1章:はじめに
記事の趣旨
世の中では、「デジタルトラスフォーメーション(DX)」、「データドリブン経営」、「AI活用」などのビックワードが飛び交い、競合他社のちょっと盛り目のプレス記事などを目にした会社の偉い人から、うちも取り組めと言われて困っている情報システム部(情シ)の方が多くおられます。そのような方々にコンサルとして、表題のような話をすることがあるので、その内容を簡単にまとめました。もちろん、最初からお金をかけて、ベンダーに発注したり、データサイエンティストを雇う方法もありますが、情シの方がある程度データサイエンスを腹落ちさせて、ためにしやってみて、その後の外部に委託するなどの方向性を決めるほうが個人的にはお勧めです。
基本的には平易に書いているつもりですが、わからない単語や用語は都度調べながら読んで頂ければと思います。
対象とするケース
今回の記事の対象は、全くデータサイエンスやっていないような組織が対象です。(既に自分たちもしくは外部発注してモデルを作成したり、DataRobotのようなAuto MLツールを活用している組織は除きます。)いろいろ勧められて、BIツールを導入して可視化までは出来ている、もしくは買ってやってみたけど上手く出来てないくらいのレベル感の組織をイメージして下さい。
また、対象とするようなデータは、構造化データとします。(文書や写真のような非構造化データは対象としません。)
なんちゃっての活動に意味あるの?
と思った方もおられるでしょう。私の感覚では、どの企業様も、綺麗ではないにしろそこそこデータは蓄積されています。データサイエンスのためにはデータの収集が肝なのですが、幸いにも情シの方は自社のシステムデータの扱いは専門分野でであり、上手くできることが多いです。データさえそろえば、何かしらの価値あるユースケースを設定でき結果が得られる場合が多いです。また、結果は駄目でも、データサイエンスへの理解が深まるという価値もあります。
日本企業のデータ活用の現在地
他の会社はどうなの?と思われた方も多いでしょう。
私の主なお客様は、製造・流通が多いのですが、肌感としては、3000億以上のお客様は流石に着手されています。1000億〜3000億は会社に寄りけり、それ以下だと手が回っていないことが多いと思います。業界としては、流通系のほうが浸透しており、製造は遅れをとっている印象があります。また、全体として、すごく力を入れている企業とまったくやっていない企業の温度差が激しいです。

まずはやってみることが大切!
2章:必要な知識
まずは必要な知識を身につけることが必要です。
必要な知識は、「データサイエンスの概要とユースケース」、「ドメイン知識」、「IT知識」、「統計知識」の4つに大別して説明します。
データサイエンスの概要とユースケース
まずは全体感の把握が必要です。なんとなくAIを使って解決します!では話になりません。まずは何が出来るかを理解することが必要です。できることは多岐に渡るのですが、「わかりやすさ(取っつきやすさ)」と「有用性」を考えると、「分類」と「回帰」の概要とユースケースの把握が必要です。ネット等でこのあたりの知識とユースケースをキャッチアップしましょう。また、時系列で変化するようなデータの分析は、難易度が上がるので後回しでも良いでしょう。
ドメン知識
いわゆるテーマとするお題やその業界特有の業務知識の部分です。この点については、自社の話なので、特に勉強は必要ないと思います。(もちろん、後々に深い分析のために現場へのヒアリング等は必要になると思いますが。)
IT知識
「ハード系」と「ソフト系」に大別します。「ハード系」は、環境を準備する知識です。自分のPCにローカル環境を構築しても良いですし、クラウド上にサーバを立てるのもありですし、SaaSのサービス上で実行するのもありだと思います。(こちらについても一般的な情シの方はキャッチアップ不要かと思います。)
「ソフト系」では、基本はPythonとなります。(お好みでRでも良いです。)また、データの収集加工にSQLの知識は必要になります。実行方法は、Jupter Notebookにてソースコードを書くが基本ですが、最近では、UI上でビジブルに実施するソフト(Sagemaker StudioやWatson Stuioなど)なども無料や安価で使えますので、コードにアレルギーのある方はそちらでも良いと思います。
具体的には「Python実践データ分析100本ノック」の前半と「PythonではじめるKaggleスタートブック」などを読んで、例題をときながらイメージをつけてゆくのが良いと思います。
大量データを扱うと分散処理などの知識も必要になるのですが、まずは数万から数十万くらいの小さなレベルのデータからはじめましょう。
統計知識
こちらが一番ハードルが高く、かつここから入ると挫折します。現在はAuto MLが一般化され、「Amazon SageMaker Autopilot」や「IBM Watson Studio Auto AI」など統計の知識無でデータサイエンスをやってみる方法がありますので、今回はその活用を前提します。無料枠があるのでまずはQiitaの記事等を参考に動かしてみましょう。上記の本やAutoMLの実施中に、わからない言葉しらべならがら知識を増やすことが良いと思います。
まとめ
まずは自社のケースを考える前に、上記の知識となんとなく腹落ちするまで、お勉強しましょう。
30時間くらいあれば大丈夫だと思います。

キャリアアップにもつながるので頑張ってお勉強!
実践
知識も身についているはずなので次は実践です。データサイエンスの一般的な作業ステップは下記になります。
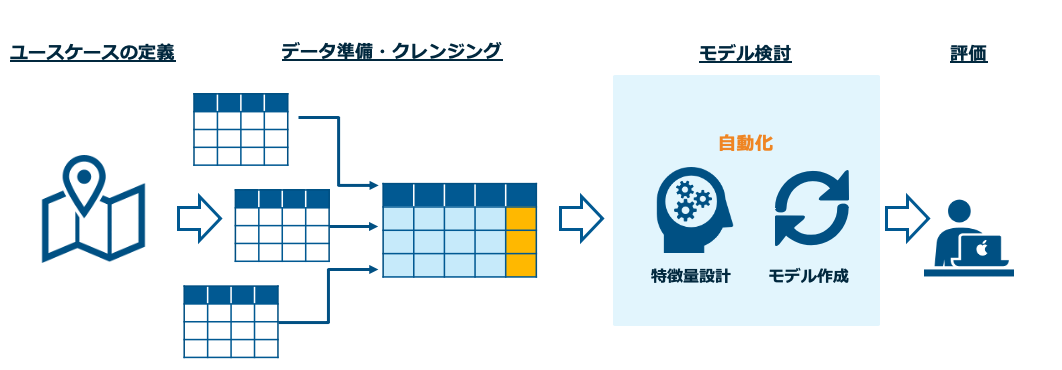
ユースケース定義
まずは、自社のデータに何があるかをざっと書き出して眺めてみます。そして、世間のユースケースの検索や社内の業務部門と話している中で聞いたことのある課題などを思い出してみましょう。そのなかで、これ可能かもというユースケースの仮説を作ります。ここで詰まるとお手上げなのですが、なにかあるはずです。頑張って考えてみて下さい。
データ準備、クレンジング
データ準備は、基本的にはいいろいろなところからデータをかき集めて、1つのテーブルを作るイメージです。2章の勉強を進めて頂ければわかるとおもうのですが、予測したいもの(目的変数)と、その変数に決定に関わっていそうなもの(説明変数)を準備します。
例として、ECサイト促進のEメールをコスト効率よく送ることをお題とするとします。その際の母体となるデータはメールの送信履歴です。目的変数は「1ヶ月以内にECサイトでの購買をしたかどうかのフラグや購買回数」になります。説明変数としては、送信対象者の年齢、性別、過去の累計購買金額などなど有ると思うので、それを想像し、集められるものを集めます。
ユースケースの設定さえできれば、こちらの作業のハードルはそこまで高くないと思います。
モデル作成
ここが最もハードルの高い箇所になります。通常ならば、特徴量設計、モデル選定・アンサンブル、ハイパーパラメータチューニングなど専門的な知識が必要となります。ただし、今回ではAuto MLを前提としますので、データを放り込んで待つだけとなります。
!基本はクラウドサービスですので、個人情報や機密情報はサニタイズしてから放り込みましょう!
上記の例にとると、ここでは送信対象の者の属性から、買ってくれるか否かの予測を実施するモデルを作成することになります。
評価
ここは少し統計の知識が必要です。Auto MLが返してくれる結果を専門用語を検索しながら理解しましょう。実際によさげな結果だったなら、実データを使い未来の予測を行ってみます。良い感じにまとまったら、上司の方や業務部門に共有してみましょう。ネイティブなことを言う人は少なく、これがデータサイエンスを根付かせる第一歩になると思います。

まとめ
すこし抽象的な内容になってしまいましたが、なんとなくやることのイメージはつかめたかと思います。これからはITが企業の運命を握る時代であり、情シの位置づけも変わってきています。その一方で、システム保守部隊から脱却できず、社会の流れとのGAPをもつ組織もたくさんみております。(コンサルとしての課題感でもあります。)この記事を読んで、一人でも行動を起こしてくれる人がいると幸いです。わからない事があれば、質問への回答も実施します。
最後に
自身の機械学習系のコード知識の整理ために、Qiitaの投稿をはじめましたが、今回はDXコンサルトして話してる事をまとめてみました。評判が良ければ今後も書いていこうと思うので、ためになったなと思ったらLGTMやフォローをお願いします。次はユースケース検討をもう少し深掘りしようと思います。私のまとめ記事は↓
Pythonで機械学習を実施する際の必要な知識まとめ