■はじめに
「IBM SPSS Modeler」はGUIの直感的な操作で、データ前処理から分析・予測までできるので、プログラミングを前提としないビジネスユーザーでも扱える点が大きな魅力です。
一方で、SPSS Modelerには標準機能ではカバーできない処理に対しては、以下の「拡張ノード」を用いてRやPythonを記述することで対応が可能となっています。
しかし、この拡張ノード自体は単一のスクリプトを貼り付ける仕組みであり、他のノードのようにユーザーが直感的にパラメータを変更することが難しいです。
そのためユーザーの動的な操作・入力が必要な処理には不向きで、非エンジニアに配布・再利用しづらいといった課題があるかと思います。
そこで本記事では、Python標準のGUIライブラリである「tkinter」を使い、SPSS Modelerの拡張ノードを「GUI付きノード」のようにしてみたいと思います。
処理の題材としては、以下記事を参考にさせていただき、「カテゴリ別のファイルの出し分け」について書いてみたいと思います。
tkinterについては以下を参考にさせていただきました。
当記事では、以前watsonxを活用して作ったWeb検索機能付きのチャットボット や 様々なLLMを統一インターフェースで扱う仕組みを活用し、AI にコード作成を手伝ってもらいながら進めています。
■ 本記事の想定
想定読者:
- SPSS Modeler を業務で利用している方
- 拡張ノードを使ったことがある、または興味がある方
- Python がある程度書けるが、作った処理を ビジネスユーザーに展開する方法に悩んでいる方
また、想定している環境は以下の通りです。
OS :Windows11
SPSS Modeler :19.0 # 18.5以上であれば同様のことができるかと思います。
python :3.10 # Modelerに同梱されているもの
Pythonライブラリ
- pandas==1.4.3
- tkinter
・本スクリプトは SPSS Modeler の「拡張のエクスポート」ノードでの実行を前提としています。単体のPython実行環境では動きません。
・動作確認は Windows 11 環境でのみ実施しています。macOS では未検証です。特に tkinter(GUIライブラリ)の挙動は OS 依存の影響を受ける場合があるため、正常に表示されない可能性があります。
■ 概要
SPSS Modelerで加工・分析したデータの、任意の列のユニークな値ごとにデータを分割、各々を別のCSVファイルとしてエクスポートする処理を実装したいと思います。
この時に以下2点をユーザーがGUIで視覚的に選べるようにしていきます。
- 分割の基準となる列の選択
- 各CSVファイルを出力するフォルダを任意に指定
以下画像を例にすると…
- SPSS Modelerで加工した顧客の購入データの中にある「支払方法」列の、値の種類(チェック、現金、カード)ごとに別のCSVファイルに出力したい。
- GUIで任意の列(この場合「支払方法」)と、出力先のフォルダを選んで処理実行。
- 選んだフォルダの直下にサブフォルダが自動で作られ、そこに値の種類(チェック、現金、カード)ごとにCSVファイルが分けてエクスポートされる。

その他、自動作成されるサブフォルダに関しては「spssmodeler_output_YYYYMMDD-HHMMSS」のようにタイムスタンプ付きの命名がされます。
また、保存するCSVファイルの名前については、各々「列名_ユニークな値」となるように自動で名付けしていくようにします。
■ 使い方
SPSS Modelerに同梱されているデモデータを実際に使いながら、利用手順を確認します。今回利用するデータは以下のパスにあります。
C:\Program Files\IBM\SPSS\Modeler\19.0\Demos\japanese_ja\BASKETS1n
1.データの読み込み と 「拡張のエクスポート」ノードの接続
まずは、SPSS Modeler側でノードのセットとデモデータを読み込みをします。
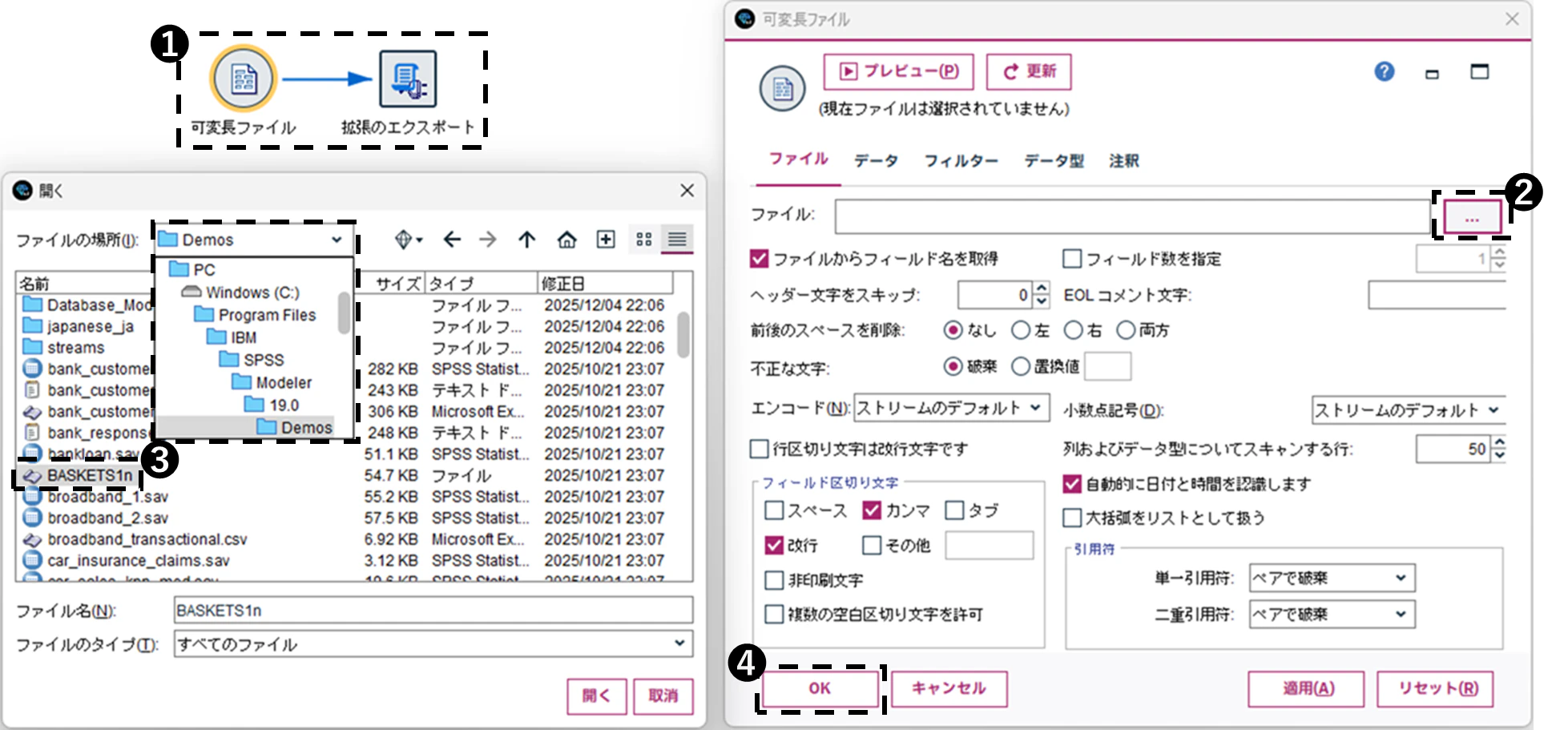
❶「可変長ファイル」ノードを配置、「拡張のエクスポート」ノードを接続。
❷「可変長ファイル」ノードを開いてファイルの参照ボタンを押す。
❸ 読み込むデータを選択。(この例では上記のパスの「BASKETS1n」)
❹ 読み取りの形式などを確認して「OK」ボタンを押す。
2.「拡張のエクスポート」ノードに以下のコードを転記・実行
次にPythonで書いたコードを「拡張のエクスポート」ノードに貼り付け、実行します。

❶「拡張のエクスポート」ノードを開き、Pythonを選択。
❷ こちらのリンクのコードを全文コピーして点線枠内に貼り付け。
❸ 適用・実行ボタンを押す。
一度コードが張り付いた状態の「拡張のエクスポート」ノードを作れば、2回目からは❸の実行を押すだけ。
3.GUIで 分割する列、出力先フォルダ を選択
SPSS Modelerからデータの読み込みが完了すると、下の画像の様なGUIが出てきます。

❶ 全列名がプレビュー表示されるので、分割の基準にしたい列を一つ選択します。この手順では「支払方法」を選択してみましょう。
※各列名の右側にはユニーク値の数(=作成するファイル数)がでます。
※ユニーク値が閾値(デフォルトでは500)を超える列は選択肢から除外されます。閾値は後述のUNIQUE_LIMITで変更できます。
❷ 参照ボタンを押すとファイルダイアログが出るので、出力先となる任意のフォルダを選択します。
❸ 「OK」で処理開始。「キャンセル」でノードの実行停止。
この例では、支払方法列の、ユニーク値(チェック、現金、カード)に対応したファイルが、選択したフォルダの直下に自動作成されたサブフォルダの配下に格納されるというわけです。
4.処理進捗/成功画面
処理開始すると以下の進捗確認画面になります。現在作成中のファイルや行数が確認できます。

作成が完了すると成功画面が表示され出力先フォルダのパスが表示されます。

❶ 「出力フォルダを開く」を押すと実行を終了するとともに、自動作成したサブフォルダを開きます。
❷ 「閉じる」を押すとそのまま実行終了できます。
5.出力の確認
出力先のフォルダを開いてみると、指定したフォルダに、サブフォルダ(以下点線枠内)がつくられ、「列名_ユニーク値.csv」で命名されたファイルがユニーク値分作成されているのが分かるかと思います。

以上で一連の利用の流れは終了です。簡単な処理ではありますが、SPSS Modelerの標準機能で同じ処理をしようとすると一つ一つ手作業でエクスポートの設定をする必要があるので面倒です。
上記手順2.のエクスポートノードまで作れば、ノードをコピペして使えまわせます。「出力」や「エクスポート」のノードが接続できるノードであれば、割とどこでもつなげて利用できる為、汎用的に使えるのでは、と思います。
■ コードの解説
さて、ここからは「拡張のエクスポート」ノードに貼り付けたコードを解説していきます。
本記事では、コードを上から順に追いながら、まずはデータ分割やファイル処理といった周辺ロジックの関数を解説し、その後にGUI部分の構造と画面遷移について説明します。
あわせて「なぜこの書き方にしているのか」という設計意図も紹介しますので、実装の背景まで含めて理解していただければと思います。
周辺処理:ファイル名チェック、欠損値の処理など
CSVを大量に自動生成する処理では、処理自体よりも「周辺の事故」で失敗することが多くあります。このツールでは、実運用で起きがちなトラブルを事前に防ぐため、いくつかの安全策を入れています。
ENCODING = "utf-8-sig" # Excel で文字化けしにくい BOM 付き UTF-8
MISSING_LABEL = "__MISSING__" # 欠損値(NA)はこのラベルにまとめて 1 ファイルにする
MAX_FILENAME_LENGTH = 200 # OS/環境差による長すぎ問題を避ける
UNIQUE_LIMIT = 500 # ユニーク値数の上限
👆まず、文字コード、欠損値の置換先の値、ファイル名の上限、等の設定をしていきます。
UNIQUE_LIMITは、ファイルの大量作成を防ぐために設けた、ユニーク値の数(=作成するファイル数)の上限です。カテゴリの様な文字列だけ選択できるようにしても良かったのですが、年齢など数値でファイル分けしたい事もあるかな?と思いこのような実装にしました。
def sanitize_filename(value) -> str:
text = "" if value is None or pd.isna(value) else str(value).strip()
text = re.sub(r'[\\/:*?"<>|\x00-\x1f\x7f]+', "-", text)
if text.startswith("."):
text = f"_{text}"
text = text[:MAX_FILENAME_LENGTH]
return text or "__EMPTY__"
👆DataFrameの値をそのままファイル名に使うと、禁止文字や制御文字が含まれていて保存に失敗することがあります。
そのため、sanitize_filename()でファイル名に使えない文字の除去・置換、前後の空白削除、先頭ドットの回避などを行い、安全に保存できるファイル名に正規化しています。また、ファイル名が長くなりすぎないように長さ制限も設けています。
def prepare_group_key(series: pd.Series) -> pd.Series:
s = series.astype("string").str.strip()
na_map = {"": pd.NA, "nan": pd.NA, "None": pd.NA, "<NA>": pd.NA}
return s.replace(na_map).fillna(MISSING_LABEL)
👆分割キーに欠損値が含まれると、欠損値の種類によって「欠損行が消えた」「ファイルが分かれすぎた」といった混乱が起きるかと思います。
そこでこのツールでは、prepare_group_key()でNaN・空文字・"nan" や "None" といった欠損表現をすべて同一のラベル__MISSING__に置き換えて欠損値を統一しています。
実データとして "nan" という文字が正しい値で入っている場合も欠損扱いになります。実運用に合わせて変更してください。
def create_timestamped_output_dir(base_dir: Path) -> Path:
out_dir = base_dir / f"spssmodeler_output_{datetime.now().strftime('%Y%m%d-%H%M%S')}"
out_dir.mkdir(parents=True, exist_ok=True)
return out_dir
👆こちらの工程でユーザーが選択した出力先フォルダの直下に、サブフォルダ(実行時刻のタイムスタンプ付き)を作ります。
def open_folder(path: Path) -> None:
p = str(path)
if os.name == "nt":
os.startfile(p)
elif sys.platform == "darwin":
subprocess.Popen(["open", p])
else:
subprocess.Popen(["xdg-open", p])
👆完了画面には、出力先フォルダを開くボタンを実装していますが、このopen_folderで処理終了後に出力フォルダがWindows・macOS・Linuxそれぞれに対応した方法で自動で開くようにしています。
Pandasによるデータ分割処理
CSV分割に関わる処理はsplit_and_export()にまとめています。Pandasで指定された列の値ごとにDataFrameを分割し、それぞれをCSVとして書き出しています。
def split_and_export(df: pd.DataFrame, column_name: str, output_dir: Path, progress_cb=None):
# 一時列を追加し、欠損値を整理
work = df.assign(_SPLIT_KEY_=prepare_group_key(df[column_name]))
prefix = sanitize_filename(column_name)
total = int(work["_SPLIT_KEY_"].nunique(dropna=False))
results = []
# 欠損値処理済の一時列でエクスポート
for i, (group_value, g) in enumerate(work.groupby("_SPLIT_KEY_", dropna=False), start=1):
path = output_dir / f"{prefix}_{sanitize_filename(group_value)}.csv"
out_df = g.drop(columns=["_SPLIT_KEY_"])
out_df.to_csv(path, index=False, encoding=ENCODING)
# 結果連絡用に(group_value, 行数, ファイルパス)を追加
results.append((str(group_value), len(out_df), path))
# GUIへの進捗通知用
if progress_cb:
progress_cb(i, total, len(out_df), path)
return results
👆周辺処理のprepare_group_key()やsanitize_filename()を使って欠損値やファイル名の安全を確保しつつ、分割してCSVに出力します。
tkinterによるGUI表示
GUI表示部分は以下の三種類の画面があります。
GUI関連の処理は基本的にApp クラスにまとめていますが、「2. 処理中の進捗表示画面」ではCSV分割処理が重いため、以下のような形で処理を分離しています。
- メインスレッド:GUI表示(tkinterはメインスレッドで動かす必要がある)
- ワーカースレッド:CSV分割処理
# ワーカースレッド(CSV分割) → メインスレッド(GUI) へ状態通知するときの種別
MSG_PROGRESS, MSG_DONE, MSG_ERROR = "progress", "done", "error"
@dataclass
class AppState:
base_dir: Path | None = None
column_name: str | None = None
@dataclass
class ProgressUI:
win: tk.Toplevel
status: tk.StringVar
bar: ttk.Progressbar
👆処理を分離している進捗表示画面用に、AppState クラスで進捗状態を保持し、ProgressUI クラスがその状態を参照して画面を更新します。
class App:
# 初期化
def __init__(self, df: pd.DataFrame):
self.df = df
self.state = AppState()
self.q = queue.Queue() # スレッド間通信用キュー
self.progress_ui: ProgressUI | None = None
self.root = tk.Tk()
self.root.title("CSV Splitter (root)")
self.style = ttk.Style(self.root) # カラー対応テーマ設定
try:
self.style.theme_use("clam")
except Exception:
pass
# 選択画面 表のヘッダーデザイン設定
self.style.configure("Treeview.Heading",
background="#E2E8F0",
foreground="#475569",
font=("", 10, "bold"))
# 進捗画面 プログレスバー色設定
self.style.configure("Green.Horizontal.TProgressbar",
background="#16A34A")
self._hide_root() # ルートを非表示化
# ルートウィンドウを見えない状態にする
def _hide_root(self):
try:
self.root.geometry("1x1+0+0") # サイズを最小化
self.root.overrideredirect(True) # 枠・タイトルバーを削除
self.root.attributes("-alpha", 0.0) # 透明化
self.root.deiconify() # 表示状態に戻す(透明のまま)
self.root.update_idletasks() # UI更新を反映
except Exception:
pass
# 指定ウィンドウを前面に表示してフォーカスを当てる
def _present(self, win: tk.Toplevel):
try:
win.update_idletasks() # UI更新を反映
win.deiconify() # 最小化解除
win.attributes("-topmost", True) # 一時的に常に最前面に設定
win.lift() # 同アプリ内で前面に表示
win.focus_force() # フォーカスを強制取得
# 300ミリ秒後に最前面固定を解除
win.after(300, lambda: win.attributes("-topmost", False))
except Exception:
pass
👆本実装では、画面遷移を明確に管理するために、ルートウィンドウ tk.Tk() は_hide_root()で透明化し、三つの画面を tk.Toplevel として生成しています。
また_present() で、作成した各Toplevelウィンドウに確実に全面表示するようにしています。
透明化の方法として .withdraw() などがあるのですが、SPSSModelerの(ネイティブPythonの)実行環境はModeler専用の特殊なもののためか、ルートウィンドウだけ非表示にすることができないです。そのため_hide_rootの様な少し回りくどい方法を取っています。
def _make_win(self, title: str, geometry: str, *,
resizable=True, on_close=None, modal=False) -> tk.Toplevel:
win = tk.Toplevel(self.root)
win.title(title)
win.geometry(geometry) # 初期サイズ指定
if not resizable:
win.resizable(False, False) # リサイズ不可
# 閉じるボタン(×)を押したときの挙動
win.protocol("WM_DELETE_WINDOW", on_close or (lambda: None))
# modal=True でこの画面以外を操作できないようにする
if modal:
try:
win.transient(self.root)
win.grab_set()
except Exception:
pass
self._present(win) # 画面を前面に出す
return win
def run(self):
self.root.after(0, self.show_selection_window) # 最初に表示する画面の予約
self.root.mainloop() # Tkinterのイベントループ開始
👆_make_win()は、アプリ内の各画面(設定・進捗・完了など)で必要になる設定を 共通化しています。
tkinterでは、画面表示 → mainloop() でイベントループを開始、となりますが画面表示の命令を直接書くと、GUIの準備が整う前のタイミングになってしまい、正しく表示されないことがあります。そこでrun()で after(0, ...) を使って、GUIの準備が完了した直後に最初の画面を表示する処理を予約してから mainloop() を開始しています。
ユーザーに列名と出力先を選ばせる画面
ここからは各画面についての実装になります。最初は選択画面(※ここの事)です。
# 対象になりうる列を抽出する内部関数
def _eligible_columns(self) -> list[tuple[str, int]]:
# UNIQUE_LIMIT 以下の列だけを対象にする
return [
(c, n) for c in self.df.columns
if (n := prepare_group_key(self.df[c]).nunique()) <= UNIQUE_LIMIT
]
👆_eligible_columns()ではUNIQUE_LIMITで設定した作成ファイル数の上限以下に絞って、選択対象の、列名、ユニーク値数、を返します。
👇画像の赤点線枠内に関する実装。 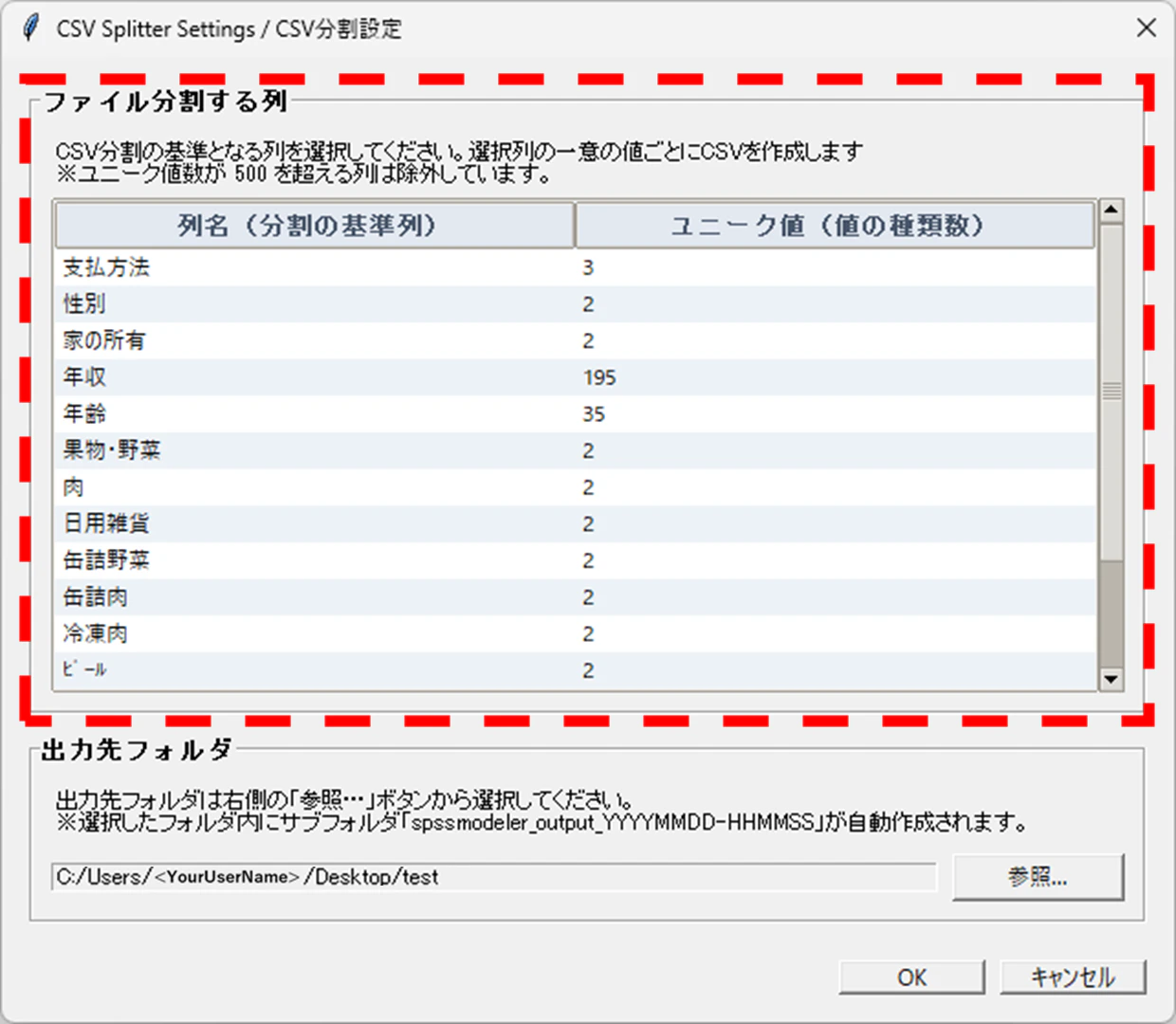
def show_selection_window(self):
# 対象列がなければエラー表示して終了
eligible = self._eligible_columns()
if not eligible:
messagebox.showerror(
"No Eligible Columns / 選択可能な列がありません",
f"ユニーク値数が {UNIQUE_LIMIT} 以下の列が見つかりませんでした。",
parent=self.root,
)
self.root.destroy()
return
# 設定ウィンドウ作成
win = self._make_win(
"CSV Splitter Settings / CSV分割設定", "640x600",
on_close=self.root.destroy, modal=True
)
# 上部:分割対象列の選択エリア
frm_col = tk.LabelFrame(win, text="ファイル分割する列",
font=("", 10, "bold"), padx=10, pady=10)
frm_col.pack(fill="both", expand=True, padx=15, pady=(15, 10))
# 説明ラベル(分割ルールの案内)
tk.Label(
frm_col,
text=(f"CSV を分割する基準となる列を選択してください。\n"
f"※ユニーク値数が {UNIQUE_LIMIT} を超える列は除外しています。"),
font=("", 9), justify="left"
).pack(pady=(0, 4), anchor="w")
# Treeview列定義(列名 + ユニーク数)
columns = ("列名 (Column)", "ユニーク値数 (Unique Count)")
# Treeview + Scrollbar 用フレーム
frame_tree = tk.Frame(frm_col)
frame_tree.pack(fill="both", expand=True)
# 縦スクロールバー
vsb = ttk.Scrollbar(frame_tree, orient="vertical")
vsb.pack(side="right", fill="y")
# Treeview作成
tree = ttk.Treeview(frame_tree,
columns=columns,
show="headings",
height=12,
yscrollcommand=vsb.set)
vsb.config(command=tree.yview)
# 行のストライプカラー設定
tree.tag_configure("oddrow", background="#EDF2F7")
tree.tag_configure("evenrow", background="#ffffff")
# ヘッダーと列設定
for col in columns:
tree.heading(col, text=col)
tree.column(col, anchor="w")
# データ挿入(交互色)
for idx, (c, n) in enumerate(eligible):
tag = "evenrow" if idx % 2 == 0 else "oddrow"
tree.insert("", "end", values=(c, n), tags=(tag,))
tree.pack(fill="both", expand=True)
tree.focus_set() # 初期フォーカス設定
👆基本的には画面に対応して上から順に書かれていると思いますが、まず、分割対象として利用できる列を取得し、条件を満たす列が1つもない場合はエラーメッセージを表示してアプリケーションを終了します。対象列が存在する場合は、「CSV分割設定」というモーダルの設定ウィンドウを作成します。
ttk.Treeview()には「列名」と「ユニーク値数」の2列を定義し、見出しと表示形式を設定します。取得した対象列のデータを1行ずつ挿入し、視認性を高めるために行ごとに背景色を交互に変えています。最後に、Treeviewへフォーカスを当てて、ユーザーがすぐ操作できる状態にしています。
👇画像の赤点線枠内に関する実装。 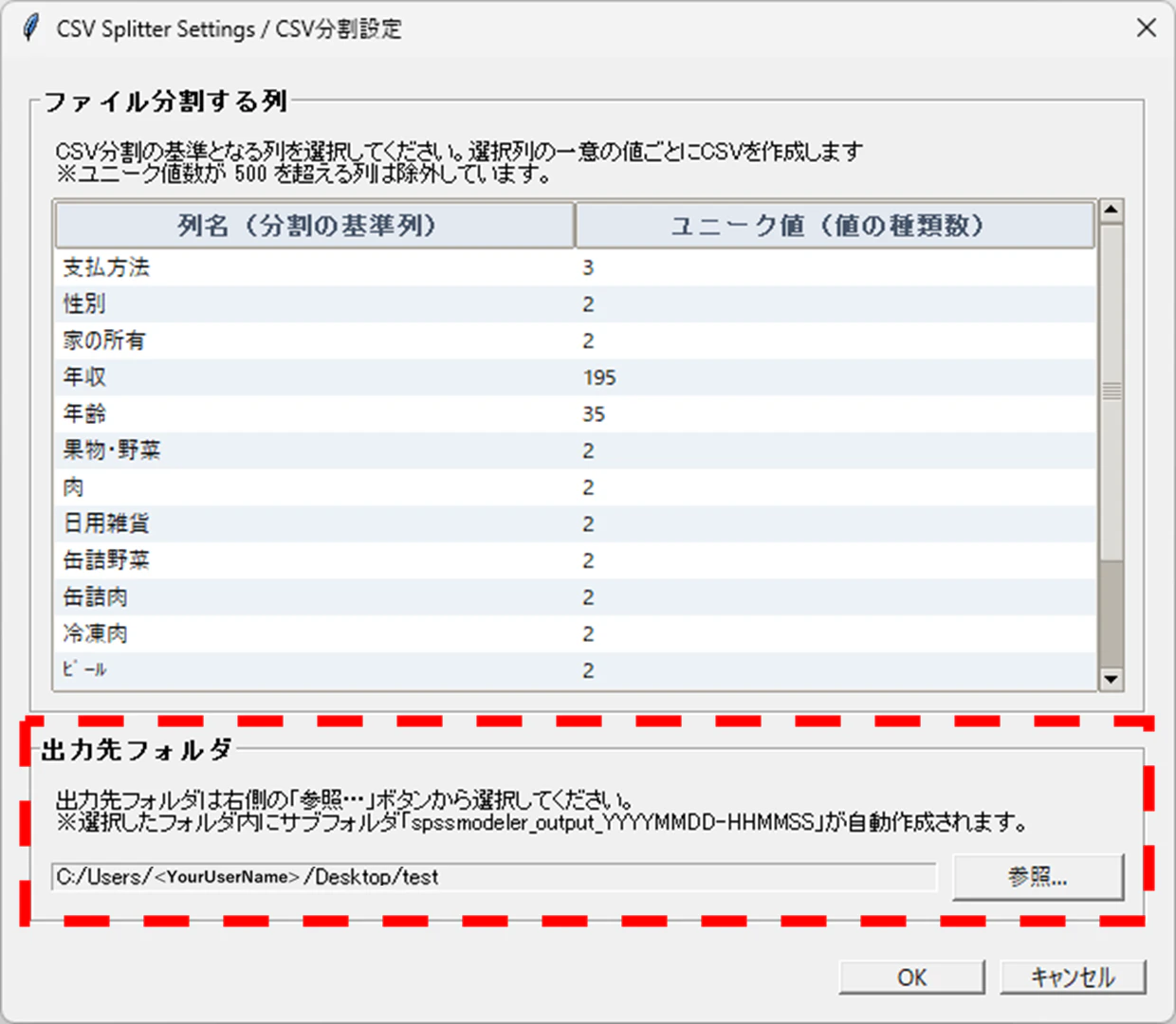
# 下部:出力先フォルダの選択エリア
frm_dir = tk.LabelFrame(win, text="出力先フォルダ", font=("", 10, "bold"), padx=10, pady=10)
frm_dir.pack(fill="x", padx=15, pady=(0, 10))
# 説明ラベル
tk.Label(
frm_dir,
text=("出力先フォルダは右側の「参照…」ボタンから選択してください。\n"
"※選択したフォルダ内にサブフォルダ「spssmodeler_output_YYYYMMDD-HHMMSS」が自動作成されます。"),
font=("", 9), wraplength=540, justify="left"
).pack(anchor="w", pady=(0, 8))
# EntryとButtonを横並びにするためのフレーム
dir_row = tk.Frame(frm_dir)
dir_row.pack(fill="x")
dir_var = tk.StringVar() # フォルダパスを保持するStringVar
# 選択フォルダ表示用(読み取り専用)
tk.Entry(dir_row, textvariable=dir_var, font=("", 9), state="readonly").pack(
side="left", fill="x", expand=True, padx=(0, 8)
)
# 「参照...」ボタン
tk.Button(
dir_row, text="参照...", width=12,
command=lambda: (selected := filedialog.askdirectory(title="出力先フォルダを選択", parent=win))
and dir_var.set(selected)
).pack(side="left")
👆出力先フォルダの指定部分では、StringVar を使ってGUIと内部状態を同期させています。
参照ボタンからフォルダを選択すると dir_var.set() が呼ばれ、それに紐づいた Entry ウィジェットが自動的に更新されます。これにより、ウィジェットの値を直接操作させないような形になっています。
👇「OK」「キャンセル」ボタン
# OK / キャンセル ボタンエリア
frm_btn = tk.Frame(win)
frm_btn.pack(fill="x", padx=15, pady=(10, 15))
# OKボタン押下時の処理
def ok():
sel = tree.focus()
# 列未選択チェック
if not sel:
messagebox.showwarning(
"No Selection / 列未選択", "分割する列を選択してください。", parent=win
)
return
# フォルダ未選択チェック
if not dir_var.get().strip():
messagebox.showwarning(
"No Directory / フォルダ未選択", "「参照...」ボタンから出力先フォルダを選択してください。", parent=win
)
return
# 選択値をAppStateに保存
self.state.base_dir = Path(dir_var.get().strip())
self.state.column_name = tree.item(sel)["values"][0]
# 画面を閉じて後続処理に
win.destroy()
self.start_processing()
# キャンセルボタン(ルートウィンドウも閉じてアプリ終了)
tk.Button(
frm_btn, text="キャンセル", width=10, command=lambda: (win.destroy(), self.root.destroy())
).pack(side="right", padx=(8, 0))
tk.Button(
frm_btn, text="OK", width=10, command=ok
).pack(side="right")
👆ok()は、まずフォルダパスとListboxの選択状態を確認し、エラーや未選択があれば、messageboxで表示をします。正常に処理完了した場合、AppState(フォルダパス, 列名)を後続の処理進捗画面や成功画面に渡します。
処理中の進捗表示画面
以下は、先ほどの画面の後続として、処理の進捗を表示する以下の画面(※ここの事)の実装になります。

def start_processing(self):
# 分割対象となるユニークキー数を取得
total_files = int(prepare_group_key(self.df[self.state.column_name]).nunique())
# 進捗表示用のウィンドウを作成
win = self._make_win("処理中 / Processing", "416x180", resizable=False, on_close=lambda: None)
tk.Label(
win, text="CSV を作成しています。しばらくお待ちください…", font=("", 11, "bold")
).pack(anchor="w", padx=16, pady=(16, 8))
status = tk.StringVar(value="準備中…")
# 進捗状況表示ラベル
tk.Label(
win, textvariable=status, font=("", 10), wraplength=384, justify="left"
).pack(anchor="w", padx=16, pady=(0, 10))
# 進捗バー maximumは作成予定ファイル数
bar = ttk.Progressbar(win, mode="determinate", maximum=max(total_files, 1))
bar.pack(fill="x", padx=16, pady=(0, 12))
# 補足説明
tk.Label(
win, text="※データ量が多い場合は数分かかることがあります。", font=("", 9)
).pack(anchor="w", padx=16)
self.progress_ui = ProgressUI(win, status, bar)
# CSV分割処理は別(ワーカースレッド)で実行
threading.Thread(target=self._worker_split, daemon=True).start()
self.root.after(100, self.poll_queue) # queue監視開始
👆進捗画面&非同期処理の実装。ProgressUI に画面表示情報をまとめて保持し、ワーカースレッドの状況確認ようにキュー監視を開始します。
def _worker_split(self):
try:
# 出力フォルダをタイムスタンプ付きで生成
output_dir = create_timestamped_output_dir(self.state.base_dir)
# CSV分割 + エクスポート処理
results = split_and_export(
self.df,
self.state.column_name,
output_dir,
lambda i, t, r, p: self.q.put(
(MSG_PROGRESS, i, t, r, str(p))
)
)
# 正常終了メッセージをqueueへ
self.q.put((MSG_DONE, output_dir, len(results)))
except Exception:
# エラー内容をqueueへ送信
self.q.put((MSG_ERROR, traceback.format_exc()))
👆CSV分割とエクスポート処理。進捗はコールバックを通じて queue に投げ、メインスレッド(GUI)側が安全に表示更新できるようにしています。
def poll_queue(self):
try:
# queueにメッセージがある限り処理
while True:
kind, *rest = self.q.get_nowait()
# 進捗更新
if kind == MSG_PROGRESS and self.progress_ui:
i, total, rows, _ = rest
# プログレスバー更新
self.progress_ui.bar["maximum"] = max(total, 1)
self.progress_ui.bar["value"] = i
# ステータステキスト更新
self.progress_ui.status.set(
f"作成中: {i}/{total}\n行数: {rows} 行"
)
# 正常終了
elif kind == MSG_DONE:
self._close_progress()
self.show_success_dialog(*rest)
return
# エラー発生
elif kind == MSG_ERROR:
self._close_progress()
messagebox.showerror("エラー", rest[0], parent=self.root)
self.root.destroy()
return
except queue.Empty:
pass
# 100ms後に再チェック
self.root.after(100, self.poll_queue)
# 進捗ウィンドウを安全に閉じる
def _close_progress(self):
if self.progress_ui:
try:
self.progress_ui.win.destroy()
except Exception:
pass
self.progress_ui = None
👆キュー監視とUI更新。workerから届くメッセージ(進捗・完了・エラー)をキューから取り出し、UIを更新するします。
キューを枯れるまで読み、MSG_PROGRESS ならプログレスバーとステータス文を更新します。MSG_DONE を受け取ったら進捗ウィンドウを閉じて成功ダイアログを出し、MSG_ERROR なら進捗画面を閉じた上でエラー表示してアプリを終了します。キューが空なら何もしないで、after(100, ...) で一定間隔で再チェックします。
完了画面
以下は、処理が完了した後の以下の画面(※ここの事)の実装になります。

def show_success_dialog(self, output_dir: Path, file_count: int):
# 完了用のモーダルウィンドウを生成
win = self._make_win("完了", "416x180", on_close=self.root.destroy, modal=True)
tk.Label(win, text="CSV の作成が完了しました。", font=("", 14, "bold")).pack(
anchor="w", padx=16, pady=(16, 6)
)
tk.Label(win, text=f"作成ファイル数: {file_count}", font=("", 11)).pack(
anchor="w", padx=16, pady=(0, 10)
)
# 出力先フォルダのラベル(見出し)
tk.Label(win, text="出力先フォルダ:", font=("", 10, "bold")).pack(anchor="w", padx=16)
# 出力パスを表示するためのStringVar
path_var = tk.StringVar(value=str(output_dir))
# 読み取り専用のEntryとしてパスを表示
tk.Entry(win, textvariable=path_var, font=("", 9), state="readonly").pack(
fill="x", padx=16, pady=(4, 14)
)
btns = tk.Frame(win)
btns.pack(fill="x", padx=16)
# ウィンドウとアプリ全体を閉じる処理
close_all = lambda: (win.destroy(), self.root.destroy())
# フォルダを開いた後にアプリを終了
open_and_close = lambda: (open_folder(output_dir), close_all())
# 「出力フォルダを開く」ボタン&「閉じる」ボタン
tk.Button(btns, text="出力フォルダを開く", width=22, command=open_and_close).pack(side="left")
tk.Button(btns, text="閉じる", width=12, command=close_all).pack(side="right")
👆処理完了後の画面では、すぐに確認ができるように出力先のフォルダに飛べるボタンを配置しています。
データ読み取り と GUI起動
def main():
df = modelerpy.readPandasDataframe()
if df is None or df.empty:
print("DataFrame が取得できない、または空です。")
return
App(df).run()
if __name__ == "__main__":
main()
👆SPSSModelerからのデータの読み取りは、Modeler側のAPIとして用意されているmodelerpyモジュールの readPandasDataframe()を使用します。
コードの解説は以上です。
■ 感想
実は、この様なPythonなどのスクリプトをGUIに落とし込む機能は、以下で紹介されている通りSPSS Modelerの標準機能として搭載されています。
それでも今回あえて記事にした理由は、「生成AI × 拡張ノード × tkinter」の組み合わせが非常に相性が良いと感じたからです。
SPSS ModelerはGUIベースで直感的に操作できるため、ビジネスユーザーにとって非常に扱いやすいツールです。しかし使い込むうちに、「もう少しこういう機能が欲しい」と感じる場面は少なくありません。その補完手段として拡張ノードがありますが、PythonやRでの実装、そしてコードをそのまま扱うことは、非エンジニアにとってはハードルが高いのも事実です。
一方で、近年の生成AIの進化は著しく、特にPythonのようなメジャー言語であれば、ある程度のコードは短時間で形になります。そこで、生成AIを活用して実装しつつ、標準ライブラリであるtkinterでGUI化すれば、より多くの人が使える形にできるのではないかと考えました。
もちろん、使い勝手や配布の観点ではカスタムノードの方が適している場面もあります。ただ実際に作ってみて感じたのは、開発のしやすさや自由度の高さという点では、tkinterも十分選択肢になり得るということです。
より洗練されたGUIを作るためにサードパーティ製ライブラリを使うことも可能ですが、uvの様な優秀なパッケージ管理ツールが使えず、ライブラリの導入や管理が面倒なので、今回はtkinterを採用しました。
他にも「生成AI & 拡張ノード & tkinter」でやってみたい事があるので、出来次第記事にしていこうと思います。興味が向いた人はぜひ試してみてください。
■ 参考
- tkinter関連
- pandas1.4.xのreference
- SPSS関連