6つ重ねてエンコーダを構成するようです.
第1段落 2~3文目
Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network.
各レイヤーには2つのサブレイヤーがある。1つ目はmulti-head self-attentionメカニズムであり、2つ目は単純な位置ワイズ全結合feed-forwardネットワークである。
ここでは上図の説明がされています.1つ目のサブレイヤーはオレンジ色で示されている部分で,2つ目のサブレイヤーは水色で示されている部分です.
第1段落 4~5文目
We employ a residual connection [10] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is $LayerNorm(x + Sublayer(x))$, where $Sublayer(x)$ is the function implemented by the sub-layer itself.
2つのサブレイヤーそれぞれに残差接続[10]を採用し、レイヤーの正規化[1]をおこなう。つまり、各サブレイヤーの出力は$LayerNorm(x + Sublayer(x))$であり、$Sublayer(x)$がサブレイヤー自身によって実装された関数である。
ここでは残差接続(上図の黄色の部分)について説明されています.サブレイヤーの入力を出力にスキップする機構とレイヤーの正規化をおこなっています.
第1段落 6文目
To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $d_{model} = 512$.
このような残差接続を容易にするために、埋め込み層と同様に、モデルのすべてのサブレイヤーは、次元$d_{model} = 512$の出力を生成する。
残差接続(サブレイヤーの入力)とサブレイヤーの出力の次元が異なると$x + Sublayer(x)$が(単純には)定義できないため,全て512次元にしましょうということです.
第2段落 1文目
Decoder: The decoder is also composed of a stack of $N = 6$ identical layers.
デコーダー: デコーダーもまた、$N = 6$の同一レイヤーの積み重ねで構成される。
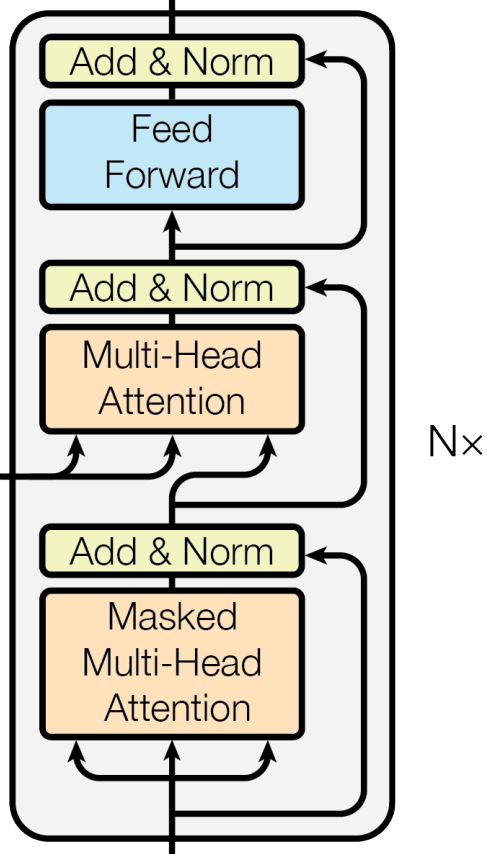
上図のデコーダブロックも6つ重ねてデコーダを構成するようです.
第2段落 2~3文目
In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization.
各エンコーダーレイヤーの2つのサブレイヤーに加えて、デコーダーは第3のサブレイヤーを挿入し、エンコーダ積層からの出力に対してmulti-head attentionを実行する。エンコーダーと同様に、各サブレイヤーに残差接続を採用し、レイヤーの正規化をおこなう。
デコーダもエンコーダと同様,サブレイヤーから構成されており,最も上のレイヤー (Feed Forward) と最も下のレイヤー (Masked Multi-Head Attention) については,エンコーダのサブレイヤーと(ほぼ)同じです.
またここでは,デコーダのサブレイヤーのうち,真ん中のMulti-Head Attentionについて説明しており,エンコーダの出力を受け取っています.
第2段落 4~5文目
We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
また、デコーダ積層内のself-attentionサブレイヤーを修正し、後続の位置に情報が伝わらないようにする。このマスキングと、出力の埋め込みが1つずれていることで、位置$i$の予測は$i$より前の位置の既知の出力にのみ依存することができる。
先程,(ほぼ)同じと述べた最も下のレイヤーについてですが,演算の際にその位置以降の出力については隠されているようです.これを実現するための具体的な実装については後の章で記述されるので,ここではこの程度にして流しておきます.
イメージの話ですが,例えば「私は学生です。」という文章を翻訳することを仮定すると,モデルは"I *** a student."に対して全てを用いることはできず,日本語文と"I"から"am"を推定するようになっているということかなと思います.("a student."の部分を何故使ってはならないかという点については個人的に疑問が残っていますが......)
最後に
ここまで読んで頂きありがとうございました.
研究室に配属されて2年目のひよっこ学部生が書いている記事なので,間違い等があればぜひご教示頂きたいです.(お手柔らかにお願いします!)
次回は引き続きModel Architectureの章を読み進めていきたいと思います.更新は片手間におこなっているので次がいつになるかは未定ですが,もしよろしければ次をお待ち下さい!