概要
2016年5月2日に出たこの記事を見て驚きました。同じようなコードでベンチマークした結果、C++がC# unsafeに負けるというとんでもないことになっているではありませんか!
気づいたら、C# が C++ の速度を凌駕している! - espresso3389の日記
というわけで、C++側にも逆転の目はないのか、調査してみることにしました。
まずは小手調べ
この記事の主張としては、「昔に組んだ画像処理(を模した)コードでベンチマークしたところ僅差だったので、再度トライしたらC#が勝ってしまった」ということ。実験条件は明記されていますので、まずは追試してみましょう。
とは言っても、コンパイラはともかくCPUまで揃えることは現実的ではありません。したがって次のような条件になることをお許し下さい。
Windows 10 Pro バージョン 1511(OSビルド 10586.218) 64bit版
.NET Framework 4.6.1
Visual Studio 2015 Update 2
CPU: Intel Core i7-4790K(定格、TBは切ってない)
Memory: 12GB(DDR3)
csc.exe バージョン 1.2.0.60317
cl.exe バージョン 19.00.23918 for x64
説明通りのコンパイルオプションでコンパイル(64bit)して各10回実行すると、次のような結果になりました(単位はミリ秒)。
| 言語 | 速度(最速) | 速度(平均) | 速度(最遅) |
|---|---|---|---|
| C#(test1) | 2320 | 2346.6 | 2382 |
| C#(test2) | 1875 | 1893 | 1913 |
| C++ | 1594 | 1621.9 | 1656 |
……この時点でC++が勝っている気がしますが、話を進めましょう。
コードをモダンにしてみる
コードが5年前基準だからか、C++側のコードが凄く怪しく見えます。Windowsべったりのコードですし、少し手直しするだけでC89としてコンパイルが通りそうなぐらいです。というわけで、C++11基準で書き直してみました。
// Compile: cl speedtest2.cpp /O2 /GL /EHsc
# include<chrono>
# include<cstdint>
# include<iostream>
using Byte = uint8_t;
void test(){
//! 画面サイズを設定する
size_t w = 4321, h = 6789;
//! ストライドの大きさを計算する
//! (横幅を4で割り切れる画素数にする)
size_t stride = ( w + 3 ) & ~3;
//! 領域を確保する(各画素は1バイト)
auto *a = new Byte[stride * h];
//! 二次元直交座標のX・YのXORを画素に代入する
//! (擬似的な画像処理のテスト)
for(size_t y = 0; y < h; y++){
auto p = a + y * stride;
for(size_t x = 0; x < w; x++){
p[x] = static_cast<Byte>(x ^ y);
}
}
delete[] a;
}
int main(){
//! 計測開始
auto start = std::chrono::system_clock::now();
//! 計測用コード
for(size_t i = 0; i < 100; ++i){
test();
}
//! 計測終了・集計
auto end = std::chrono::system_clock::now();
auto msec = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << msec << "[ms]" << std::endl;
}
ベンチマーク結果は次の通り。少し遅くなったように見えるのは、XORする際の数値がintからsize_tになったことが影響しているのでしょうか……? そもそもどういった処理なんだこれ
| 言語 | 速度(最速) | 速度(平均) | 速度(最遅) |
|---|---|---|---|
| C++(その2) | 1695 | 1706.8 | 1723 |
SIMD intrinsicを適用してみる
画像処理と言えばSIMDだとばっちゃが言ってましたので、更なる最適化を図ります。画素がByte型(1byte=今回は8bit)で、横幅が4の倍数になるようにしていますので、基本的には32bit単位で扱えるわけですね。実際には元データがRGBAだったりするので128bitとして扱いやすくなるのですが
元のテスト環境では、SandyBridgeのCore i7-3770Sが使用されていました。したがって、整数演算としてAVX2は使えず、SSEナントカ(128bit)で処理することになります。つまり、おおよそこういったコードになるでしょう。
//! Compile: / GS / GL / analyze - / W3 / Gy / Zc:wchar_t / Zi / Gm - / O2 / sdl
//! / Fd"Release\vc140.pdb" / Zc : inline / fp : precise / D "WIN32"
//! / D "NDEBUG" / D "_CONSOLE" / D "_UNICODE" / D "UNICODE"
//! / errorReport : prompt / WX - / Zc : forScope / arch : AVX / Gd
//! / Oy - / Oi / MD / Fa"Release\" /EHsc /nologo /Fo"Release\"
//! /Fp"Release\sample.pch"
# include<chrono>
# include<cstdint>
# include<iostream>
# include<immintrin.h>
using Byte = uint8_t;
void test(){
//! 画面サイズを設定する
const size_t w = 4321, h = 6789;
//! ストライドの大きさを計算する
//! (横幅を4で割り切れる画素数にする)
const size_t stride = ( w + 3 ) & ~3;
//! 領域を確保する(各画素は1バイト)
//! 本来ならアラインメントを揃えたいところだが……
auto *a = new Byte[stride * h];
//! 二次元直交座標のX・YのXORを画素に代入する
//! (擬似的な画像処理のテスト)
for(size_t y = 0; y < h; y++){
auto p = a + y * stride;
const auto simd_y = _mm_set1_epi8(y);
for(size_t x = 0; x < (w >> 4) << 4; x += 16){
const auto simd_x = _mm_set_epi8(
x+15,x+14,x+13,x+12,x+11,x+10,x+ 9,x+ 8,
x+ 7,x+ 6,x+ 5,x+ 4,x+ 3,x+ 2,x+ 1,x+ 0);
const auto simd_xor = _mm_xor_si128(simd_x, simd_y);
_mm_storeu_si128((__m128i*)(p + x), simd_xor);
}
for(size_t x = (w >> 4) << 4; x < w; ++x){
p[x] = static_cast<Byte>(x ^ y);
}
}
delete[] a;
}
int main(){
//! 計測開始
auto start = std::chrono::system_clock::now();
//! 計測用コード
for(size_t i = 0; i < 100; ++i){
test();
}
//! 計測終了・集計
auto end = std::chrono::system_clock::now();
auto msec = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << msec << "[ms]" << std::endl;
}
ベンチマーク結果は次の通り。どういうわけかプロジェクトファイルを組んでIDEからコンパイルした方が速かったので、その際のコンパイルオプションをコメントに付記しています。ちなみにそのままAVX2化(256bit毎処理するように)するとなぜか遅くなりました……。
| 言語 | 速度(最速) | 速度(平均) | 速度(最遅) |
|---|---|---|---|
| C++(その3) | 1460 | 1474.3 | 1489 |
まとめ
いずれにせよ、C++の方が一応速いようです。より画像処理らしいコードでも対決してみたいですね。
| 言語 | 速度(最速) | 速度(平均) | 速度(最遅) |
|---|---|---|---|
| C#(test1) | 2320 | 2346.6 | 2382 |
| C#(test2) | 1875 | 1893 | 1913 |
| C++ | 1594 | 1621.9 | 1656 |
| C++(その2) | 1695 | 1706.8 | 1723 |
| C++(その3) | 1460 | 1474.3 | 1489 |
おまけ
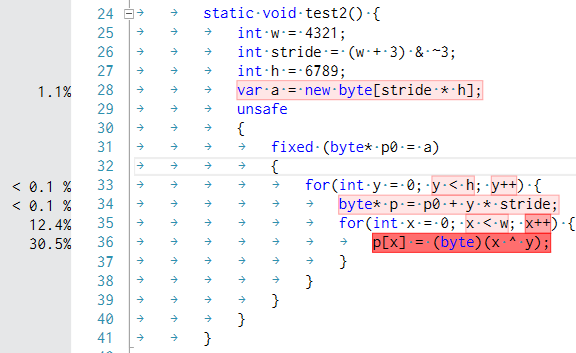
元コードのボトルネックを検証してみたところ、xとyとのXOR結果をByteにキャストする部分が一番重いという身も蓋もない結論になりました。ご査収ください。
(プロファイリング用に、C++側は意味を変えない範囲内でコードを改変しています)
※C++
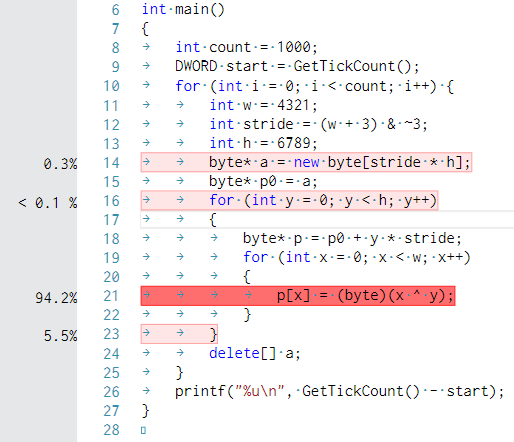
※C#(test2)