はじめに
最新の大規模言語モデルを使ってみたいがなかなか手が出ない.Nvidia製のGPUが高すぎる……
そんな需要があり,研究室にMac Studioが導入されました.
Nvidia製のGPUではなくMac Studioを用いる理由については,既に多くの方々が検証してくださっているので,そちらを参照ください!
あくまで一例です.
注意が必要なのは,現時点ではMac StudioでのLLMの学習ができないという点で,そのため本記事でも推論のみに焦点を当てて選定しています.
今回の要件
今回,研究室で利用するため,多くの学生が使えるよう,遠隔での操作が可能であるように求められました.より具体的には「CLI,もしくは,APIでの実行が可能であること」というものです.
そのために必要な設定について,項目ごとに分けながら取り扱っていきたいと思います.
- Mac Studioの基本設定
- Ollamaのインストール
- Open WebUIのセットアップ
また上記に加えて,Pythonから使えるようにOllama-Pythonライブラリを用いた実装も確認します.
1. Mac Studioの基本設定
まずは起動からですが,こちらはiPhoneやMac Bookと基本的には変わらず,分かりやすいトラブルシューティングが多いため割愛します.以下,起動後からです.
先にも述べたように,Mac Studioを遠隔から操作できるようにしたいと考えているため,SSHで接続できるようにします.
手順としては次のようになります.
- Macのリモートログインの許可
- スリープモードの解除
- SSHキーの生成と登録
1-1. Macのリモートログインの許可
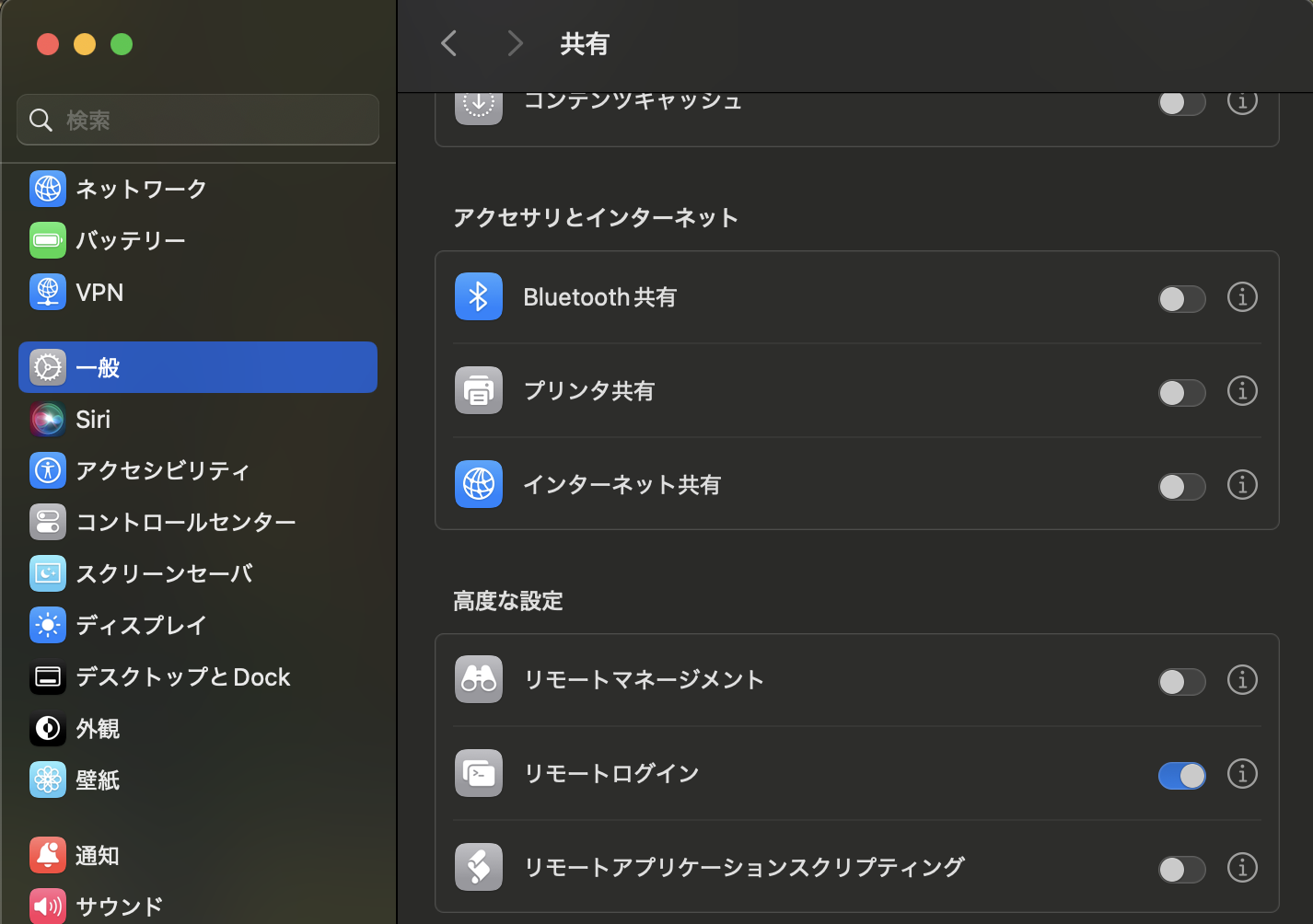
Mac Studioはデフォルトでリモートからのアクセスが拒否されています.そのためSSHからの接続を許可してやる必要があります.詳細な方法については,Appleの公式ドキュメントを参照してもらうのが良いかと思いますが,簡単に本記事でも紹介します.
設定を開き,「一般」の項目から「共有」を選択し,高度な設定にある「リモートログイン」を有効にしてください.(最下までスクロールする必要があります)
1-2. スリープモードの解除
次に,スリープモードの解除をおこないます.
LLMからのレスポンスが非常に長い場合に,Mac Studioがスリープモードに移行してしまい,適切な結果が得られないということが度々発生します.それを回避するためにこの設定をおこないます.
設定から「エネルギー」の項目を選択し,以下の項目が全て有効になっているかを確認してください.
- ディスプレイがオフの時に自動でスリープさせない
- ネットワークアクセスによるスリープ解除
また,「停電後に自動的に起動」の項目は有効・無効のいずれでも問題ありません.
1-3. SSHキーの生成と登録
最後に,SSHキーの生成と登録をおこないます.
こちらについては,新入生によく共有している非常にわかりやすい記事があり,そちらで代用させていただきます.
公開鍵が登録でき,SSH接続できれば,基本的にどのような方法でも問題ありません.
2. Ollamaのインストール
今回はOllamaを用いてLLMのための環境構築をおこないます.
先にも言及しているように,CLIもしくはAPIでの実行ができるようにしたいと考えており,その条件に合致したものがOllamaでした.
上記の公式ページからOllamaをダウンロードしてください.ダウンロード方法は他のアプリと同じです.
ダウンロード完了すると,ターミナル上で以下のコマンドが使用できるようになります.
~$ ollama -v
ollama version is 0.4.2
上記のようにバージョン情報が表示されれば成功です.
基本的なコマンドだけここで紹介しておきたいと思います.
LLMのダウンロード
~$ ollama pull <model name>
LLMの起動
~$ ollama run <model name>
ダウンロード済みLLMの一覧表示
~$ ollama list
Ollamaサーバの立ち上げ
今回は,これがメイン.
~$ ollama serve
デフォルトでは http://localhost:11434 でOllamaのサーバが立ち上がります.
OllamaをAPI経由で利用可能にする
今回はリモートからMac StudioにアクセスしてLLMの出力を得たいのですが,それを簡単に実現する機能として,Ollamaではサーバを建てる機能が提供されています.
様々な環境変数が用意されており,それらの設定が必要ですが,私の設定を例として掲示しておきます.
#!/bin/sh
export OLLAMA_ORIGINS=http://<your_network_ip>/
export OLLAMA_HOST=0.0.0.0:11435
export OLLAMA_KEEP_ALIVE=1m # 必須ではない
export OLLAMA_MAX_QUEUE=10 # 自身の環境に合わせて調整
export OLLAMA_FLASH_ATTENTION=true # 基本的にはtrue
export OLLAMA_NUM_PARALLEL=3 # 自身の環境に合わせて調整
LOGFILE="log_$(date +'%Y-%m-%d_%H-%M-%S').log"
nohup ollama serve > $LOGFILE 2>&1 &
OLLAMA_HOSTについての補足ですが,デフォルトのポートと被るため11435を選択しています.また,0.0.0.0が許されるかどうかは十分に検討してください.(今回はローカルネットワーク環境でのみ,期間限定での展開のため利用)
上記の環境変数ついては,公式ドキュメントやコードを参照するか,以下のコマンドで確認できます.
~$ ollama serve --help
Start ollama
Usage:
ollama serve [flags]
Aliases:
serve, start
Flags:
-h, --help help for serve
Environment Variables:
OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1)
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m")
OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models per GPU
OLLAMA_MAX_QUEUE Maximum number of queued requests
OLLAMA_MODELS The path to the models directory
OLLAMA_NUM_PARALLEL Maximum number of parallel requests
OLLAMA_NOPRUNE Do not prune model blobs on startup
OLLAMA_ORIGINS A comma separated list of allowed origins
OLLAMA_SCHED_SPREAD Always schedule model across all GPUs
OLLAMA_TMPDIR Location for temporary files
OLLAMA_FLASH_ATTENTION Enabled flash attention
OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection
OLLAMA_GPU_OVERHEAD Reserve a portion of VRAM per GPU (bytes)
OLLAMA_LOAD_TIMEOUT How long to allow model loads to stall before giving up (default "5m")
3. Open WebUIのセットアップ
先の手順で既にOllamaのREST APIが有効になっているため,curlコマンドを叩けば利用できますが,コマンドやREST APIに不慣れな人にとっては難易度が高いだけでなく,慣れている人にとっても面倒な操作になります.
そのため,ブラウザ経由でOllamaを利用できるようにOpen WebUIを導入します.
上記のドキュメント内でインストール方法についての詳細な説明がありますが,今回はDockerを利用したリモートアクセスの場合に習って構築します.そのため,Dockerが利用可能であることが必須となります.
また,本手順については先ほどまで操作していたサーバ上で実行する必要はなく,手元のPCで操作してください.
~$ docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://<ollama server ip>:11435 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
上記のコマンドを簡単に説明すると,
-
-d:デタッチモードでコンテナを起動 -
-p 3000:8080:ホストの3000番ポートとコンテナの8080番ポートを接続.ホスト側のポート番号は任意. -
-e OLLAMA_BASE_URL=http://<ollama server ip>:11435:OLLAMA_BASE_URLの環境変数を設定- 接続先のOllamaサーバを指定
-
-v open-webui:/app/backend/data:ボリュームの設定- 会話履歴などの永続化
-
--name open-webui:コンテナ名の指定.任意の名前で可. -
--restart always:コンテナを常時起動.利用がない場合でも起動したままにする設定. -
ghcr.io/open-webui/open-webui:main:イメージ名
となります.
コンテナが無事に立ち上がれば, http://localhost:3000 にアクセスすることでブラウザ経由でOllamaが利用できるようになります.
4. Ollama-Pythonのインストール
LLMを使ってみるという目的であればOpen WebUIで十分かなと思いますが,研究目的で利用する場合はどうしてもコード内で利用できた方が使い勝手が良いかなと思います.
そこで用意されているライブラリがOllama-Pythonというものです.
インストールは非常に簡単で,pip install ollamaで完了です.
また,基本的なコーディングサンプルなどはリポジトリ内に示されているので,そちらを参考にすれば解決できそうですが,少し込み入ったことをする場合はまだドキュメントが完成されていないということもあり,リポジトリ内を精読する必要が出てきそうです.
蛇足になりますが,練習がてら作成した「arXivから論文を取得してLLMに要約させる」スクリプトを掲示しておきます.どなたかの参考になれば.
import os
import glob
import datetime as dt
from icecream import ic
from dotenv import load_dotenv
import arxiv
import pymupdf4llm
from ollama import Client
from tenacity import retry, stop_after_attempt, wait_fixed
##################################################
############ Variables and Constants #############
##################################################
MODEL = 'command-r-plus' # Max Tokens: 128K
# MODEL = 'llama3.1:70b' # Max Tokens: 128K
OPTIONS = {
'num_ctx': 128_000, # Input length: 128k
'temperature': 0.0, # Stable output
'seed': 42, # Random seed
}
PAPER_ID = '2201.11903' # Chain-of-Thought
##################################################
load_dotenv()
run_dt = dt.datetime.now().strftime('%Y%m%d_%H%M%S')
def get_paper_content(paper_id: str) -> str:
'''
Get the content of the paper from the arXiv.
Args:
paper_id (str): Paper ID
Returns:
str: Content of the paper in Markdown format
'''
client = arxiv.Client()
paper = next(client.results(arxiv.Search(id_list=[paper_id])))
os.makedirs(os.getenv('PAPER_DIR'), exist_ok=True)
paper.download_pdf(os.getenv('PAPER_DIR'))
paper_list = glob.glob(os.path.join(os.getenv('PAPER_DIR'), '*.pdf'))
target_paper = [paper for paper in paper_list if paper_id in paper][0]
pdf = pymupdf4llm.to_markdown(target_paper)
return pdf
@retry(stop=stop_after_attempt(3), wait=wait_fixed(10))
def ask_llm(client: Client, prompt: str, model: str=MODEL, options: dict=OPTIONS, verbose: bool=True) -> tuple[int, int, float, float, str]:
'''
Ask to the LLM model and return the response.
Args:
client (Client): Ollama Client
prompt (str): Prompt text
model (str): Model name. Default is MODEL.
options (dict): Options for the model. Default is OPTIONS.
verbose (bool): Verbose flag. Default is True.
Returns:
tuple[int, int, float, float, str]:
- Prompt Length: Length of the prompt tokens
- Response Length: Length of the response tokens
- Throw Time: Time to throw the prompt
- Response Time: Time to generate the response
- Answer: Generated answer
'''
if verbose:
ic()
response = client.generate(
model=model,
prompt=prompt,
options=options,
)
prompt_length = response['prompt_eval_count']
response_length = response['eval_count']
throw_time = response['prompt_eval_duration'] / 1000 / 1000 / 1000 # [nsec] -> [sec]
response_time = response['eval_duration'] / 1000 / 1000 / 1000 # [nsec] -> [sec]
prompt_token_per_sec = prompt_length / throw_time
response_token_per_sec = response_length / response_time
run_report = {
'prompt_token_per_sec': prompt_token_per_sec,
'response_token_per_sec': response_token_per_sec,
'prompt_length': prompt_length,
'response_length': response_length,
'throw_time': throw_time,
'response_time': response_time,
}
answer = response['response']
return run_report, answer
pdf = get_paper_content(PAPER_ID)
for_shot_summary_name = 'sample_summary.md'
with open(for_shot_summary_name, 'r') as fp:
for_shot_summary = fp.read()
summary_template = '''
### どんな研究?
### 関連研究との相違点は?
### 技術や手法の要点は?
### 検証方法は?
### 注目すべき結果は?
'''
prompt = f'''
以下で<template></template>で囲まれた部分に示されたテンプレートに従って,<paper>以下の論文を要約してください.
要約の一例を示します.
要約:{for_shot_summary}
以下が要約のテンプレートであり,これに従って<paper>以下の要約をおこなってください.
<template>
{summary_template}
</template>
<paper>
{pdf}
'''
client = Client(
host=os.getenv('OLLAMA_HOST'),
)
run_report, answer = ask_llm(client, prompt)
ic.enable()
ic(run_report)
print(f'{run_report = }')
print(f'Answer: {answer}')
os.makedirs(os.getenv('SUMMARY_DIR'), exist_ok=True)
filepath = os.path.join(os.getenv('SUMMARY_DIR'), f'{PAPER_ID}_summary_{run_dt}.md')
with open(filepath, 'w') as fp:
fp.write(f'{run_report = }\n')
fp.write(f'{answer}\n')
最後に
いかがでしたでしょうか?
一連のセットアップ方法について説明している記事が少なかったため,メモがてら記事を書いてみました.
急速に進化している分野で,古くなってしまっているドキュメントが多く,その点で(自身の環境における)正解を見つけるのに1日も要してしまいました.後の誰かのためになればと思います.
また,本記事ではサクッと進めた各セクションごとのより詳細な説明は,偉大な先人の方々が記事を投稿してくださっているため,そちらを当たってもらえればと思っています.