
年末オープンジオかくし芸大会 でおなじみの、FOSS4GAdventカレンダー2018の23日目です。
はじめに
この記事は
- 地図や位置のデータをPythonで処理したい
- Python初学者
- QGISちょっとわかる
- PostGISやMySQLなどのサーバー系はちょっとしんどい
- 商用GISソフトは手元にない
- 暗中模索話だいすき
という方むけの検証記事です。どうぞよろしくおねがいいたします。
きっかけ
いろいろとアレで大量のcsvファイルをなだめたりすかしたりクリーニングしたりするために、PythonのライブラリであるPandasをよく使っています。Pandasについては多くの知見があるため割愛しますが、表形式のデータを取り扱うのに様々な命令があるため、結構便利ですし、今後もいろいろ使ってみたいなあと考えています。
※こちらのパンダさん![]() とはちょっと関係がないかもしれませんが、どこかでなにかつながりがあるかもしれませんね。
とはちょっと関係がないかもしれませんが、どこかでなにかつながりがあるかもしれませんね。
さてPandasから地図(位置)のデータもさっくり処理できちゃうと、わたくしとしては業務的に便利かもしれないと思い調べてみたら、GeoPandasというライブラリがありました。一応、FOSS4Gの一員でもあるようです。
(not integrated toolsってきになりますがまあいいか)
※2018年のGeopython conferenceでもGeoPandasのワークショップが開かれるなど、すごくマイナーなわけではなさそうです
http://2018.geopython.net/#w4
ねらい
GeoPandasの導入や視覚化などについては、id:sanvarieさんによる情報や、QiitaのGeoPandasタグあたりをご参考にしてみてください。
他のエントリでは、視覚化やデータ変換などについて紹介がありますが、わたしとしては
- pythonで空間結合がさっくりできちゃうと、なんかうれしい
- (あわよくば)100万行(レコード)とかもさくっと処理できるかしら
というゴールで試してみます。
空間結合とは、大まかに言うとお店などのポイントデータに対して、メッシュや街区などのポリゴンデータから、属性を取ってくる処理です。串刺し処理ともいいますね(意外と引用可能な模式図とかないので、例のチラシ裏の落書きですみません)
みんな大好きQGISでももちろんこのような処理は可能なのですが、対象レコードが万オーダーくらいになると、全然処理が終わらなかったり、ソフトそのものが落ちたりします。
また、空間処理をpythonのみで回せると、設計的な縛りにうまくとりこめたりするかもしれません。
ほかにも、明日までにAフォルダ内にあるポリゴン1000ファイルに対し、Bフォルダファイルのポイント1000ファイルについてすべての組み合わせで空間結合やんなきゃ…という場合とかは、このGeoPandasを活用すればできるとおもいます。
GeoPandasをためしてみる
今回の実行環境スペックは
- ProductName: Mac OS X
- ProductVersion: 10.13.6
- BuildVersion: 17G65
- Python 3.6.7
- GeoPandas 0.3.0
- QGIS 3.4.2
です。
あと、わたしのスペックは
- QGISよく使う
- PythonもPandasも理解はざっくり
- 好きな食べ物はじねんじょ
ぐらいのヒヨコですので、いいサジェスチョンがあればとても嬉しいです。
まず、こちらのサイトを参考にAnacondaに入れてみました。
なお、Anaconda上ではEnvironmentsタブでインストールされているかチェックをしたほうがよいです。
データ準備
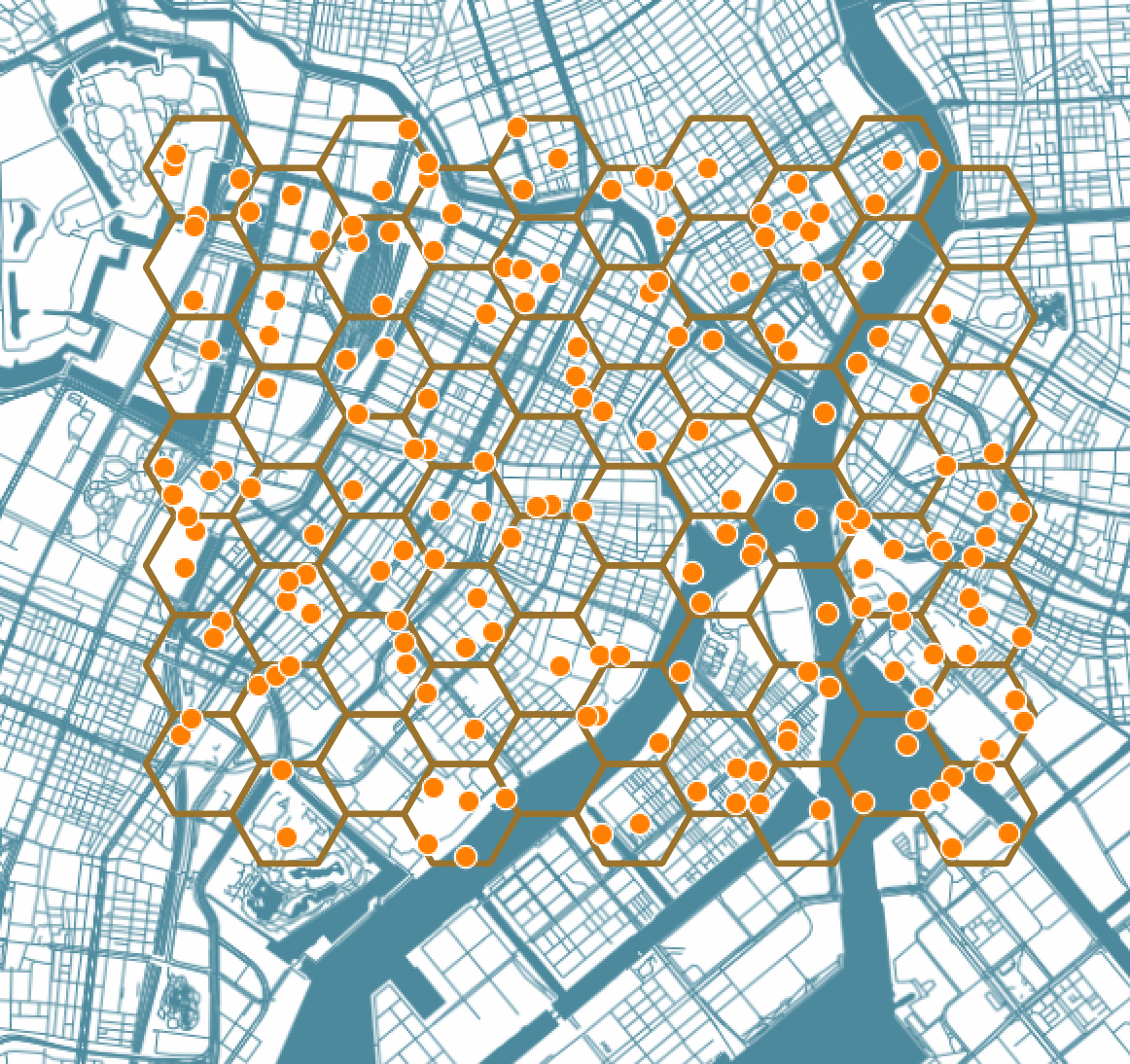
まずは軽めのデータということで、QGISのベクタメニューから調査ツール→グリッド作成を使って、六角形グリッド60個(3857_hex500_n60)とランダムポイント180個(3857_point_n180)をGeoJSON形式で作成します。
※GeoPandasはSHPもダイレクトで読み込んでくれるんですが、ええまあ最近はこんな流れもあったりしますので、GeoJSONでやってみましょう…)
※対応フォーマットはこの辺に情報があります
http://geopandas.org/io.html
※あと六角形ポリゴンなんて大戦略ヲタ以外では普通あんま使わないとおもうのですが、生まれて初めて作りました。
hogehogeというフォルダに保存したこれらのGeoJSONをGeoPandasで表示・確認する場合は
import geopandas as gpd
# GeoJSON読み込み
pt = "/hogehoge/3857_point_n180.geojson"
hx = "/hogehoge/3857_hex500_n60.geojson"
df_pt = gpd.read_file(pt) #ランダムポイント
df_hx = gpd.read_file(hx) #HEXポリゴン
# GeoJSON描画
base = df_hx.plot(color='white', edgecolor='black')
df_pt.plot(ax=base, marker='o', color='red', markersize=5)
としてAnaconda上のJupyter notebookで
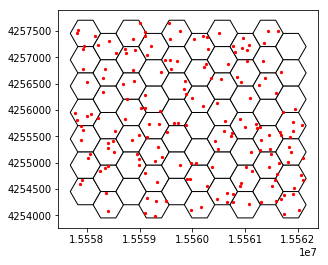
このような可視化ができます、QGISと同じ分布で出ていますね。背景もなんかすれば出るのかもしれませんがまあいいや。
いざ空間結合
では、空間結合をやってみましょう。GeoPandasでは
geopandas.sjoinを用いて処理することができます。
この処理はGeoPandasでは
spj = geopandas.sjoin(df_pt, df_hx, op='within')
の一行で済みます。
これの意味は 左から読むと
- spjというジオな箱(データフレーム)に結果を出力して頂戴
- geopandas.sjoinという機能で空間結合してね
- 刺すデータはdf_pt というポイントデータ
- 刺されるdf_hx というポリゴンデータ
- なお、含まれる(within)という条件で空間結合ですよ
となります。
geopandasという名称は長いのでgpdと省略させて最初からコードをまとめると
import geopandas as gpd
# GeoJSON読み込み
pt = "/hogehoge/3857_point_n180.geojson"
hx = "/hogehoge/3857_hex500_n60.geojson"
df_pt = gpd.read_file(pt) #ランダムポイント
df_hx = gpd.read_file(hx) #HEXポリゴン
# 空間結合
spj = gpd.sjoin(df_pt, df_hx, op='within')
# 先頭5行を確認
print(spj.head())
# GeoJSONで書き出し
output = "/hogehoge/rslt.geojson"
spj.to_file(output, driver="GeoJSON")
これを実行してみると、結果のデータフレーム出力では、ポイントデータにポリゴンデータの属性が結合されています

また、出力されたGeoJSONをQGISで確認すると、空間結合を行った結果カラム(列)が追加されています。接尾語が長々とつくのはまあご愛嬌ということで。
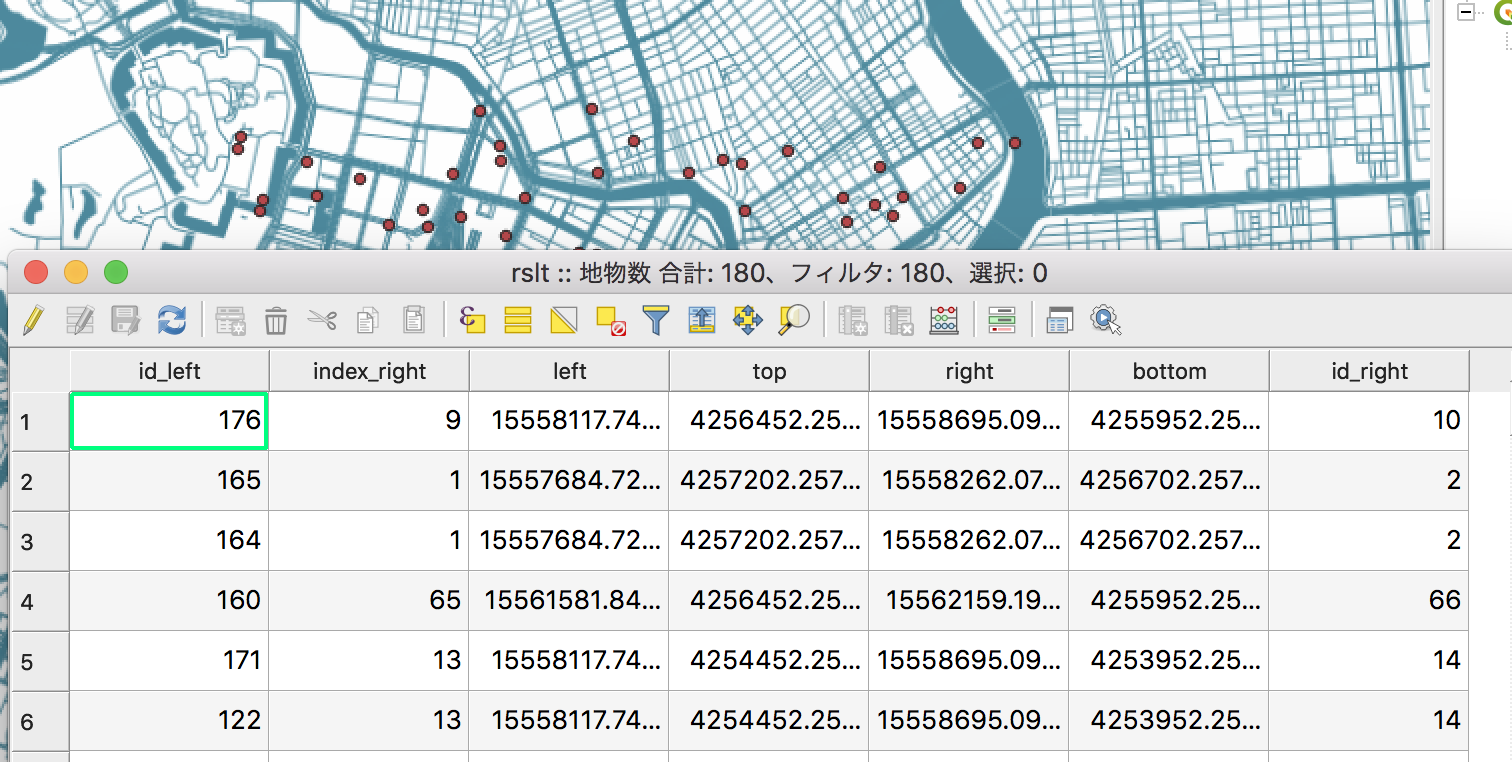
これでGeoPandasで空間結合ができましたね
処理速いの?
それな。
夢の100万行処理にあたって速度は気にしたいので、timeモジュールを用いて、計測してみました。
出力も省略した測定用コードをこんな感じにしてみました。
import time
import geopandas as gpd
# 開始時間取得
t1 = time.time()
# GeoJSON読み込み
pt = "/hogehoge/3857_point_n180.geojson"
hx = "/hogehoge/3857_hex500_n60.geojson"
df_pt = gpd.read_file(pt) #ランダムポイント
df_hx = gpd.read_file(hx) #HEXポリゴン
# 空間結合
spj = gpd.sjoin(df_pt, df_hx, op='within')
# GeoJSONで書き出し
output = "/hogehoge/rslt.geojson"
spj.to_file(output, driver="GeoJSON")
# 処理後の時刻
t2 = time.time()
# 経過時間を表示
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")
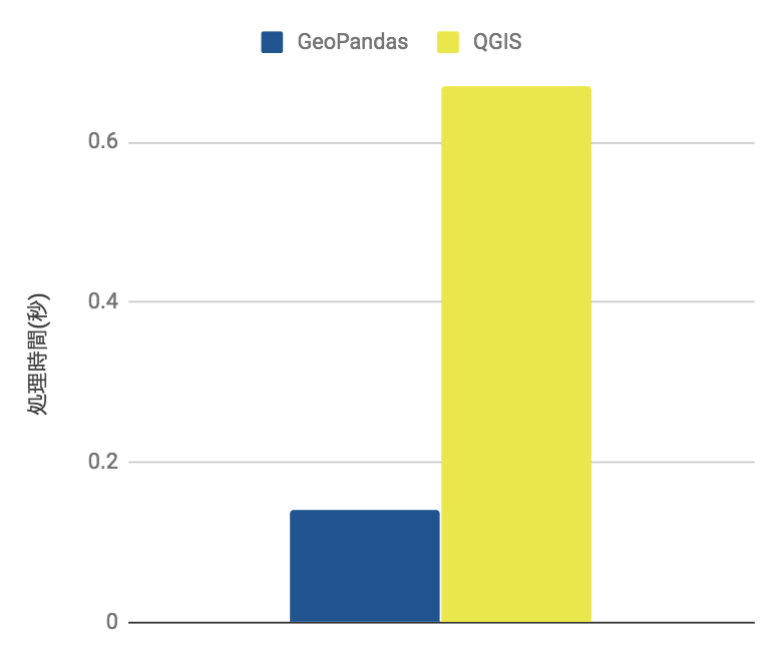
ということで結果は
0.14秒
でした。比較対象として同じデータをQGISの「場所で属性を結合」で行うと
0.67秒
だったので約80%の高速化がはかられています。
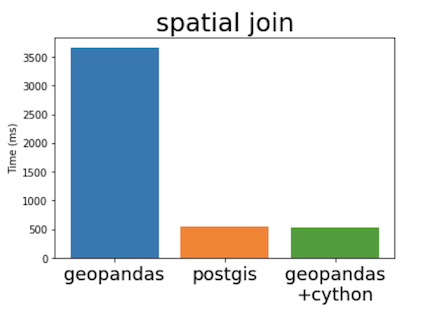
では、同様に6万個のポリゴンと10万行のポイントで空間結合をやってみると
GeoPandasでは
56.80秒
となりました
しかし、QGISですと夜通し14時間経っても2%しか進まない状態となりました…
(いろいろ調整したら動くかもしれませんが)このペースで行くと約29日(700時間)ほどかかることになりますので、OHPとバイトさんで確認したほうが早いやんけ!」と憤る上司が現れてもおかしくない状況となります。
…おそらく29日かかる推定なので比較するべきではないと思いますが、参考までにグラフ化すると

となります。
もっと速くならんのか
ということで、GeoPandasはQGISより早いとはいえ、10万行で56秒なら、夢の100万行だと概算10分以上はかかることなります。まあ待てなくもないのですが、もうすこしなんとかしたいところ。
もともとPythonは速くない言語ですので、ママチャリに新幹線なみの速度を求めるのは酷ですが、ちょっと調べてみました。
たとえば Pickle(酢漬け) というモジュールによってデータ形式を変換して高速化をはかる手法がデータマイニング界隈などであります。今回の位置データをPickle化して試してみましたが、Pickle化を行うところでボトルネックが起きてしまうのか、6万個のポリゴンと10万行のポイントの空間結合で
59.70秒
と、ノーマルの56.80秒より遅くなっています。

あと考えられることとしては、マルチプロッセンシングによる並列処理化を行うDaskなども使うという手もあるかもしれませんが、ためしていません。でも結局データ読み込み書き込みはそれなりにかかるので、ちょっと厳しいかなという予想をしています。
結局そういうことなのね
さらにいろいろ調べていたところ、10月にあったFOSS4G Belgium 2018でGeoPandasの発表があったようです。御仁がおっしゃるにはCython使うとPostGIS並みに速くなるよ!ということで、そうか、Cythonによるブーストか…という元も子もないオチに打ちひしがれました。
(ミニ四駆にガソリンエンジン載せるような感覚かな、と)
なお、GeoPandas+Cythonに関する補足情報はここにもあります。
まだまだ試すべき課題や壁が発見されてしまいましたが、今回使ったGeoJSONデータはここにおいています。ここまでお読みくださった方は、わたしの屍をコヤシにさらなるpython縛りのハイスピードシンプル空間データ処理をいっしょに考えてくださると嬉しいです。
※なお、QGISでドチャクソ遅い属性結合もGeoPandasではGISファイル直読みで属性結合できるので、そのうちためしてみたいですね。
以前はSHP→csv→Pandas→計算→属性結合でそこそこ手間がかかっていたので、これはありがたいかも。
まとめ
今回の検証まとめとして
GeoPandasは…
- GISファイルが直読みできる
- QGISよりも早く空間結合処理ができる
- Python上でさまざまな処理に組み込める
- 100万行処理はなんとかできるけどもっと速度チューニングができるはず
ということがわかりました ![]()
この記事のライセンス

この記事はCC BY 4.0(クリエイティブ・コモンズ 表示 4.0 国際 ライセンス)の元で公開します、どうぞどうぞ。