ワードクラウドとは
コトバンクより
ワード‐クラウド(word cloud) 文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法。 ウェブページやブログなどに頻出する単語を自動的に並べることなどを指す。 文字の大きさだけでなく、色、字体、向きに変化をつけることで、文章の内容をひと目で印象づけることができる。
ということのようです。
人によっては、「棒グラフのほうが大小を正確に表すのであまり意味のない表現方法」という解釈もされるようですが、個人的にはデータ分析に明るくない人にもぱっと見で概要を伝えることができるので、それはそれで意味があるものなのではと思っています。横にズラッと並んだ単語なんて見るだけでも疲れますからね。
サンプルデータ
今回は下記のサンプルデータを使ってワードクラウドを作ることを試してみたいと思います。
適当に選んだwikipediaのページ全体をコピペしたものをtxtデータとして保存して使用してみます。
以下sample.txtとして扱います。
形態素解析とRMeCab
素人が下手に語るとぼろが出るので、詳しくは書けませんが、文章を分析する前には事前に単語ごとに分解をしておく必要があります。その操作にはRMeCabパッケージを使用します。他にも有名どころでtmパッケージなどがありますが、日本語ならRMeCabがおすすめ。
事前設定は、下記をご参照。
サンプルのtxtデータをさっそくRMeCabで読み込んでみます。
文章を単語ごとに分割し頻度を表示してくれるRMeCabFreq()関数を利用します。
細かいことを気にしなければ、この関数にデータを放り込むだけで頻度表がサクッと作成できます。
library(RMeCab)
sample <-RMeCabFreq("sample.txt")
Termに単語、Info1に品詞大分類、Info2に品詞細分類、Freqに出現回数が表示されます。
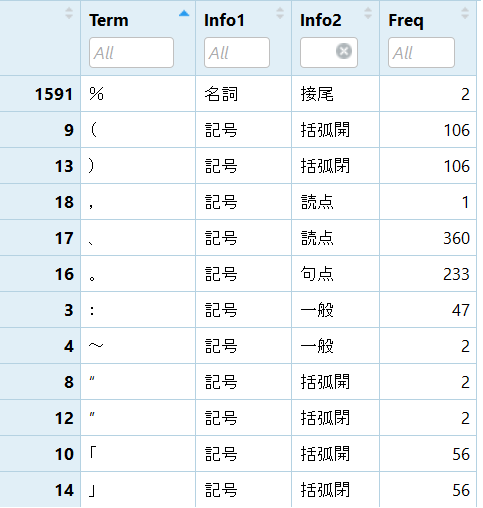
ここで、私の場合いくつかの問題にぶち当たりました。
細かく書きませんが、残しておきます。
- MeCabの文字コードはdefaultでSHIFT-JIS。RStudioもSHIFT-JIS。PythonはUTF-8。RとPython両方で遊んでたら文字化け地獄から抜け出せなくなりました。MeCab再インストールで解決。
- MeCabのdefault設定では、(とか[とか%とか、記号がなぜか名詞として処理されます。辞書の書き換えで、一部解決。
前処理
いきなりMeCabで形態素解析すると、上記のように記号などのゴミ処理にすごく困りました。
そこで、tmパッケージを用いて記号等の除去、アルファベットの大文字小文字統一などを事前におこなってから、txtに書き出してMeCabで解析することにしました。
library(tm)
library(magrittr)
# 指定フォルダ内のtxtデータをcorpusとして取り込む
sample <- VCorpus(DirSource(dir="usr/local/"),readerControl=list(language="english"))
sample %<>% tm_map(stripWhitespace)#空白の削除
sample %<>% tm_map(removePunctuation)#記号の削除
sample %<>% tm_map(content_transformer(tolower))#大文字小文字統一
sample %<>% tm_map(removeWords,stopwords("english"))#ストップワードの削除
# sample.txtの1ファイルのみなので[[1]]
sample[[1]] %>% as.character() %>% writeLines("sample.txt")# txtデータとして書き出し
VCorpus(DirSource(dir="xxx")))で指定したフォルダ内のtxtデータをまとめてコーパスとして取り込むことができます。
今回は1ファイルのみですが、複数のtxtデータがあった場合でも、この方法で処理を行うことができるので便利です。
処理したsample.txtを改めてRMeCabで解析してみます。
library(RMeCab)
library(dplyr)
library(magrittr)
library(stringr)
sample <- RMeCabFreq("sample.txt")
# 改行の削除
sample$Term <- str_remove_all(sample$Term, "\n")
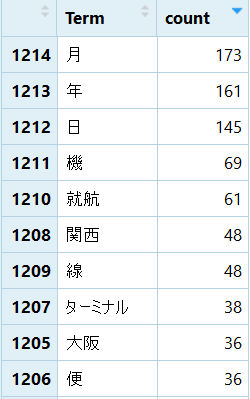
# 品詞の抽出(名詞と形容詞のみ)、数字・不要列の削除、出現頻度の集約、降順で並べ替え
sample_r1 <- sample %>% filter(Info1 %in% c("名詞", "形容詞")) %>%
filter(Info2 != "数") %>% select(Term, Freq) %>% group_by(Term) %>%
summarise(count = sum(Freq)) %>% ungroup() %>% arrange(desc(count))
ここでTermを集約してカウントしなおしているのは、同じ単語でも品詞の違うものとしてカウントされている場合があるからです。中身を確認してみると何とか意味のある言葉を中心に抜き出せたようです。
ワードクラウドにしてみる
先ほど作成した頻度表を元にワードクラウドを作成します。
使用するパッケージはwordcloud2パッケージ。
wordcloudパッケージを使用した場合よりも、見栄えのかっこいい表現ができます。
wordcloudパッケージには2つ関数があり、wordcloud2()とlettercloud()があります。
wordcloud2はshape引数で、形状をいくつか選択できます。
The shape of the “cloud” to draw. Can be a keyword present. Available presents are ‘circle’ (default), ‘cardioid’ (apple or heart shape curve, the most known polar equation), ‘diamond’ (alias of square), ‘triangle-forward’, ‘triangle’, ‘pentagon’, and ‘star’.
画像データを用いれば、figPath引数でその画像の形で出力させることも可能です。
lettercloudはその名の通り文字の形で出力させることができます。
ちなみに通常のinstall.packages("wordcloud2")だと、lettercloudがうまく機能してくれない場合があります。
その場合はgithubからのinstallで解決するようです。
library(devtools)
devtools::install_github("lchiffon/wordcloud2")
先ほどの頻度表をwordcloudにしてみます。
library(wordcloud2)
wordcloud2(sample_r1, size=1.6, color='random-light', backgroundColor="black")

出ました。
「日付に関する記述が多そう」「関西大阪沖縄あたりを中心に飛んでる会社かな」
みたいな印象が文章読まなくても何となくわかります。
形状を変える
shapeの変更で形状を変えてみることもできます。
library(wordcloud2)
wordcloud2(sample_r1, size=1.6, color='random-light', backgroundColor="black", shape ="star")

画像をかたどる
figPath指定で画像をかたどることもできます。
好きな白黒画像ファイルをfullパスで指定すればOKです。
飛行機にしてみました。
wordcloud2(sample_r1, figPath = "C:/**/**/plain2.jpg", size = 1.5,color = 'random-light', backgroundColor="black")

大きすぎて年が消えてますがほかにもオプションをいじれば楽しめそうです。
文字をかたどる
letterCloud関数で任意の文字をかたどって出力もできます。たぶんアルファベットのみ。
letterCloud(sample_r1, word= "R" ,size=2)

複数文字でも大丈夫。
letterCloud(sample_r1, word= "PLAIN" ,size=2)

なんかいろいろちょん切れてますが、いろいろ試すと面白いと思います。
参考にした本
「Rによるテキストマイニング入門」森北出版
「Rによるテキストマイニング―tidytextを活用したデータ分析と可視化の基礎」オライリージャパン