0.はじめに
この記事はFujitsu Advent Calender 2025 20日目の記事です
今年もAdvent Calenderの季節がやってまいりました。私としては今年一年はとある検証環境でひたすら格闘していました。大人の事情で(お察しください)あまり多くは語れないのですが、ただひたすら苦しかった一年となりました。
今年はプライベートでも色々忙しいため、今回はCXLの動向について簡単に振り返るのみとさせてください。
お断り(お約束)
本記事の内容は私個人の見解であり、所属する組織として意見を代表したり保証したりするものではありません。
内容については誤りを含む可能性もありますのでご注意ください。(誤りについてご指摘していただけると助かります。)
1. CXL 4.0仕様が公開
まず今年の最初の話題ですが、2025年11月に、CXLの4.0の仕様が公開されました。私もまだ内容を理解できているわけではないのですが、White paperによると、PCIe 7.0の仕様をもとに、以下の3つの特徴が挙げられています。
1. Increased Bandwidth and Connectivity
レイテンシーはそのままで、帯域は3.0に比べて2倍の128GTsになるようです。CXL2.0と比べると4倍ということになります。PCIe7.0bベースになるためというのが大きい気もしますが、そのほかにもこの資料によると、いくつかの工夫があるようです。
2. Bundled Ports
さらに、いくつかのポートを束ねてもっと帯域を増やすという機能が追加されました。図のように、一つ以上の標準ポートと、任意の数のStreamlinedポート1を束ねて、1つのデバイスに割り当てることができるようです。
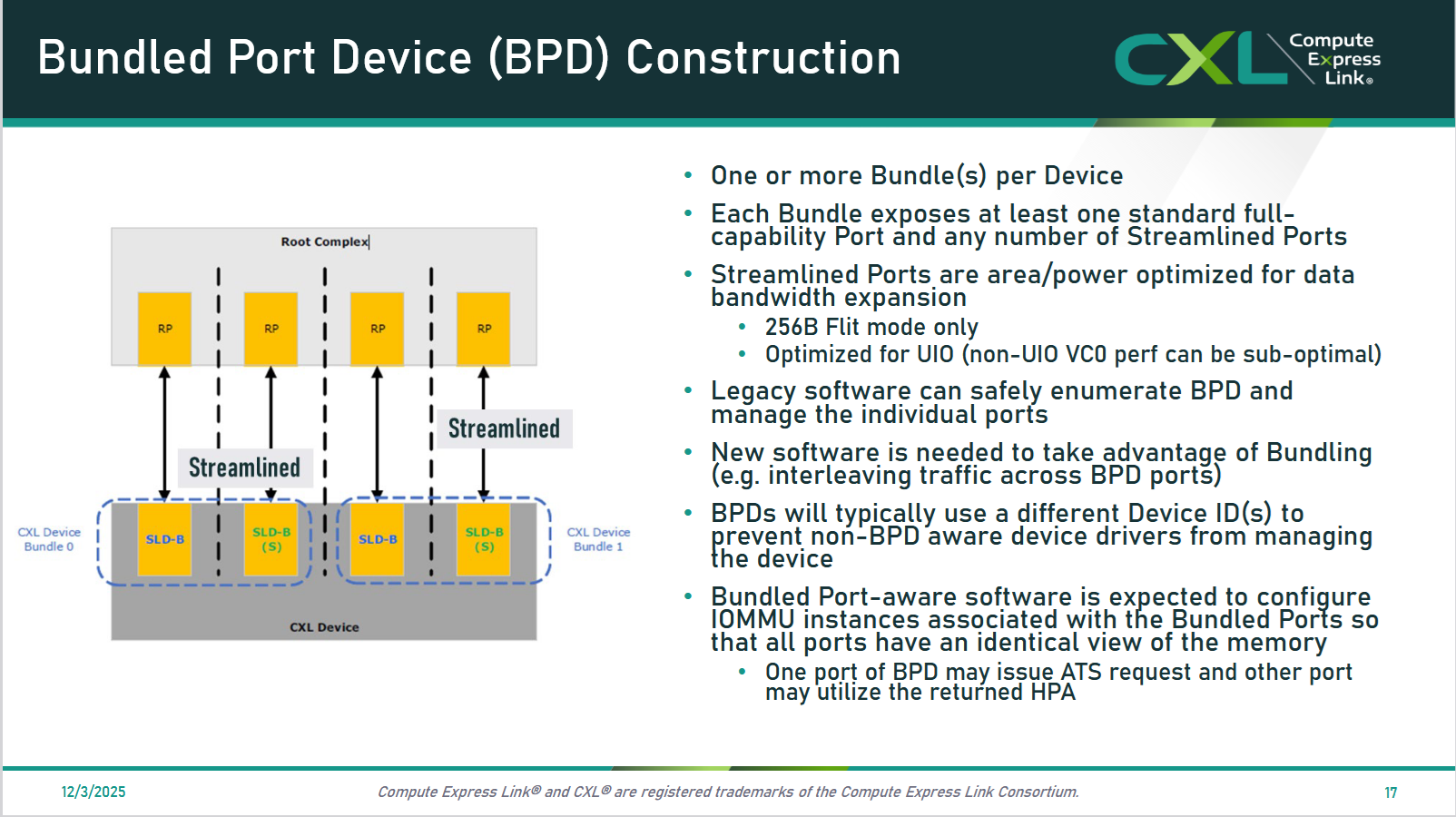
3. Memory Maintenance Enhancements
メモリのスクラブ機能 について、機能強化が図られています。CPU(OSサイドから)あるいは、デバイスサイドからメモリのメンテナンス操作を行うための機能が追加されていて、次回のブート時にメンテナンスを行うといった動作も可能になるようです。
2. AIでのユースケース
また、この発表と同時にCXLによるサーバー間共有メモリのユースケースとして、大規模言語モデル(LLM)のKV cacheを置く場所として使うという用途が見つかっており、スパコンのカンファレンスであるSC25の中で、Xconn社によるデモが行われるというアナウンスもありました。
そこには以下のような解説がされています。
現代のAIワークロード、特にKVキャッシュを多用するLLM推論では80~120GBを超えるメモリを消費するため、複数のGPGPUを使う場合にはデータ移動コストの増加につながっている。
マルチGPGPUの推論システムでは、データは以下のような非効率なパスを通過する必要がある。
GPU → DRAM → NIC → ストレージサーバー → NIC → DRAM → GPU
この長大なパスをCXL共有メモリに置き換えることで、性能向上を実現できるというものです。
現在のIT技術のトレンドとしてAIに対する対応は無くてはならないものとなっていますが、そこでの有力なユースケースがわかってきたことはCXL界隈にとっては良いニュースです。昨今のメモリ高騰によってどう状況が変化するのかは筆者にも予想ができませんが、明るい未来があることを願っています。
3. Type 2 デバイスへの対応に向けたLinuxの動向
さて、LinuxのCXLの開発状況ですが、自分の感触ではここ1年ぐらいで大きく変化したように思います。LinuxのCXL開発コミュニティにおいて、昨年まではCXLによる メモリ拡張の機能対応 が中心だったのに対して、今年はCXLの Smartデバイスの対応の実装 が本格的に始まっており、またそのデバイス内のメモリの扱いについての議論が中心になってきているからです。
ここで、CXLのデバイスのタイプについて昔作った資料を引用しておさらいします。
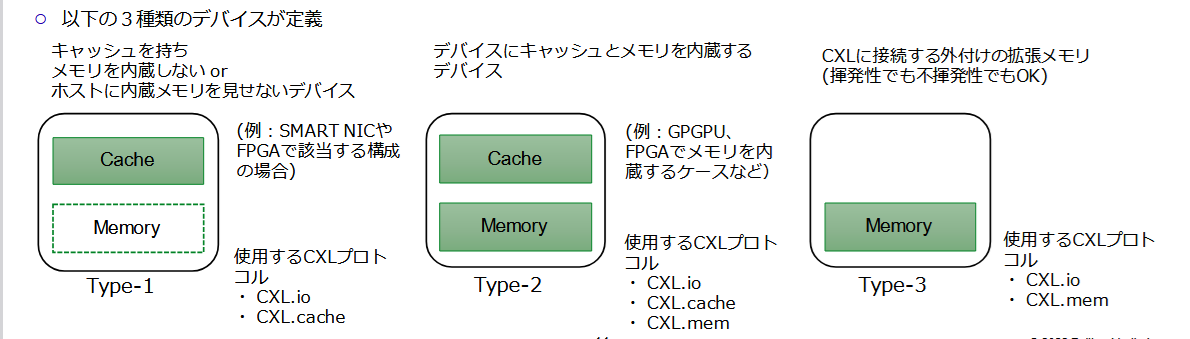
この図のように拡張メモリとしてのCXLはType3に分類されるのですが、デバイス側にキャッシュとメモリを内蔵し、それをデバイス側でもコントロールするのがType 2デバイスです。2024年のLinux Plumbers Conferenceの発表では、このタイプのデバイスの例としてNetwork Deviceが挙げられています。
今まではType 3の拡張メモリの実装が議論・実装・修正の中心だったように感じていた2のですが、Type 2デバイスの基本実装の開発がここ1年ぐらいでコミュニティでもかなり進んできたように感じています。
実際、この記事を書いている段階で v22のパッチ が投稿されていて、実装とレビューがかなり進んでいることがうかがえます。
Type2のデバイスがType3のデバイスと大きく異なる点は、 デバイス内のメモリの使い方が異なる ことです。
Type3の拡張メモリはあくまでもメモリでしかないので、そのデバイスの認識・初期化が終わったCXLデバイスのメモリ領域は、あとはLinuxのメモリ管理機構にすべてをゆだね、普通のプロセスなどにメモリを割り当てることができます。
しかし、Type 2デバイスの場合、そのデバイス内のメモリはCPUからもアクセスできるとはいえ、普通のプロセスに割り当てるためのメモリ領域ではありません。そのデバイスとCPU・メモリ間の通信が主目的ですから、そのデバイスのドライバや、あるいはデバイスに関連する特殊なプログラムがこの領域にアクセスすることになります。
これまでType 3デバイスのメモリ拡張ではユーザプロセスが利用できる&速度の違いも表現できるCPU LessのNUMA Nodeとして見せることにしていましたが、Type 2デバイスではそれではうまくいかないことがわかってきています。
そこで、そういう領域をどうやって管理したらよいか?という議論などが、今年のLinux Plumbers Conference行われていました。
中でも印象に残ったのは Kernel Memory Management MCでGregory Price さんに提案された、「Type2デバイスのメモリを明に指定できるように、専用の指定フラグを追加しよう」というものです。
memopolicyにはN_SPMというオプションを追加し、kernelレイヤーでは必要であればGFP_SPMというフラグも追加することで、必要なプロセスが必要な時だけType2 デバイス内のメモリを利用できるようにするアイデアです。
Device DAXでType2デバイスのメモリを見せるという方法もあるといえばあるのですが、ユーザープロセス側でその中身をすべて管理しないといけませんし、やはり既存のメモリAPIが使えて、その中身をkernelが管理してくれるほうが便利なので、この方法のほうが良いのではないかということです。
確かに、プログラマーの負担が減るという意味では、この方が良いと感じました。
また、Plumbersカンファレンスでは特にDevice and Specific purpose memory MCにおいて、他にも様々な議題が取り上げられました。
Type2デバイスに関しては、Cacheの操作もデバイス側でできるようになるため、そのための初期化処理が必要なのですが、それをどうするのかいった話題も取りあげられています。
Plumbersカンファレンスではそれ以外にも様々な話題が取り上げられているので、ぜひ資料をチェックしてみてください。また、そのうちLinux Foundationから、議論の様子を撮影した動画も公開されることでしょう。
4. まとめ
今年はやや分量が少なめですが、特にType2 デバイスの動向などについて簡単にまとめてみました。それではよいお年を。