はじめに
提案しているパターン抽出の方法を、どんなパターンで使用する事を想定しているか、ECサイトの履歴のシミュレーションを使いながら、示そうと思い記事を書きます。
LLM使いながらやっていたのですが、シミュレーションの条件厳しめになり、あまり綺麗な結果にはなっていませんが、逆に現実味がある結果になったと思います。
パターン抽出の手法に関しては、この記事を参照してください。
また、パターン抽出の実装は、この記事を参照してください。
目的
ECサイトのアクセス履歴から、想定している行動パターンのユーザを特定する事により、アクションをかけるユーザを決める作業を、提案しているパターン抽出方法を用いて行う。
シミュレーション
以下の7つのパターンのシミュレーションを行う。
各パターンで50人ずつ60日分の時系列データを集める事とした。
また、アクセス履歴のデータは、アクセス総時間、アクセス回数、ユニーク商品数とした。
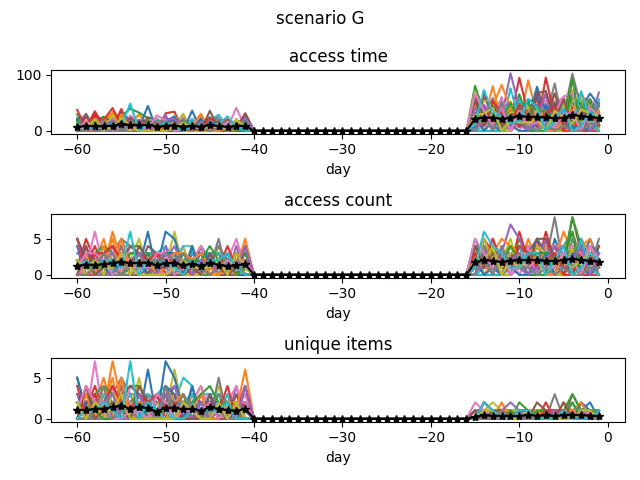
Gのパターンを検出したいとする。
- A:王道型(最も自然)
- B:衝動買い型
- C:熟考型(迷った末に購入)
- D:情報収集のみ
- E:迷走型(決めきれない)
- F:一度見て終わり
- G:再訪型
-
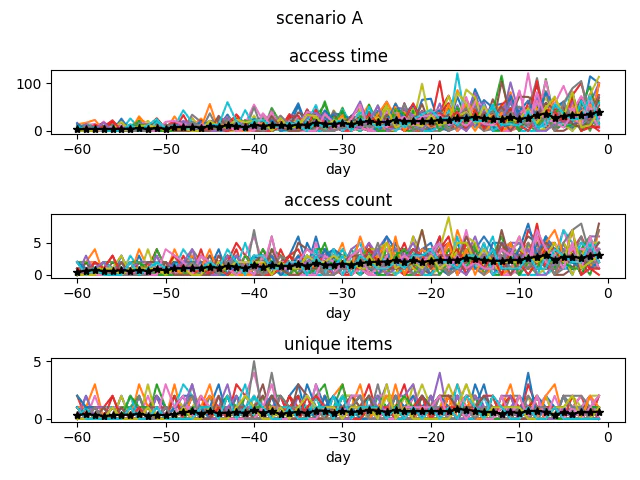
A:王道型(最も自然)
初期:広く浅く探索
中盤:比較のため訪問頻度増
終盤:候補を絞って深く閲覧
→ EC分析として最も「納得感」のあるパターン
-
B:衝動買い型
明確なニーズあり
比較せず短期間で購入
→ レコメンドや広告起点のケースとして説明可能

-
C:熟考型(迷った末に購入)
解釈
比較が長引く
何度も戻って確認
→ 高額商品・BtoB寄り

-
D:情報収集のみ
相場確認・調査目的
他サイトで購入

-
E:迷走型(決めきれない)
比較はするが候補が絞れない
購入障壁(価格・不安)

-
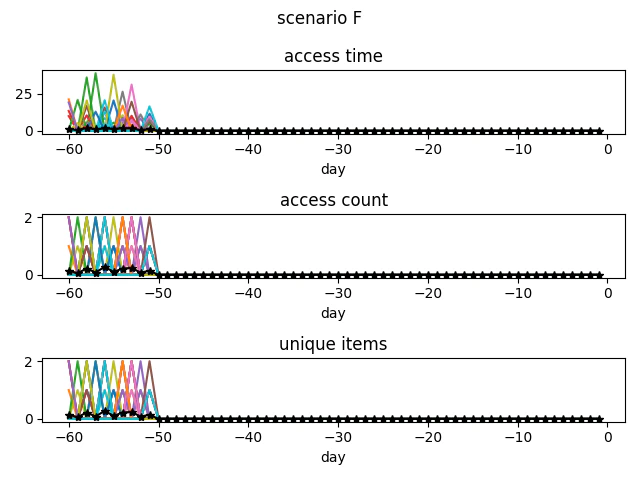
F:一度見て終わり
流入はあるが関心が浅い
-
G:再訪型
セール・外部要因
内発的検討とは別軸
解析
使う変数
アクセス総時間、アクセス回数、ユニーク商品数の三つシミュレーションを行ったが、今回は、パターン抽出手法そのものの挙動確認を主目的としたため、
三変数間の相関構造の違いには踏み込まず、
最も代表的な指標としてアクセス総時間のみを用いた。
新しいパターン抽出を使った解析
データの分散が強いので、7日間平均のデータと比較する事にした。
提案しているパターン抽出の抽出するパターンとなる基底だが、
Gの平均値を見て決める事とし、代表的な点として、46~44日目前を5、2~1日目前を20、他の値は0となるようなパターンとした。
平滑化と特徴的な点以外を0にする事により、データの増減がずれても検出しやすくなる。
データの中間は、0が並びどんな値をとっても無視する事になる。
この基底との相関をとる事により、Gのパターンが含まれるか計算する事ができる。
計算される振幅を閾値で分け、パターンの有無を判断した。
減少も考慮したい場合
減少も考慮したい場合は、常に大きな値をとる基底も用意し、そのパターンを除外する事が必要となる。
また、今回は値が不安定なため採用できないが、差分系列を取得しそのパターンを抽出する事により、パターン抽出する事も可能である。
結果
閾値を0.8として、パターンGがでるTPR(正解する確率)と、その他のパターンごとの、FPR(間違えて検出したとする確率)を計算した。
(各値はユーザ単位で算出している)
tpr:0.92
fpr A:0.78,fpr B:0.16,fpr C:0.98,fpr D:0.0,fpr E:0.48,fpr F:0.0
考察
まず、TPRが0.92となっている、実際のデータを見ると全く再訪パターンになっていないデータが存在する為、1ではなくなっている。
実際のデータ解析に近いシミュレーションができていると感じた。
Aでは、TPRとが高い。これは、だんだんアクセス時間が増加していくパターンだが、もともとの値が大きい為、パターンが内包され、FPRが高くなってしまう傾向にある。
しかし、パターンAは購入の王道パターンとなるので再訪パターンに含まれていても問題が少ないものと思われる。
Bは、値が低くなっている。これは明らかにパターンが違うのである程度分離できている事がわかる。
Cは、非常に高い値となってしまっているが、完全に内包されるパターンとなっている為である。このようなパターンを分離する為には、減少も考慮したい場合の処理が必要となる。
D、Fに関しては、単純にアクセス時間が少ないため誤検出はほとんどしない。
Eは、一定のアクセスはあるが、Cよりも数が少ないため、このくらいの誤検出率となっている。
単一の基底パターンを用いたが、複数の基底を組み合わせることで、
A や C のような内包型パターンの分離も可能になると考えている。
このように、ある程度パターンを想定してシミュレーションを行っても、検出できない事がある。想定しているパターンでも実際に検出できるのってこれくらいなんですね。
しかし、アクセスパターンを想定して抽出する事ができるため、シナリオを仮定して情報を検出する事が可能となる。
本来ならば、より多くの特徴量を使用して、特徴的な点を抽出する事により、より確かなパターン抽出が可能となると考えている。
プログラム
import numpy as np
import pandas as pd
import bedcmm.pattern as bedcmm
import matplotlib.pyplot as plt
np.random.seed(42)
DAYS = 60
DAY_INDEX = np.arange(-DAYS, 0)
def clip(x, low=0):
return np.clip(x, low, None)
def stable_gamma(mean, k=10, size=DAYS):
"""
mean: 平均滞在時間
k: shape(大きいほど安定)
"""
theta = mean / k
return np.random.gamma(k, theta, size)
"""
シナリオA:王道型(最も自然)
時間推移(60日前 → 直前)
指標 挙動
アクセス総時間 緩やかに増加
アクセス回数 後半で増加
ユニーク商品数 前半多い → 後半減少
解釈
初期:広く浅く探索
中盤:比較のため訪問頻度増
終盤:候補を絞って深く閲覧
→ EC分析として最も「納得感」のあるパターン
"""
def scenario_A():
# アクセス回数:後半増加
lam = np.linspace(0.5, 3.0, DAYS)
access_count = np.random.poisson(lam)
# 1回あたり滞在時間(分):後半やや増
mean_time = np.linspace(6, 12, DAYS)
time_per_access = stable_gamma(mean_time, k=10)
access_time = clip(access_count * time_per_access)
# ユニーク商品数:前半多く、後半減少
unique_items = clip(
access_count * np.linspace(0.9, 0.3, DAYS)
+ np.random.normal(0, 0.5, DAYS)
).astype(int)
return access_time, access_count, unique_items
"""
シナリオB:衝動買い型
指標 挙動
総時間 短期間で急増
回数 少ない
ユニーク商品数 少ない
解釈
明確なニーズあり
比較せず短期間で購入
→ レコメンドや広告起点のケースとして説明可能
"""
def scenario_B():
access_count = np.random.poisson(
np.concatenate([np.full(45, 0.3), np.full(15, 3.5)])
)
time_per_access = stable_gamma(10.0, k=10)
access_time = clip(access_count * time_per_access)
unique_items = clip(
access_count * 0.4 + np.random.normal(0, 0.3, DAYS)
).astype(int)
return access_time, access_count, unique_items
"""
シナリオC:熟考型(迷った末に購入)
指標 挙動
総時間 高水準で横ばい
回数 高い
ユニーク商品数 高 → 中程度
解釈
比較が長引く
何度も戻って確認
→ 高額商品・BtoB寄り
"""
def scenario_C():
access_count = np.random.poisson(2.5, DAYS)
time_per_access = stable_gamma(12.0, k=12)
access_time = clip(access_count * time_per_access)
unique_items = clip(
access_count * np.linspace(0.7, 0.5, DAYS)
+ np.random.normal(0, 0.4, DAYS)
).astype(int)
return access_time, access_count, unique_items
"""
3. 購入しない場合の典型シナリオ
シナリオD:情報収集のみ
指標 挙動
総時間 低〜中
回数 低
ユニーク商品数 高
解釈
相場確認・調査目的
他サイトで購入
"""
def scenario_D():
access_count = np.random.poisson(1.0, DAYS)
time_per_access = stable_gamma(6.0, k=10)
access_time = clip(access_count * time_per_access)
unique_items = clip(
access_count * 1.2 + np.random.normal(0, 0.6, DAYS)
).astype(int)
return access_time, access_count, unique_items
"""
シナリオE:迷走型(決めきれない)
指標 挙動
総時間 中程度
回数 中〜高
ユニーク商品数 高止まり
解釈
比較はするが候補が絞れない
購入障壁(価格・不安)
"""
def scenario_E():
access_count = np.random.poisson(2.0, DAYS)
time_per_access = np.random.gamma(1.8, 5.0, DAYS)
access_time = clip(access_count * time_per_access)
unique_items = clip(
access_count * 1.0 + np.random.normal(0, 0.5, DAYS)
).astype(int)
return access_time, access_count, unique_items
"""
シナリオF:一度見て終わり
指標 挙動
総時間 低
回数 1〜数回
ユニーク商品数 1
解釈
流入はあるが関心が浅い
"""
def scenario_F():
access_count = np.zeros(DAYS, dtype=int)
spike_day = np.random.randint(0, 10)
access_count[spike_day] = np.random.randint(1, 3)
time_per_access = np.random.gamma(2.0, 4.0, DAYS)
access_time = clip(access_count * time_per_access)
unique_items = clip(
access_count * 1.0
).astype(int)
return access_time, access_count, unique_items
def build_user_df(user_id, scenario_func, label):
access_time, access_count, unique_items = scenario_func()
return pd.DataFrame({
"user_id": user_id,
"day": DAY_INDEX,
"access_time": np.round(access_time, 1),
"access_count": access_count,
"unique_items": unique_items,
"label": label
})
def revisit_purchase():
# 期間インデックス
phase1 = np.arange(0, 20) # 初回探索
phase2 = np.arange(20, 45) # 空白
phase3 = np.arange(45, 60) # 再訪
access_count = np.zeros(DAYS)
access_time = np.zeros(DAYS)
unique_items = np.zeros(DAYS)
# 初回探索:広く浅く
access_count[phase1] = np.random.poisson(1.5, len(phase1))
time_per_access = stable_gamma(6.0, k=8, size=len(phase1))
access_time[phase1] = access_count[phase1] * time_per_access
unique_items[phase1] = (
access_count[phase1] * 1.1
+ np.random.normal(0, 0.5, len(phase1))
)
# 空白期間:ほぼゼロ
# (すでにゼロ初期化済み)
# 再訪:同じ商品を深く見る(収束)
access_count[phase3] = np.random.poisson(2.0, len(phase3))
time_per_access = stable_gamma(12.0, k=12, size=len(phase3))
access_time[phase3] = access_count[phase3] * time_per_access
unique_items[phase3] = (
access_count[phase3] * 0.4
+ np.random.normal(0, 0.3, len(phase3))
)
return (
access_time.clip(0),
access_count.astype(int),
unique_items.clip(0).astype(int)
)
def each_fig_plot(scenario,df_all,nu_of_person):
ac_time = []
ac_count = []
uni_items = []
for i in range(nu_of_person):
ac_time.append(df_all[df_all['user_id']==f"{scenario}_{i}"][["day","access_time"]].sort_values('day'))
ac_count.append(df_all[df_all['user_id']==f"{scenario}_{i}"][["day","access_count"]].sort_values('day'))
uni_items.append(df_all[df_all['user_id']==f"{scenario}_{i}"][["day","unique_items"]].sort_values('day'))
plt.figure()
plt.suptitle(f'scenario {scenario}')
plt.subplot(3,1,1)
plt.title('access time')
for plot_df in ac_time:
plt.plot(plot_df["day"],plot_df["access_time"])
plt.plot(DAY_INDEX,df_all[df_all['user_id'].str.contains(scenario)][["day","access_time"]].groupby(by="day").mean().sort_values("day")["access_time"],"k-*")
plt.xlabel('day')
plt.subplot(3,1,2)
plt.title('access count')
for plot_df in ac_count:
plt.plot(plot_df["day"],plot_df["access_count"])
plt.plot(DAY_INDEX,df_all[df_all['user_id'].str.contains(scenario)][["day","access_count"]].groupby(by="day").mean().sort_values("day")["access_count"],"k-*")
plt.xlabel('day')
plt.subplot(3,1,3)
plt.title('unique items')
for plot_df in uni_items:
plt.plot(plot_df["day"],plot_df["unique_items"])
plt.plot(DAY_INDEX,df_all[df_all['user_id'].str.contains(scenario)][["day","unique_items"]].groupby(by="day").mean().sort_values("day")["unique_items"],"k-*")
plt.xlabel('day')
plt.tight_layout()
pass
def get_list_per_id(df_all):
result_list = []
for a_user_id in sorted(pd.unique(df_all['user_id'])):
result_list.append(df_all[df_all['user_id']==a_user_id].sort_values('day'))
return result_list
def main():
dfs = []
person_per = 50
for i in range(person_per):
dfs.append(build_user_df(f"A_{i}", scenario_A, label=1))
dfs.append(build_user_df(f"B_{i}", scenario_B, label=1))
dfs.append(build_user_df(f"C_{i}", scenario_C, label=1))
dfs.append(build_user_df(f"D_{i}", scenario_D, label=0))
dfs.append(build_user_df(f"E_{i}", scenario_E, label=0))
dfs.append(build_user_df(f"F_{i}", scenario_F, label=0))
dfs.append(build_user_df(f"G_{i}", revisit_purchase, label=1))
df_all = pd.concat(dfs, ignore_index=True)
#"""
each_fig_plot("A",df_all,person_per)
each_fig_plot("B",df_all,person_per)
each_fig_plot("C",df_all,person_per)
each_fig_plot("D",df_all,person_per)
each_fig_plot("E",df_all,person_per)
each_fig_plot("F",df_all,person_per)
each_fig_plot("G",df_all,person_per)
plt.show()
#"""
# ノイズ低減の為1週間平均を取得する
window_size = 7
list_per_id = get_list_per_id(df_all)
for per_id_df in list_per_id:
per_id_df['roll_ac_time'] = per_id_df['access_time'].rolling(window_size).mean()
per_id_df['roll_diff_ac_time'] = per_id_df['roll_ac_time'].diff()
"""
# 基底作成の為のデータ調査
G_mean_ac_time = df_all[df_all['user_id'].str.contains('G')][["day","access_time"]].groupby(by="day").mean().sort_values("day")["access_time"]
plt.figure()
plt.plot(DAY_INDEX,G_mean_ac_time)
plt.xlabel('day')
plt.show()
#"""
# 基底作成
base = np.zeros(len(DAY_INDEX)-window_size,dtype=np.float64)
base[14-window_size:16-window_size] = 5
base[59-window_size:] = 20
bedcmm_points = []
user_ids = []
for per_id_df in list_per_id:
data = np.array(per_id_df['roll_ac_time'],dtype=np.float64)[window_size:]
user_ids.append(per_id_df['user_id'].iloc[0])
bedcmm_points.append(bedcmm.pattern_1d(data,base)[0])
threshould = 0.8
result_df = pd.DataFrame({'user_id':user_ids,'bedcmm_point':bedcmm_points,'revisit_flag':0})
result_df.loc[result_df['bedcmm_point'] > threshould,['revisit_flag']] = 1
result_df.to_csv('test_result.csv')
tpr = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('G')] == 1)/sum(result_df['user_id'].str.contains('G'))
print(f'tpr:{tpr}')
fpr_A = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('A')] == 1)/sum(result_df['user_id'].str.contains('A'))
fpr_B = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('B')] == 1)/sum(result_df['user_id'].str.contains('B'))
fpr_C = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('C')] == 1)/sum(result_df['user_id'].str.contains('C'))
fpr_D = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('D')] == 1)/sum(result_df['user_id'].str.contains('D'))
fpr_E = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('E')] == 1)/sum(result_df['user_id'].str.contains('E'))
fpr_F = sum(result_df['revisit_flag'][result_df['user_id'].str.contains('F')] == 1)/sum(result_df['user_id'].str.contains('F'))
print(f"fpr A:{fpr_A},fpr B:{fpr_B},fpr C:{fpr_C},fpr D:{fpr_D},fpr E:{fpr_E},fpr F:{fpr_F}")
if __name__ == '__main__':
main()
コードは GitHub に置いてあります:
さいごに
無駄に長くなってしまいましたが、データ解析は難しいですね。
パターン抽出ですが、こんな使い方を想定しています。
普通の相関と比較した方がいいのですが、シミュレーションで長くなってしまったので割愛します。