
はい、その通りです。30秒もかからずに10,000ドルが消えました。
非効率なクエリでも、高いコンピュート使用量でもありません。ほとんどのエンジニアが存在すら知らない完全に不合理な課金モデルによるものです。
BigQueryを使っているなら、知らないうちに多額の資金を失っている可能性があります。
セットアップ: 単純なクエリ —— あるいはそう思っていたもの
先月、顧客のデータパイプライン構築を支援していました。複雑なものではなく —— 大規模な公開テーブルからの基本的なデータサンプリング作業です。データセットのサイズを考慮し、予防策を講じました:
- 結果を10万行に制限する
LIMITステートメントを使用 - クエリは瞬時に実行 —— 異常はなさそう
- クエリを3回実行
詳細なクエリ:
EXPORT DATA
OPTIONS (
uri = 'gs://xxxxx/*.json',
format = 'JSON',
overwrite = true)
AS (
SELECT *
FROM `bigquery-public-data.crypto_solana_xxxxx.Instructions`
LIMIT 1000000
);
このクエリはBigQueryの公開データセットにある**crypto_solanaデータセットのInstructionsテーブルから1,000,000行**をJSON形式でGoogle Cloud Storageバケットにエクスポートします。
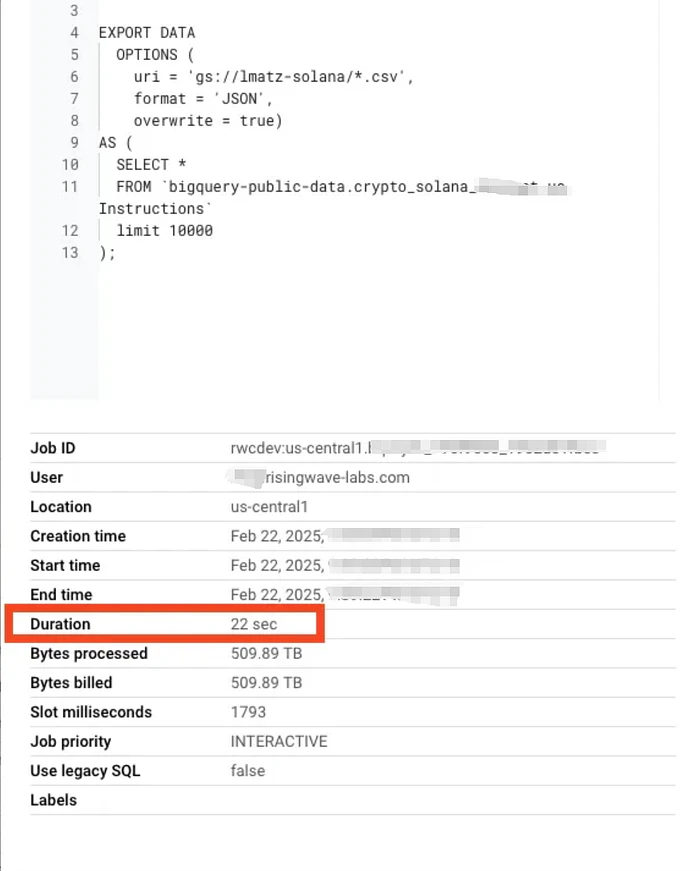
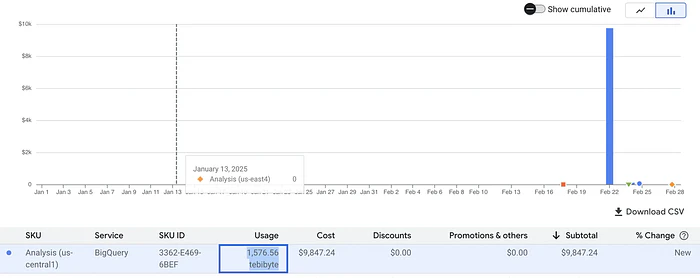
届いた請求書: 3つのクエリで9,847.24ドル?!
🔥🔥BigQueryが私たちに請求した金額はほぼ10,000ドル🔥🔥
🔥🔥3つのクエリで1,576.56TBのデータが「スキャン」された🔥🔥
これがどうして可能なのか?!
コストの内訳はさらに不可解でした:
- 合計「スキャン」データ量: 3クエリで1,576.56TB
-
LIMITを使用したにもかかわらず、各クエリで509.89TBのスキャンデータが課金 - 22秒間でクエリ実行 —— つまり1秒あたり23TBのスキャンレート
私たちは完全に言葉を失いました。
発見: BigQueryの隠された課金モデル
BigQueryは最も先進的なクラウドデータウェアハウスの1つです。業界最高レベルのクエリ最適化技術を有しています。limitクエリで100K行を返すために実際に509TBのデータをスキャンするはずがありません。
では何が起きていたのか?
Googleの知人に相談した後、罠を発見しました:
BigQueryは処理データ量ではなく、参照データ量で課金します!!!
もう一度読み直してください。
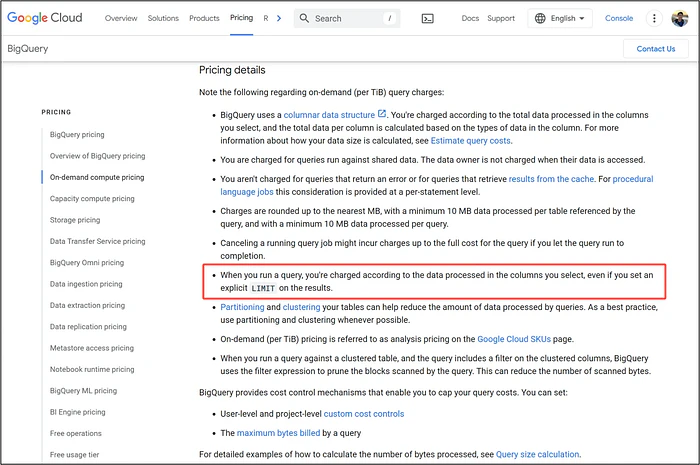
GCPが意図的に設計したと考えられる課金モデルの図解 —— 理不尽であっても!
クエリが1PBのテーブルに触れた場合、数MBしか返さなくても、BigQueryは1PB全体をスキャンしたかのように課金します。
これは他のクラウドデータウェアハウスとは完全に異なる動作です。
他のデータウェアハウスでの動作
BigQueryの課金モデルの異常さを理解するために、Redshift、Snowflake、DatabricksでのLIMITの動作を比較しましょう。
AWS Redshift、Snowflake、Databricksなどの現代的なクラウドデータウェアハウスはカラムナーストレージと述語プッシュダウンを活用します:
- カラムナーストレージ: 関連する列のみを読み取り、スキャンデータを最小化
-
述語プッシュダウン: フィルタリング条件(
LIMIT、WHERE)を可能な限り早い段階で適用 - パーティション刈り込み: テーブルがパーティション分割されている場合(例: 日付別)、関連パーティションのみをスキャン
例えばRedshift、Snowflake、Databricksで以下を実行:
SELECT * FROM huge_table LIMIT 100;
- システムは100行を取得して停止し、コンピュートコストを削減
- 必要なデータのみスキャンされ、コストは実際の使用量を反映
BigQueryはこれとは完全に異なるアプローチ:
- 総参照データ量に基づき課金
- LIMITは課金データ量を削減しない —— 大規模テーブルに触れるクエリはテーブル全体の課金対象
- パーティション刈り込みは予測不能 —— クエリがフルテーブルサイズのスキャン課金を発生させる可能性
例えばこのクエリ:
SELECT * FROM huge_table LIMIT 100;
- 100行のみ返却されても、テーブル全体をスキャンしたと課金
- テーブルが1PBの場合、1PBのデータスキャンとして課金
- フィルタリングも無効 —— テーブルを参照すれば支払義務発生
エンジニアにとっての悪夢
BigQueryのクエリ最適化は期待通りに機能しません。他の主要クラウドデータウェアハウスとは異なり、LIMITなどの伝統的なテクニックが必ずしもコスト削減につながらないのです。ミリ秒単位で実行されるクエリでも法外な請求が発生する可能性があります。
これは常識に反しています —— 他の主要クラウドベンダーはすべて実際に処理されたデータ量で課金しますが、BigQueryではクエリが触れた完全なデータセットに基づき課金されます。これによりエンジニアは直感的でない方法でコスト計算を再考することを強要されます。
結果? あっという間にクラウドクレジットを使い果たします。多くのチームがGCPの無料クレジットが数ヶ月持つと想定するものの、単一の不良クエリが一夜にしてクレジットを枯渇させる現実に直面します。
クラウド課金: 明白な場所に潜む罠
BigQueryは氷山の一角に過ぎません。クラウドプロバイダーは「低コスト」の課金モデルでユーザーを誘引した後、隠れた費用を導入するのが常套手段です。
- ストレージは安価、コンピュートは高額
- 広告コストはTBあたりのスキャン費用だが、「スキャン」の定義が一般的な理解と異なる
- クラウドベンダーはエンジニアが細則を読まないことに依存
これが企業が予期しないクラウド請求を経験する理由 —— 課金モデルは誤解を招くように設計されています。
最終考察
BigQueryを使用している場合は直ちに請求レポートを確認してください。クラウド課金の罠を回避するには以下を検討:
- Redshift、Snowflake、Databricksなどのコスト効率に優れた代替手段の調査
- Icebergなどのオープンフォーマットを使用したベンダーロックインの防止
- クエリスケールアップ前のコストシミュレーション実行
これは単発のミスではありません。BigQueryの課金モデルにおける根本的な欠陥です。
大規模データワークロードを実行する場合、自分がどのように課金されているかを正確に理解する必要があります —— クラウドの課金が常に期待通りではないからです。