必要な前提知識
- Cassandra のアーキテクチャ
- Prestoの簡単な動作の流れ
目的
- Cassandraの新テーブルを作成するにあたって、PrestoのSQL的に効率良いテーブルとは何か? を探る。
以下に今回作成したテーブル毎のprestoの挙動をまとめる。
test.test (keyspace.table)
※(p= Partition Key, c=Clustering Key)
p=0,1 に10万件ずつデータを書き込み, c=0~10万
p=2~10万 に1件ずつデータを書き込み, c=0
テーブル全体にSQL
SELECT * FROM cassandra.test."test"

- taskが綺麗に分解され(✔️マークがその数)処理が走っている。
特定の1つのPartitionにSQL
SELECT * FROM cassandra.test."test" WHERE p=0
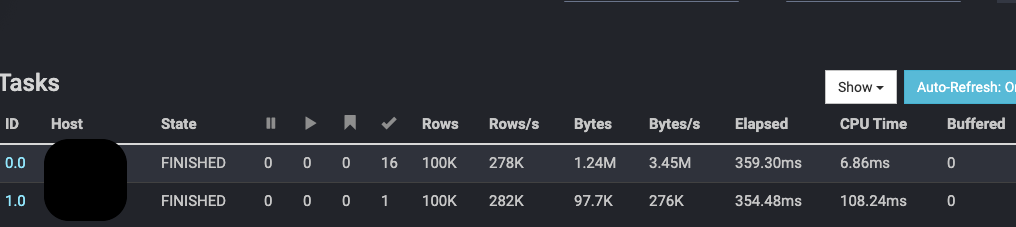
- Partitionを1つに特定すると、Prestoのtaskは分解されない。
-> 一つのサーバー(worker)のみが動く。
特定の1つのPartitionで、ClusteringKey を選択。
SELECT * FROM cassandra.test.test WHERE p=0 AND t=120

- このPartition には10万件あるが、1行しか読まれていない。(効率良い。)
特定の1つのPartitionで、ClusteringKey を選択。(ver2)
SELECT * FROM cassandra.test."test" WHERE p=0 AND t>0 AND t<100

- このPartition には10万件あるが、(><)でClusteringKey を選択してもそれしか読まない(効率良い!)
Partitionを範囲選択してSQL
SELECT * FROM cassandra.test."test" WHERE p>10 AND p<100
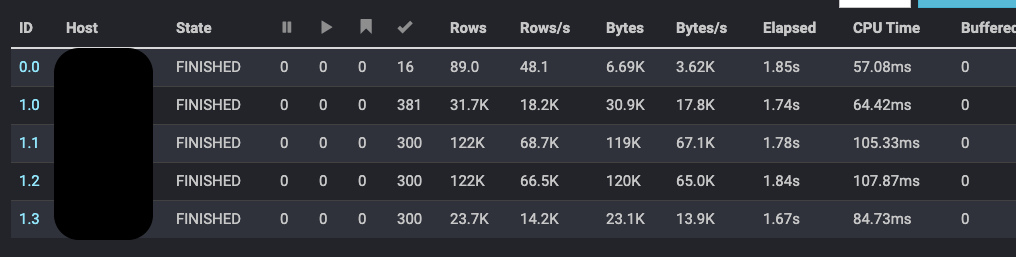
- P=10~100 はデータが一件しかないPartition
- 一つ上のSQL と比べると、ある程度は1つのPartitionにデータをまとめるとSQL効率が良い。
→公式では1Partitionに10万件程度のitemを推奨。(itemとはrowではなく各値。)
結論
-
Cassnadra のテーブル設計のトレードオフ。
Partition にデータをある程度溜める <---> 適度に分散させる。
→1Partitionに10万件のitemを溜める程度、それ以上は分散した方が良い。 -
ClusteringKey にはSQLでよく範囲選択に使う値を設定するのが良い。
(例:timestamp)
所感
- やっぱり早い。
- Cassandra & Prestoでなんでもできる気がしてきた...
- Cassandra は超柔軟で、カラム追加等も簡単にできるが、最初のテーブル設計は肝
(PrimaryKey の変更はできないので。)