概要
HSP(Hot Soup Processor)は手軽に使えるスクリプト言語ですが、「処理速度が遅い」などの致命的な欠陥があります。
とはいえ、ちょっとしたGUIツールを作る際には手軽で便利なせいか、この2016年でも未だに生き残っています。
一方、画像処理には通常、C言語などの高速な言語が使われることが多いです。一見相矛盾する存在ですが、なまじ**HSPではOpenCVが使える**ため、HSPだけでも案外回せてしまうのです。
そこで今回の記事では、HSPで画像処理をしたい人向けのtips集を書いてみました。
※当記事はHot Soup Processor Advent Calendar 2016の10日目です
※文中、時間計測には自作PCのWindows 10(64bit)+Core i7-4790K(定格)を使用しました
目次
- 画像処理命令を概観する
- VRAMを直接操作してみる
- 画像間のPSNRを取得してみる
- 画像のハッシュを取得してみる
- 画像拡大/縮小アルゴリズムの質について
- 画像をフーリエ変換してみる
画像処理命令を概観する
そもそもHSPでは、「ウィンドウID」によって番号付けられた「画面」が存在します。
各画面には、ウィンドウとして表示されるもの(screen・bgscr命令で作成)と表示されないもの(buffer命令で作成)が存在します。以下の説明では便宜上、前者を「実画面」、後者を「仮想画面」、両者を合わせて「標準画面」と称します。
ヘルプファイルには「screenで初期化されたウィンドウIDをbuffer命令で再初期化することはできません」とありますが、試したところbuffer命令で初期化したウィンドウIDもscreen命令で使いまわせませんのでご注意ください。つまり、ウィンドウIDは、実画面同士と、仮想画面同士との間でのみ使いませます。
そして初期化した画面に対しては、lineやcircleやboxfなどの描画命令で絵を描くことができます。絵を描く対象となるウィンドウIDは描画先、描く際の起点となる座標をカレントポジションと呼びます。この2つはどちらも(暗黙の)グローバル変数ですので、意識してないと忘れがちですから注意が必要です。
実画面に描画する際、redraw命令を使うと「一通り描き終わってから表示を更新する」ことができます。これを行わないと、1操作毎に画面に結果が反映されるので処理が遅くなります。ちなみに、「gsel命令などで非表示にした実画面」と「仮想画面」に対してはredraw命令を使う必要はありません。
画像処理で最もよく使うのはgcopy命令でしょう。要するに画像を切り貼りする命令ですが、gmode命令によって「透明色付きコピー」や「ピクセルアルファブレンドコピー」などを行わせることができます。切り貼りと同時に画像を伸縮させたい場合はgzoom命令を使いますが、こちらはgmode命令による細かな制御ができないといった問題があります。
上記(基本命令)だけでも色々できますが、HSPには標準で強力な画像処理ライブラリが複数付属しています。
まずArtlet2D。GDI+の機能を利用していますので、アルファ値付きの画像を正常に扱うことができる(標準画面は24bitRGB)上、「ブラシ」を別途定義することで、幅を持った線やグラデーション入りの線などを簡単に表現することができます。また、Artlet2D用に作った仮想イメージは標準画面に書き出したり、逆に読み込んだりすることが可能です。
次にHSPCV。HSPでOpenCVの機能の一部を使うことができるプラグインですが、一部とはいえその威力はなかなかのもの。「様々なアルゴリズムで拡大縮小・回転・ぼかし・二値化・パターンマッチング」「顔認識」「Webカメラなどの画像を取得・保存」などの機能を使うことができます。こちらにも独自のバッファ構造(CVバッファ)が存在しますが、標準画面と読み書き可能です。
以下、HSPで特殊な画像処理をする際のtipsを書いてみますが、速度面の問題から、先にこれらのライブラリで実行できないかをよく勘案しましょう。場合によっては、HSPでこねくり回さず、画像全体のデータをC言語などで作成したDLLに投げた方が早いこともありますので……。
VRAMを直接操作してみる
標準画面の色を取得/色を書き込みするには、基本的にはpget/pset命令を使います。
ただ、大量に取得する場合など、それだけだと処理が遅く感じる場合はよくあります。
そこでよく使われるのが、標準画面の「中身」とも言えるVRAMデータを直接叩く手法です。
VRAMデータはタダのバイナリ列ですので、そこをpeek/poke命令で読み書きできます。
ただし、VRAMデータは直感に反し、「BGRBGRBGR...」の順で書き込まれます。
また、書き込み方向も「左下→右下→左上→右上」といった風になります。
(※WindowsのBMPデータも左下スタートなので、24bitBMPならそのままmemcpy命令等でコピペできる)
なお、VRAMを書き換えた結果を実画面に反映(表示)する際は、redraw命令を挟む必要があります。
VRAM操作でpget/psetを代替するとこんな感じ↓。
# module vram
#deffunc pgetv int vx_, int vy_
// 1行毎に横幅が4の倍数バイトになるよう調整されているので注意
// 例えばginfo_winx=98なら、vwidth=296バイトが横幅のバイト数である
vwidth = ((ginfo_winx * 3) + 3) & 0xfffffffc
// 上から下ではなく、下から上にデータが入っているので注意
vpos = ((ginfo_winy - 1 - vy_) * vwidth) + (vx_ * 3)
// データはBGRの順で入っている。66はVRAMデータを示す定数だが、
// なぜ定数定義が標準で存在しないのか理解に苦しむ
mref vram, 66
vr = peek(vram, vpos + 2)
vg = peek(vram, vpos + 1)
vb = peek(vram, vpos)
color vr, vg, vb
return
#deffunc psetv int vx_, int vy_
vwidth = ((ginfo_winx * 3) + 3) & 0xfffffffc
vpos = ((ginfo_winy - 1 - vy_) * vwidth) + (vx_ * 3)
mref vram, 66
poke vram, vpos + 2, ginfo_r
poke vram, vpos + 1, ginfo_g
poke vram, vpos, ginfo_b
return
# global
ちなみにベンチすると、次のような結果になりました。
(表中の※は、画面サイズが変わらないと変化しない変数vwidthを事前計算した場合)
| 手法 | 時間[ms] | 速度比(標準命令を1とする) |
|---|---|---|
| 標準命令-pget | 4443 | 1 |
| VRAM-pget | 3756 | 1.18 |
| VRAM-pget(※) | 3302 | 1.35 |
| 標準命令-pset | 1219 | 1 |
| VRAM-pset | 2321 | 0.52 |
| VRAM-pset(※) | 1941 | 0.63 |
# uselib "winmm.dll"
# cfunc global timeGetTime "timeGetTime"
# func global timeBeginPeriod "timeBeginPeriod" int
# func global timeEndPeriod "timeEndPeriod" int
# module vram
// 中略
# global
loop_max = 100:x_size = 200:y_size = 200:buffer 1, 640, 480
timeBeginPeriod 1
// 空ループの速度を計測
start_time = timeGetTime()
for k, 0, loop_max:for y, 0, x_size:for x, 0, y_size
next:next:next
diff_time0 = timeGetTime() - start_time
// 標準命令-pget
start_time = timeGetTime()
for k, 0, loop_max:for y, 0, x_size:for x, 0, y_size
pget x, y
next:next:next
diff_time1 = timeGetTime() - start_time - diff_time0
// VRAM-pget
start_time = timeGetTime()
for k, 0, loop_max:for y, 0, x_size:for x, 0, y_size
pgetv x, y
next:next:next
diff_time2 = timeGetTime() - start_time - diff_time0
// 標準命令-pset
start_time = timeGetTime()
for k, 0, loop_max:for y, 0, x_size:for x, 0, y_size
pset x, y
next:next:next
diff_time3 = timeGetTime() - start_time - diff_time0
// VRAM-pset
start_time = timeGetTime()
for k, 0, loop_max:for y, 0, x_size:for x, 0, y_size
psetv x, y
next:next:next
diff_time4 = timeGetTime() - start_time - diff_time0
timeEndPeriod 1
gsel 0
mes diff_time1:mes diff_time2:mes diff_time3:mes diff_time4
画像間のPSNRを取得してみる
普通に考えれば、VRAMを直接叩いて数値を読み出し、ゴリゴリ演算するのが最速なはずです。
腹立たしいことに、HSPではfor文よりrepeat文の方が1.88倍ほど速いのでそちらを使って測ってみると、次のような結果になりました(単位は[ms])。
| 画像サイズ | peekで読む部分 | 差の二乗を計算して足す部分 | 合計 |
|---|---|---|---|
| 640x480 | 160 | 60 | 220 |
| 1920x1080 | 400 | 140 | 540 |
# include "hspmath.as"
# uselib "winmm.dll"
# cfunc global timeGetTime "timeGetTime"
# func global timeBeginPeriod "timeBeginPeriod" int
# func global timeEndPeriod "timeEndPeriod" int
// 通常
buffer 1 :picload "a.png"
buffer 2 :picload "b.png"
timeBeginPeriod 1 :start_time = timeGetTime()
px = ginfo_winx :py = ginfo_winy
vwidth = ((px * 3) + 3) & 0xfffffffc
gsel 1:mref vram1, 66
gsel 2:mref vram2, 66
sum_r = 0.0 :sum_g = 0.0 :sum_b = 0.0
repeat py
// 比較する座標の順番はPSNRに関係しない
vpos_b = cnt * vwidth
vpos_g = vpos_b + 1
vpos_r = vpos_b + 2
repeat px
diff_b = peek(vram1, vpos_b) - peek(vram2, vpos_b)
diff_g = peek(vram1, vpos_g) - peek(vram2, vpos_g)
diff_r = peek(vram1, vpos_r) - peek(vram2, vpos_r)
sum_b += diff_b * diff_b
sum_g += diff_g * diff_g
sum_r += diff_r * diff_r
vpos_b += 3
vpos_g += 3
vpos_r += 3
loop
loop
if(sum_r != 0.0) :psnr_r = str(-logf(255.0 / sqrt(sum_r)) * 20 / M_LN10) :else :psnr_r = "∞"
if(sum_g != 0.0) :psnr_g = str(-logf(255.0 / sqrt(sum_g)) * 20 / M_LN10) :else :psnr_g = "∞"
if(sum_b != 0.0) :psnr_b = str(-logf(255.0 / sqrt(sum_b)) * 20 / M_LN10) :else :psnr_b = "∞"
diff_time = timeGetTime() - start_time :timeEndPeriod 1
gsel 0
mes diff_time
mes psnr_r
mes psnr_g
mes psnr_b
ただ実は、RGB値に対するPSNRに限った場合、HSPCVを使えば高速化することが可能です。
ポイントとしては、HSPCVにはCVバッファ間でコピーするcvcopy命令があり、演算オプションに差の絶対値を返すCVCOPY_DIFがあるということ。つまり、一旦2枚の画像をCVバッファにコピーし、差の絶対値を取った後に標準画面に書き出し、その後VRAMを叩けばいいのです。
# include "hspcv.as"
# include "hspmath.as"
# uselib "winmm.dll"
# cfunc global timeGetTime "timeGetTime"
# func global timeBeginPeriod "timeBeginPeriod" int
# func global timeEndPeriod "timeEndPeriod" int
// OpenCV利用
buffer 1 :picload "a.png"
buffer 2 :picload "b.png"
timeBeginPeriod 1 :start_time = timeGetTime()
gsel 1
px = ginfo_winx :py = ginfo_winy
cvbuffer 1, px, py :gsel 1 :cvputimg 1
cvbuffer 2, px, py :gsel 2 :cvputimg 2
cvcopy 1,0,0,2,CVCOPY_DIF
buffer 3, px, py :cvgetimg 2, 0 :mref vram, 66
sum_r = 0.0 :sum_g = 0.0 :sum_b = 0.0
vwidth = ((px * 3) + 3) & 0xfffffffc
repeat py
// 比較する順番はPSNRに関係しない
vpos_b = cnt * vwidth
vpos_g = vpos_b + 1
vpos_r = vpos_b + 2
repeat px
diff_b = peek(vram, vpos_b)
diff_g = peek(vram, vpos_g)
diff_r = peek(vram, vpos_r)
sum_b += diff_b * diff_b
sum_g += diff_g * diff_g
sum_r += diff_r * diff_r
vpos_b += 3
vpos_g += 3
vpos_r += 3
loop
loop
if(sum_r != 0.0) :psnr_r = str(logf(255.0 / sqrt(sum_r/px/py)) * 20 / M_LN10) :else :psnr_r = "∞"
if(sum_g != 0.0) :psnr_g = str(logf(255.0 / sqrt(sum_g/px/py)) * 20 / M_LN10) :else :psnr_g = "∞"
if(sum_b != 0.0) :psnr_b = str(logf(255.0 / sqrt(sum_b/px/py)) * 20 / M_LN10) :else :psnr_b = "∞"
diff_time = timeGetTime() - start_time :timeEndPeriod 1
gsel 0
mes diff_time
mes psnr_r
mes psnr_g
mes psnr_b
とはいえ、VRAMで読む作業が残ってしまうのもまた事実。時間計測したところ、次のような結果になりました(単位は[ms])。
| 画像サイズ | cvcopyする部分 | peekで読む部分 | 差の二乗を計算して足す部分 | 合計 |
|---|---|---|---|---|
| 640x480 | 2 | 100 | 58 | 160 |
| 1920x1080 | 10 | 270 | 150 | 430 |
画像のハッシュを取得してみる
『画像にハッシュが存在するのか』と思われるかもしれませんが、実は存在します。
SHA-256など、通常の一方向性ハッシュ関数だと「僅かにデータが異なるとハッシュ値が大きく異なる」といった特性があります。これは利点でもありますが同時に欠点でもあり、画像のように「似たデータなら似た結果を返して欲しい」場合には向きません。
このことから、画像の特徴量取得のために様々な手法が開発されていますが、その中でも簡単かつ有効な手段の一つに「Average Hash」があります。手順としては次の通り。
- 画像を8x8など手頃なサイズに縮小(画素数がnなら、n[bit]のハッシュ値になる)
- 画像をグレースケール化
- 画素値の平均を計算
- 各画素を見ていって、画素の明るさ<画像値の平均なら0、そうでないなら1としてビットを割り当てる
これをHSPのみで実装するとこんな感じ。1920x1080の画像相手でも0.15[ms/回]ほどですので、その高速性が窺えるでしょう。
ちなみに参考資料にあるように16x16で計算すると1.97[ms/回]ほどですが、lena.jpg相手に計算すると、参考資料のと比較して14bitしか違いませんでした(細かな部分の差が結構あるのに)。
# module
// ハッシュに使用する縮小画像のサイズを指定
#const ahash_x 8
#const ahash_y 8
#const vwidth (((ahash_x * 3) + 3) & 0xfffffffc)
// 64bitなので、ハッシュ値は32bitづつ格納する
#deffunc ahash array hash_
// 元画像の情報を取得する
sel_win_id = ginfo_sel
wx = ginfo_winx :wy = ginfo_winy
// 縮小を掛ける
buffer 99, ahash_x, ahash_y
gzoom ahash_x, ahash_y, sel_win_id, 0, 0, wx, wy, 1
// 画像を読み込み、同時にグレースケール化・平均値計算を行う
mref vram, 66
ddim clr, ahash_y, ahash_x
average = 0.0
repeat ahash_y
y = cnt
vpos_b = (ahash_y - cnt - 1) * vwidth
vpos_g = vpos_b + 1
vpos_r = vpos_b + 2
repeat ahash_x
temp = 0.299 * peek(vram, vpos_r) + 0.587 * peek(vram, vpos_g) + 0.114 * peek(vram, vpos_b)
clr(y, cnt) = temp
average += temp
vpos_b += 3
vpos_g += 3
vpos_r += 3
loop
loop
average = average / ahash_x / ahash_y
// 32bitづつ格納する
p = 0 :hash = 0
repeat 4
y = cnt
repeat ahash_x
if(p != 0) :hash = hash << 1
if(average <= clr(y, cnt)) :hash = hash | 1
p++
loop
loop
hash_(0) = hash
p = 0 :hash = 0
repeat 4, 4
y = cnt
repeat ahash_x
if(p != 0) :hash = hash << 1
if(average <= clr(y, cnt)) :hash = hash | 1
p++
loop
loop
hash_(1) = hash
gsel sel_win_id
return
# global
画像拡大/縮小アルゴリズムの質について
HSPでは、標準命令による拡大縮小・Artlet2Dによる拡大縮小・HSPCVによる拡大縮小などのルーチンが使用できます。
しかし、その「質」について考えてみたことはあるでしょうか?
例えば、画像の横幅が1/2になったとします。元画像がCZPのようにみっちり高周波が詰まったものだとすると、縮小後は外側1/2の部分は高周波を表しきれずにグレー化するはずです。逆に、何らかの模様が外側1/2の部分に存在した場合、一般的な画像では潰しきれない高周波成分がモアレとして現れることになります。
そこで、HSPにおける各種画像リサイズ命令を比較してみることにしました。CZPの元画像はここにあります。

……こうして見ると、OpenCVバイキュービックの粗さが目立ちます。適当なリサイズソフトで「バイキュービック」指定で縮小しても、そこまで縞が目立つことはありませんでした。後で調べてみたところ、単なるバイキュービックだとシャープ化(高周波強調)の処理が入るので、事前にローパスフィルタでぼかすことでエイリアシングを軽減する作戦があるようです。
ちなみに画像を比較してみたところ、HSPCVにおいてCZPを50%縮小した場合、**『最近傍法=バイキュービック、バイリニア≒モアレ軽減』**の関係が成り立ちました(40%縮小や60%縮小などではこの関係は成り立ちません)。
また、本来OpenCVではLanczosアルゴリズムによる縮小が可能ですが、2007年に追加された都合からか、HSPCVに採用されているOpenCVはなんとバージョン1.0! 道理でLanczosアルゴリズムが使えないわけだ。
画像をフーリエ変換してみる
そもそもフーリエ変換やDCTなどは、計算量を食う処理ですのでHSPには向きません。
ただ、なまじDLL(APIなど)を叩けてしまうことから、HSPでフーリエ変換を扱うことはできます。
例えば、FFTライブラリとして著名なFFTWには2次元FFTを行うルーチンがありますので、それを流用すると簡単に画像をフーリエ変換することができます。
;FFTWのAPIを呼び出すための宣言
# uselib "libfftw3-3.dll"
# cfunc fftw_malloc "fftw_malloc" int
# cfunc fftw_plan_dft_2d "fftw_plan_dft_2d" int, int, sptr, sptr, int, int
# func fftw_execute "fftw_execute" int
# func fftw_free "fftw_free" sptr
;FFTWのAPIを呼び出すための定数定義
# const fftw_complex_size 16
# const FFTW_FORWARD -1
# const FFTW_ESTIMATE 64
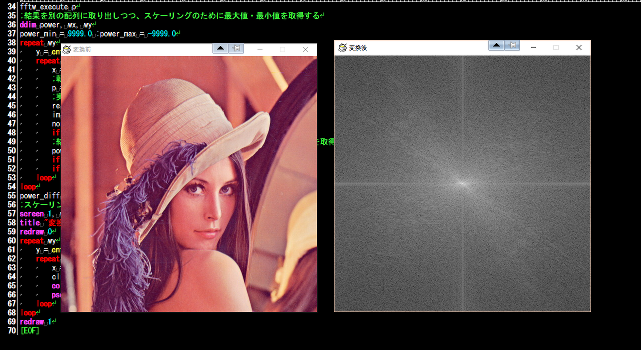
;対象となる画像を読み込む
screen 0, 640, 480 :title "変換前" :picload "lena.jpg"
wx = ginfo_winx :wy = ginfo_winy
;入力用バッファを確保する
in_ptr = fftw_malloc(fftw_complex_size * wx * wy)
dupptr in_data, in_ptr, fftw_complex_size * wx * wy, vartype("double")
;画像のY成分を取り出して代入する
repeat wy
y = cnt
repeat wx
x = cnt
p = y * wx + x
pget x, y
in_data(p * 2) = 0.299 * ginfo_r + 0.587 * ginfo_g + 0.114 * ginfo_b
in_data(p*2+1) = 0.0
loop
loop
;出力用バッファを確保する
out_ptr = fftw_malloc(fftw_complex_size * wx * wy)
dupptr out_data, out_ptr, fftw_complex_size * wx * wy, vartype("double")
;FFTを行う
p = fftw_plan_dft_2d(wy, wx, in_ptr, out_ptr, FFTW_FORWARD, FFTW_ESTIMATE)
fftw_execute p
;結果を別の配列に取り出しつつ、スケーリングのために最大値・最小値を取得する
ddim power, wx, wy
power_min = 9999.0 :power_max = -9999.0
repeat wy
y = cnt
repeat wx
x = cnt
;転地処理を行うので、座標をズラしている
p = ((y + wy / 2) \ wy) * wx + ((x + wx / 2) \ wx)
;実部と虚部を取得し、絶対値を取りつつ対数処理している
re = out_data(p * 2)
im = out_data(p*2+1)
norm = re * re + im * im
if(norm != 0.0) :norm = logf(norm) / 2
;結果(パワースペクトルの対数値)を配列に代入しつつ、最大値・最小値を取得
power(x, y) = norm
if(power_min > norm) :power_min = norm
if(power_max < norm) :power_max = norm
loop
loop
power_diff = power_max - power_min
;スケーリングしながら、画像として書き出す
screen 1, wx, wy
title "変換後"
redraw 0
repeat wy
y = cnt
repeat wx
x = cnt
clr = int((power(x, y) - power_min) / power_diff * 255)
color clr, clr, clr
pset x, y
loop
loop
redraw 1
以下に実行例を示します(流石にlena画像ぐらいはググってダウンロードしてください)。