はじめに
休みに初めて子供を連れて某夢の国に行こうという話になり、できる父を目指して、クチコミを調べていたとき、読むのがめんどくさ、いい感じにサクッと情報集めてまとめられないかなと思い、ウェブスクレイピングを試してみました。
スクレイピング用パッケージ
rvest
Rでもっとも有名なスクレイピング用パッケージ。記事もたくさん見つかります。
通常のパッケージと同様にinstall後、使用可能。
RSelenium
WEB UIテストの自動化ツールであるSeleniumをRから実行できるパッケージ。
ローカルで立ち上げたSeleniumサーバを通して、ウェブページを操作することができます。
今回は、取得したいページで多数「続きを読む」というボタンを押す必要があるため使用しました。
対象ページ
こちら:東京ディズニーランドアトラクションランキング2019
ページ構成と収集にあたってのポイントは以下のような感じ
①リンク先にはアトラクションのランキング(全2ページ。40個のアトラクション)
②ランキングから各アトラクションのクチコミに飛べる
③各アトラクションのクチコミはpタグに収められている
④「続きを読む」ボタンを押さないとすべてのクチコミが表示されない
⑤「続きを読む」ボタンにより3件のクチコミが追加表示される
コード
対象ページのurl取得
ある程度ページの構成を理解したところで、コードを書いてみます。
まずは、各アトラクションのクチコミページのurlを取得します。
library(RSelenium)
library(rvest)
library(stringr)
library(stringi)
library(RMeCab)
library(tidyverse)
library(magrittr)
library(ggraph)
library(igraph)
library(Nippon)
# アトラクションは全2ページ
url1 <- "https://tdrnavi.jp/park/tdl/attraction/?pageID=1"
url2 <- "https://tdrnavi.jp/park/tdl/attraction/?pageID=2"
# 2ページのページソースをrvestで取得
page1 <- read_html(url1)
page2 <- read_html(url2)
# アトラクションは1ページに20件載っている
# この後のスクレイピングのため、個々のアトラクションのurlを文字列として取り出す。
# 最下段の3件は今後出てくる新しいアトラクションが載っているので削除(20190315時点)
link1 <- html_nodes(page1, xpath = "//a[@class ='box']") %>%
html_attr("href") %>%
str_subset("attraction") %>%
as.data.frame() %>% .[1:20,] %>% as.data.frame()
link2 <- html_nodes(page2, xpath = "//a[@class ='box']") %>%
html_attr("href") %>%
str_subset("attraction") %>%
as.data.frame() %>% .[1:20,] %>% as.data.frame()
# 2ページ分の各アトラクション40件のレビューページのアドレスをlistとして保存
link_attraction <- rbind(link1, link2)
colnames(link_attraction) <- "adress"
link_attraction$adress %<>% paste0("https://tdrnavi.jp", .) %>% as.list()
# 必要により分析対象を絞る(1-10位)
link_attraction <- link_attraction[1:10,]
対象ページからクチコミの文章を取得
今回対象にしているページは、以下のポイントを考慮する必要があります。
④「続きを読む」ボタンを押さないとすべてのクチコミが表示されない
⑤「続きを読む」ボタンにより3件のクチコミが追加表示される
何もせず、pタグの情報を取得しても、その時点で表示されている一部のクチコミデータしか拾うことができませんでした。
そこで、RSeleniumを利用して、続きを読むボタンをすべて押してあげてから、ページソースを取得して、クチコミ(pタグ内の文章)を収集することにします。
# ブラウザを開いておく
rem <- remoteDriver(port = 4444L, browserName = "chrome")
# 続きを読むボタンを全部押して、口コミデータをすべて表示させる関数を作成
get_page <- function(url){
rem$open()
rem$navigate(url)
# クチコミの件数を、h2タグから拾う
html <- read_html(url)
count <- html_nodes(html, xpath = "//h2[@class = 'title center']") %>% html_text()
count_review <- count[str_which(count, "クチコミ")] %>% str_extract_all("\\d+") %>% as.numeric()
# クチコミ件数からクリックの回数を決める。今回は、1クリックで3件分の口コミが現れることが
# わかっているので、クチコミ件数を3で割って、小数点以下を切り捨てた数字をクリック数とする。
# 6件より少ない時は1回クリックするようにする
if (count_review < 6){
count_click <- 1
}else{
count_click <- floor(count_review/3)-1
}
# count_clickの回数分、続きを読むをクリックして、全クチコミを表示させている。
for (n in 1:count_click){
remEle <- rem$findElement('xpath', "//div[@class = 'moreBtn']")
remEle$clickElement()
count_click
Sys.sleep(1)
}
}#関数ここまで
# ページを表示させたら、pタグ内の口コミ文書を読み込む処理をlink_attraction分くり返す
for (i in link_attraction) {
get_page(i) #先ほど作成した自作関数
pagetxt <- rem$getPageSource()#続きを読むをすべて展開した状態のページソースを取得
html <- read_html(pagetxt[[1]])
# アトラクション名をtitleとして取得
title <- html_nodes(html, xpath = "//span[@property = 'v:itemreviewed']") %>% html_text()
# クチコミ文章をtxtとして取得
txt <- html_nodes(html, xpath = "//p") %>% html_text() %>% str_remove_all("\n|\t")
# dataframeとして、アトラクション名(title)とクチコミ文章(txt)をかきだす
# stringi::str_flattenでアトラクションごとにクチコミはまとめる
df <- data.frame(title, txt) %>% group_by(title) %>% summarise(review = str_flatten(txt)) %>% ungroup()
# 全角は半角に
df$review %<>% zen2han()
# なぜか文字コードでエラーが出る場合がある・・・未解決。tryでとりあえず回避
try(write.table(df, "kuchikomi.txt", col.names = F, row.names = F, append = T))
# 1ページ取得が終わったら、ブラウザを閉じる
rem$quit()
}
# データを確認
# なぜか文字コードでエラーが出る場合がある・・・tryでとりあえず回避
kuchikomi <- try(read.table("kuchikomi.txt")) %>% as.data.frame()
colnames(kuchikomi) <- c("attraction", "review")
上の処理で、kuchikomi.txtに各アトラクションのクチコミがまとまりました。
集まったクチコミを形態素解析して、タイトルと単語のペアリストを作成
RMeCabを使用して、タイトルと単語のペアとその件数リストを作ってみます。
ストップワードは以前の記事で使用したものに、自分でいくつかキーワードを追加したデータを流用しました。
# なぜか文字コードでエラーが出る場合がある・・・未解決。tryでとりあえず回避
kuchikomi <- try(read.table("kuchikomi.txt")) %>% as.data.frame()
colnames(kuchikomi) <- c("attraction", "review")
# RMeCabDFで形態素解析
# 文書ごとのキーワードの品詞別リストを作成。1文書1トークン状態
kuchikomi_tokens <- kuchikomi %>% RMeCabDF(coln = "review")
kuchikomi_tokens <- purrr::pmap_df(list(nv = kuchikomi_tokens,
title = as.character(kuchikomi$attraction)),
function(nv, title){
tibble(title = title, term = nv, hinshi = names(nv))
})
# 数字が名詞になって残っている場合があるので(無理やり)削除
suji <- kuchikomi_tokens$term %>% str_detect("[0-9]")
kuchikomi_tokens %<>% filter(!(suji))
# stop wordの読み込み
stop_word <- read.csv("jpn_stopword.csv", header = T, fileEncoding = "UTF-8-BOM")
stop_word$term <- as.character(stop_word$term)
# stop wordを削除、品詞絞り込み、件数カウント
kuchikomi_tokens2 <- kuchikomi_tokens %>% anti_join(stop_word, by = "term") %>%
filter(hinshi %in% c("名詞","形容詞")) %>%
group_by(title,term) %>% summarise(count = n()) %>% ungroup() %>%
group_by(title) %>% top_n(10) %>% ungroup()
colnames(kuchikomi_tokens2) <- c("item1", "item2", "n")
# データ確認
> head(kuchikomi_tokens2,10)
# A tibble: 10 x 3
item1 item2 n
<chr> <chr> <int>
1 イッツ・ア・スモールワールド アトラクション 55
2 イッツ・ア・スモールワールド イッツ・ア・スモールワールド 17
3 イッツ・ア・スモールワールド イッツアスモールワールド 14
4 イッツ・ア・スモールワールド キャラクター 31
5 イッツ・ア・スモールワールド クリスマス 19
6 イッツ・ア・スモールワールド ディズニー 28
7 イッツ・ア・スモールワールド ディズニーランド 22
8 イッツ・ア・スモールワールド ピノキオ 18
9 イッツ・ア・スモールワールド ファストパス 15
10 イッツ・ア・スモールワールド リニューアル 25
> tail(kuchikomi_tokens2,10)
# A tibble: 10 x 3
item1 item2 n
<chr> <chr> <int>
1 蒸気船マークトウェイン号 周年 9
2 蒸気船マークトウェイン号 証明 10
3 蒸気船マークトウェイン号 乗船 9
4 蒸気船マークトウェイン号 蒸気 8
5 蒸気船マークトウェイン号 川 6
6 蒸気船マークトウェイン号 船 25
7 蒸気船マークトウェイン号 待ち時間 6
8 蒸気船マークトウェイン号 搭乗 6
9 蒸気船マークトウェイン号 風 8
10 蒸気船マークトウェイン号 夜 8
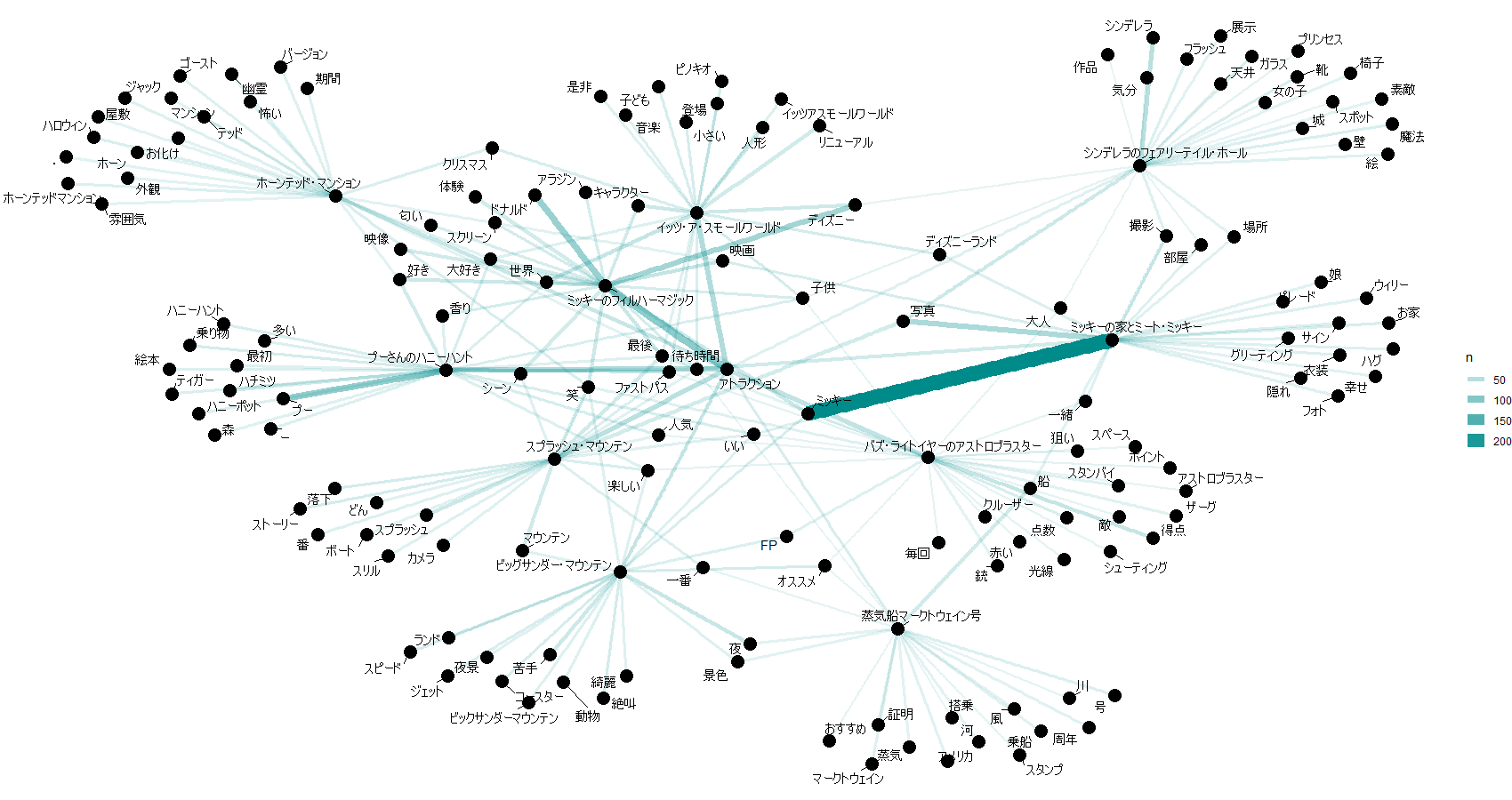
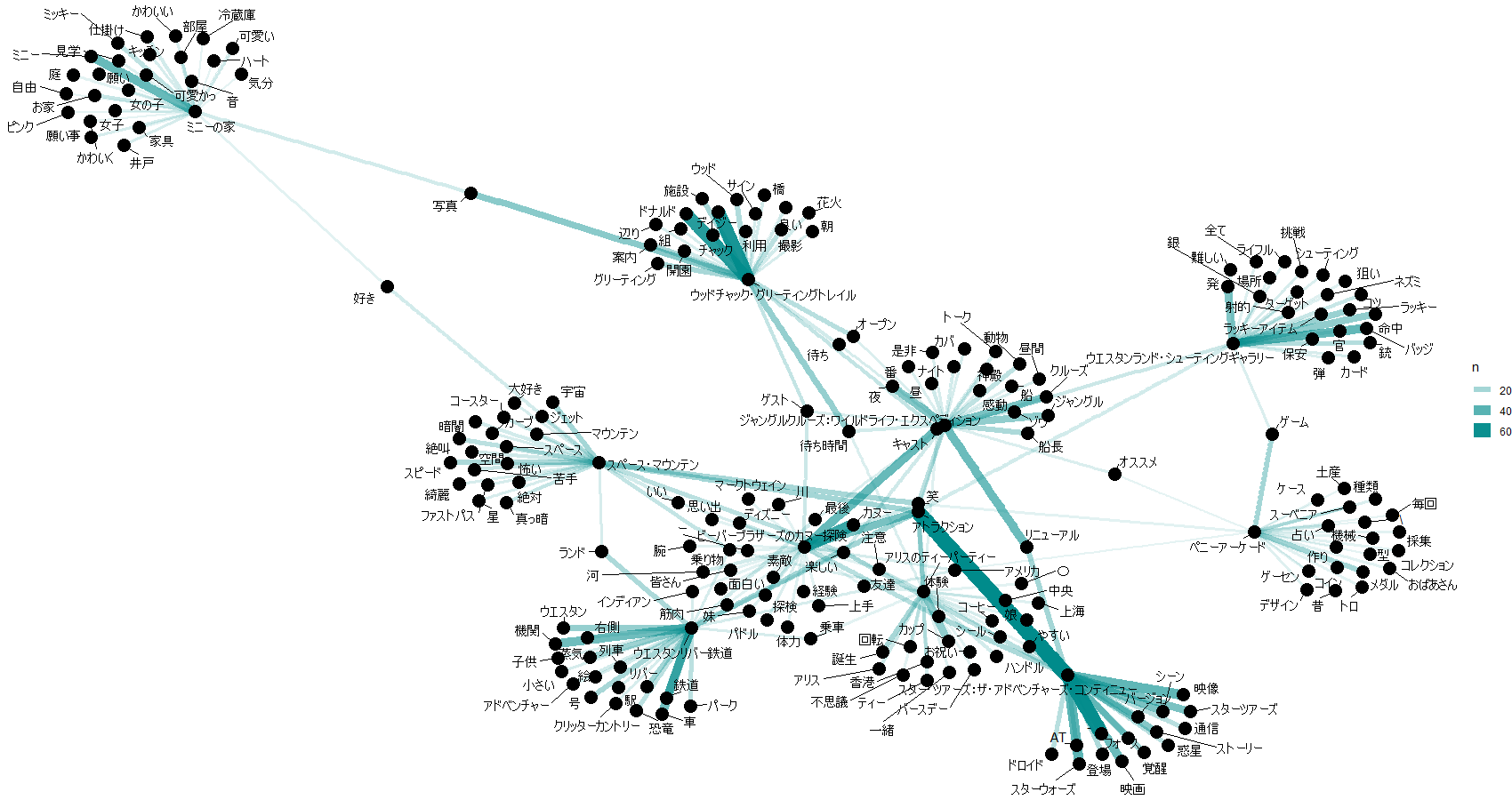
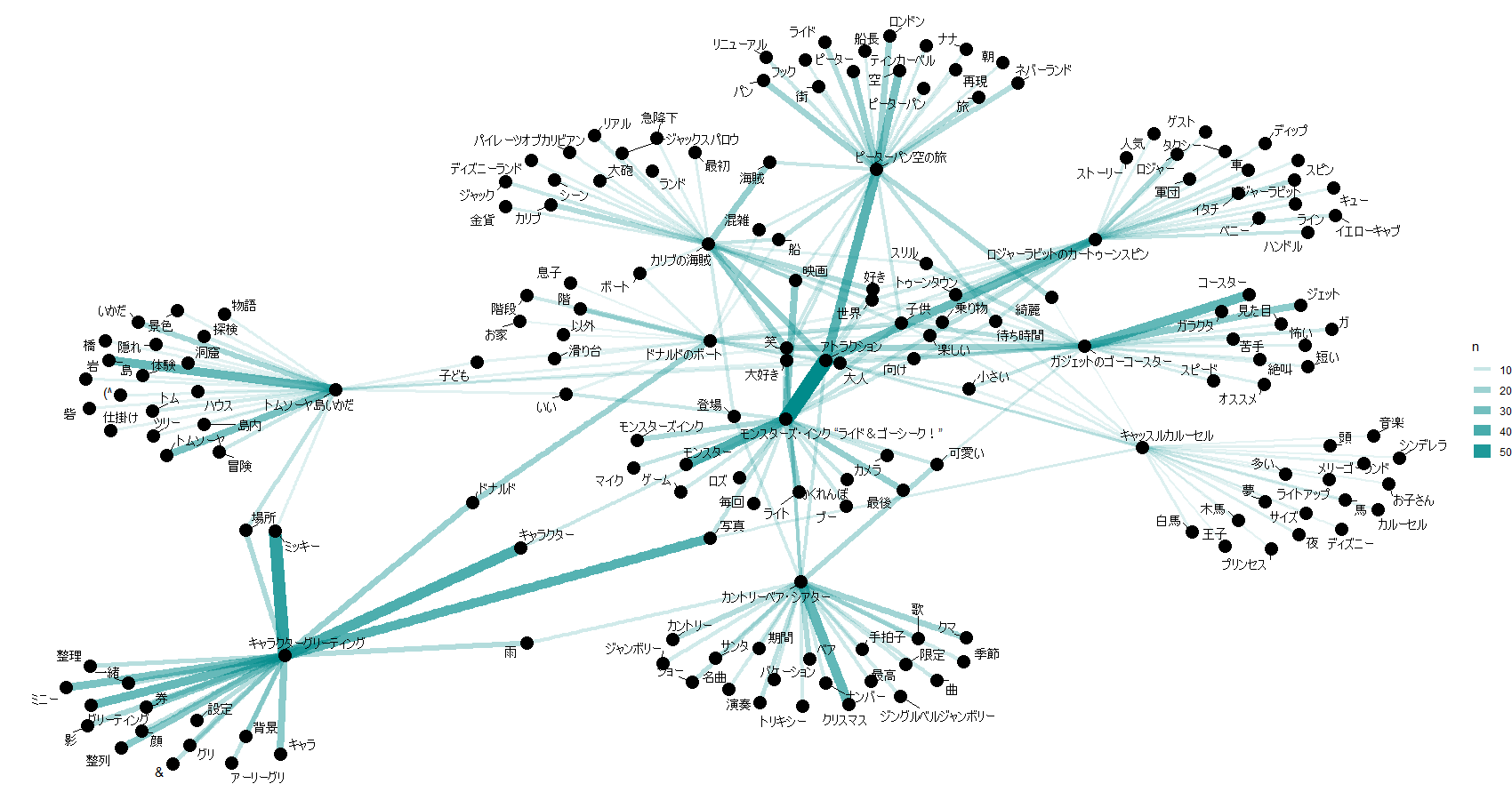
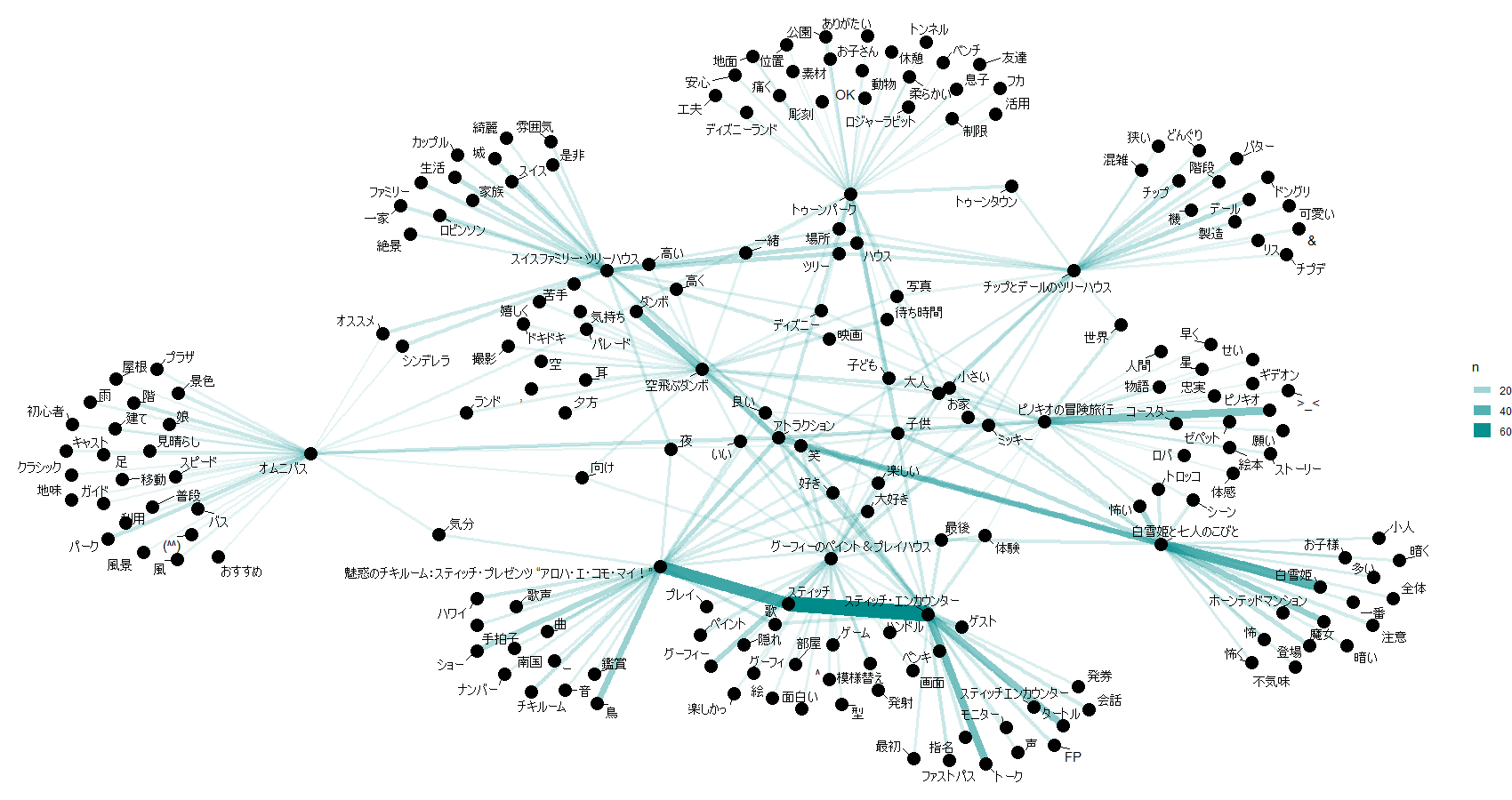
アトラクション毎のキーワード件数top20のペアリストができました。
これをもとにアトラクション毎のキーワードを可視化してみます。
キーワードの可視化
アトラクションとキーワードのペアの件数表が作成できたので、ネットワークグラフを書いてみます。
word_graph <- kuchikomi_tokens2 %>%
graph_from_data_frame() %>%
ggraph(layout = 'fr') +
geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "cyan4") +
geom_node_point(size = 5) +
geom_node_text(aes(label = name), repel = T, point.padding = unit(0.2, "lines")) +
theme_void()
word_graph
以上、これまでの処理を10アトラクションごとに可視化したものが以下。
20190402修正済み
1-10位
11-20位
21-30位
31-40位
最後に
途中何度も文字コードエラーに遭遇しつつも、何とかごり押しで進めましたが、結局心折れました。
まったく同じ処理なはずなのに、エラーが起きたり起きなかったり、拾えている文字が化けたり化けなかったり。。
utf-8⇔cp932?たぶんこの往復でおかしなことに。
完全に処理しきれぬまま、可視化してるもので、化けた文字が紛れたままだったり、取得できていないアトラクションがあったりと散々です。
戒めのため、そのまま載せています。
解決したら更新したいです。
4月2日更新
解決:大文字を小文字にしようとtolower()を使用した際、文字化けが生じていた模様。
修正済みの結果を追記。
参考
「Rによるテキストマイニング―tidytextを活用したデータ分析と可視化の基礎」オライリージャパン
「Rによるスクレイピング入門」C&R研究所