はじめに
まだ実務はしていないペーペーですが、公共データを利用し、分析をしたいなと思ったので、気象庁の地震データの分析を行ってみました。
学習の振り返りとともに、メモ代わりとしてまとめます。
目的・背景
地震についての情報を調べる中で、様々な機関で研究をされているものの、予知のような精度の高い地点・震度予測はまだできていないようです。
気象庁でも予知は難しいという旨を明言しています。
なので、今回の最終的なゴールとしては、
「過去106年分の地震データを機械学習させ、今後10日・30日における地域別発生確率の予測をする」
ということにしています。
使用環境・データ
データ
地震データ:震度3以上の地震情報
気象庁が公開している「震度データベース検索」から API 経由で取得しました。
出典:気象庁 震度データベース検索(https://www.data.jma.go.jp/eqdb/data/shindo/)
本記事では、API で取得した生データを CSV に変換し、可視化・加工したものを利用し、紹介しています。
これは気象庁が加工済みで公開したものではなく、筆者が編集したものです。
環境
CSV Googleスプレッドシート
実行 Google corabolatory
保存 Google ドライブ
分析過程
CSVデータを作成してみる
ここからは使用したコードの中身について、まとめていきます。
1919年1月1日が最古のデータになっています。
UIからCSVファイルを取得することも可能でしたが、最大件数が1000件までとなっており、手間がかかってしまうので、APIから一括取得する方式に変更してCSVデータを作成しました。
import time
import requests
import pandas as pd
from datetime import datetime, timedelta
API_URL = "https://www.data.jma.go.jp/eqdb/data/shindo/api/"
OUT_PATH = "jma_shindo_19192025.csv"#保存先
Requestsモジュールは、人の目にも分かりやすい形式でWebページやWeb APIにアクセスし、その結果を取得できます。
今回、年次ごとにデータを取得したいので、計算のためにtimedeltaもいれます。
APIのURLは、F12Network部分で確認しました。
BASE_PAYLOAD = {
"mode": "search", #条件検索
"mag[]": ["0.0", "9.9"],
"dep[]": ["000", "999"], #mag,depは範囲指定
"epi[]": ["99"],
"pref[]": ["99"], #全国
"city[]": ["99"], #全市町村
"station[]": ["99"], #すべての観測点
"obsInt": "3", #観測震度の下限
"additionalC": "false", #追加条件(詳細条件)を使うか
"Sort": "S0", # ソート順
"Comp": "C0", # 検索条件の比較モード
"seisCount": "false", # 地震一覧データを返す ※"true" にすると件数だけ返る
"observed": "false", # 観測済みデータ限定か ※"true" = 観測確定済みのみ(速報除外など)
}
ここで、取得データ内容指示をしています。
地震データベース検索のUIをたたいた際にAPIとして飛ぶ内容を、F12のNetworkで見てみた内容にPayloadがあります。
検索ボタンを押すと、実際に飛んでいる指示内容が確認できます。
この内容に則って、自身で指定をかけている状態です。
TIMEOUT = 30 #取得時間の設定をし、反応がなかったら失敗にする
SLEEP_SEC = 0.2 # アクセス過多を避ける
MAX_RETRY = 5 # 失敗したら最大5回までやり直す
MIN_GRANULARITY = timedelta(minutes=1) # 最小の時間幅として、1分単位にしている
def _post_with_retry(payload: dict) -> dict:
last_err = None #エラーの記憶箇所(exceptの場合)
for i in range(MAX_RETRY):
try:
r = requests.post(API_URL, data=payload, timeout=TIMEOUT) #取得条件
r.raise_for_status()#HTTPが 200番台じゃなければエラーを発生させる
return r.json() #内容をJSONとしPythonの辞書にして返す
except Exception as e:
last_err = e
time.sleep(1.0 * (i + 1)) #サーバーが一時的に混んでる時用
raise RuntimeError(f"API request failed after retries: {last_err}")
def fetch_range(dt_from: datetime, dt_to: datetime) -> list[dict]:
# [dt_from, dt_to] を1回で取得して res の list を返す
payload = dict(BASE_PAYLOAD) # 元変数を書き換えないように
# 年数
payload["dateTimeF[]"] = [dt_from.strftime("%Y-%m-%d"), dt_from.strftime("%H:%M")]
# 時間
payload["dateTimeT[]"] = [dt_to.strftime("%Y-%m-%d"), dt_to.strftime("%H:%M")]
data = _post_with_retry(payload)
rows = data.get("res", []) or [] #変な返り方をしても、必ずリストにするため
return rows
# 1000件制限を回避するため、区間を分割して全件取得する
def fetch_all(dt_from: datetime, dt_to: datetime) -> pd.DataFrame:
stack = [(dt_from, dt_to)]
collected = [] #集めた地震データを全部入れるリスト
seen_keys = set() #同じデータを二重に保存しない
while stack:
a, b = stack.pop()
rows = fetch_range(a, b)
time.sleep(SLEEP_SEC)
# 1000件に達しているなら、まだある可能性が高いので分割
if len(rows) >= 1000:
if (b - a) <= MIN_GRANULARITY:
# 1分まで分割しても1000件以上=このAPI仕様の範囲では取りきれない
raise RuntimeError(
f"Too many records even in minimal granularity range: {a} - {b} (rows={len(rows)})"
)
mid = a + (b - a) / 2 #期間の真ん中の日時を作る
# 端の取りこぼし防止のため、後半は mid+1分 ではなくそのまま mid を境界に分割
# (このAPIが両端含むか不明なので、重複は後で除去する)
#前半・後半の2つの期間をスタックに積む
stack.append((a, mid))
stack.append((mid, b))
continue
# 1000件未満なら確定として回収
for r in rows: #r は1件分の地震データ(辞書)
# 重複排除キー(APIの戻りにユニークIDがあればそれを優先)
# 汎用的に、発生時刻+震央+Mなどを連結してキー化(不足なら列を増やす)
key = (
str(r.get("ot", "")),
str(r.get("eid", "")),
str(r.get("mag", "")),
str(r.get("dep", "")),
str(r.get("lat", "")),
str(r.get("lon", "")),
)
if key in seen_keys:
continue
seen_keys.add(key)
collected.append(r)
print(f"OK {a} - {b} rows={len(rows)} total={len(collected)}")
# DataFrameでもできるが、辞書が入れ子の場合に備えてjson_normalizeを利用する
df = pd.json_normalize(collected)
# 安全のため時系列で並べる
sort_cols = [c for c in [ "ot"] if c in df.columns]
if sort_cols:
df = df.sort_values(sort_cols).reset_index(drop=True)
return df
今回は時系列データという部分が大事になってくるので、必ず時系列順に並び替えを行っています。
if __name__ == "__main__":
start = datetime(1919, 1, 1, 0, 0)
end = datetime(2025, 12, 31, 23, 59)
df_all = fetch_all(start, end)
df_all.to_csv(OUT_PATH, index=False, encoding="utf-8-sig")
print(f"saved: {OUT_PATH} rows={len(df_all)} cols={len(df_all.columns)}")
基本的には、このstart,endを変えることで自身の取得したい年月日の情報を一括でとってくることができます。
encoding="utf-8-sig"として、Excelで文字化けしにくい保存形式に変換をしています。
★取得した情報
・地震ID
・地震発生日
・震源地
・緯度
・経度
・深さ
・マグニチュード
・震度
データを観察してみる
目的変数や関連性を見るために、まずmatplotlibでヒストグラムや散布図を出してみました。
それぞれのデータがどのように発生しているのか、まずは発生回数に偏りがあるか調査してみました。
なお、ここでは1919年からの全データではなく、観測機器・方式などが現在に近い形となった1996年からのデータを用いて図示しています。
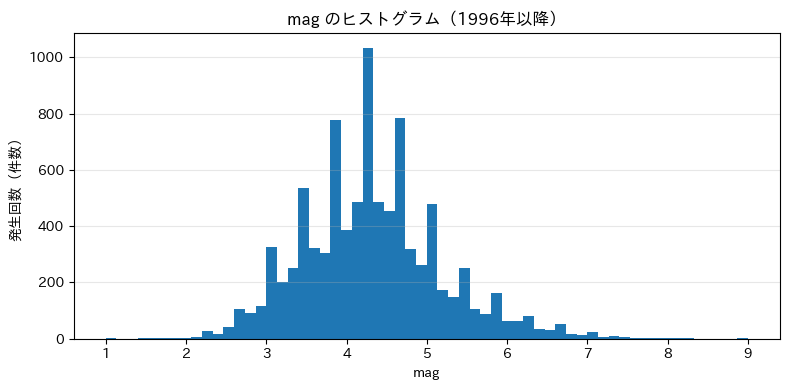
★ マグニチュード
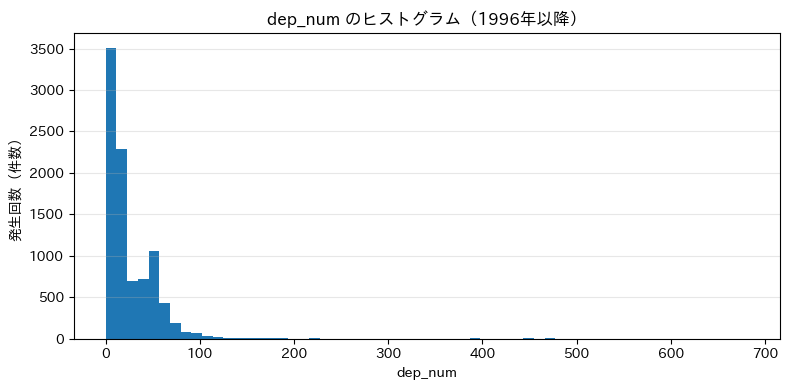
★ 深さ
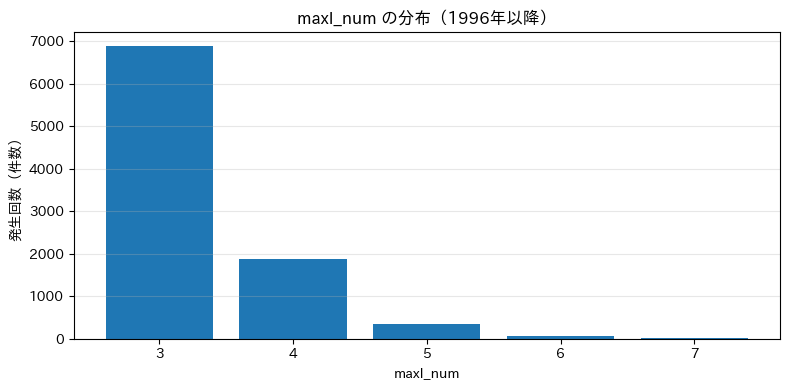
★ 震度
マグニチュードは釣り鐘型に近い形となっています。
dep_num、maxI_numは、深さと震度を数字に直したものです。
深さと震度は同一の動きをしていました。
大地震の発生回数はそれほど多くなく、かなりの不均衡データと言えそうです。
★発生年数・発生月・発生時間
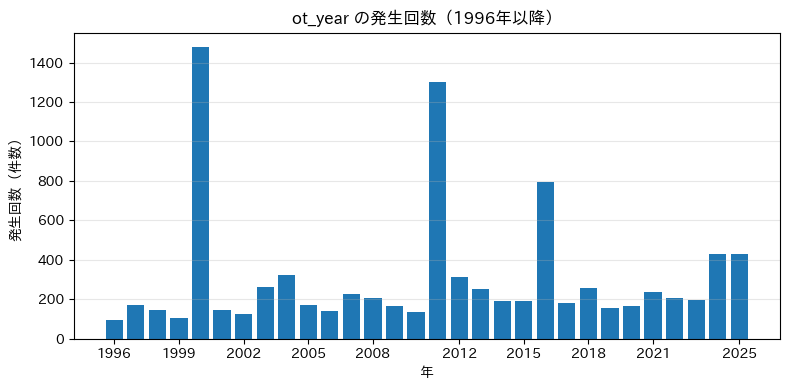
2000年、2011年、2016年と跳ねているところがあります。
大地震後の余震の可能性も視野に、本震・余震の扱いについてもみていく必要がありそうです。
発生月・時間については、今回は取り上げませんでした。
★特徴量VS特徴量
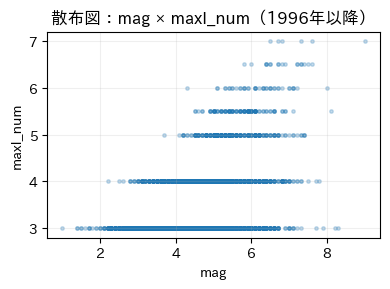
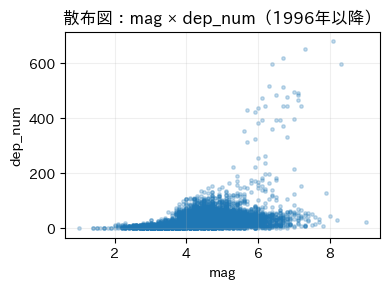
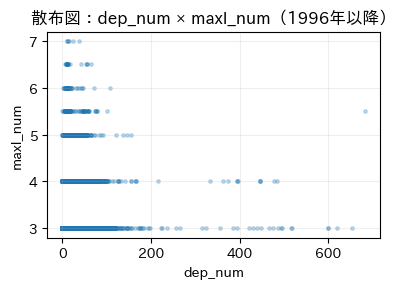
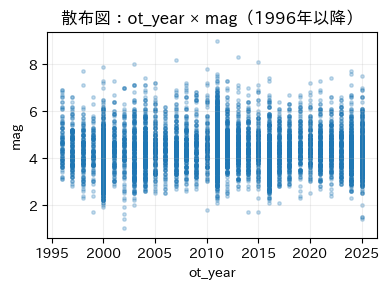
マグニチュードと震度、深さについては物理的に関連していそうだなと思っていたので、予想通りの結果となりました。
時系列としてみてみると、なんとなく波があるように読み取れ、マグニチュードと時系列という部分で可能性を感じます。
震度にすると見づらいのは、数値が整数での取得からだと思います。
終わりに
規模の大きいデータを利用してみて、より実践に近い学びとなりました。
ただ、失敗もそれなりに発生しました![]()
データの観察までに起こったことは、分析目標を決めるまでに時間がかかり、やみくもにデータを可視化してなんとか決めていこうとした結果、自身の方向性を見失う事態になり、かなり時間を消費しました。
データとグラフはあるのに、結局やりたいことに利用できるのかわからないという状態になってしまったことが、無駄に時間を使ってしまったと感じています![]()
まず目的を決め、そこに向かって手段として機械学習を利用する![]()
書籍でも学んだことでしたが、実際に感じられたことが今回の一番の学びです。
この後の流れについては、シリーズとして考察までまとめていきます。
参考
気象庁 震度データベース https://www.data.jma.go.jp/eqdb/data/shindo/
住宅構造研究所
https://www.homelabo.co.jp/select/history01_01.html