はじめに
カラオケの採点って、必ずしも歌が上手いと高いわけでもなく、独特な指標となっていますよね。今のままでも競技として良いものと言えば良いものなんですが、ちょっとした不満もあるかと思います。
特に「やさしく歌ったときに点数が下がる」という経験をしたことはないでしょうか。抑揚がない事が原因とされることが多いようですが、別の原因もあるように思えます。
自分の特許手法をカラオケアプリなどのピッチ検出に応用でメリットが出ないか検討していたのですが(ピッチ検出アルゴリズムpYINに特許技術で挑戦してみた:歌声と環境ノイズの対応)、その違和感の原因の一つが思い当たったので、記事にしたいと思います。
人間の歌声には吐息が混じる
世の中で広く使われえる手法のpYINと呼ばれる手法と、自分の特許手法を比較したときに、歌声の始まりに差がでました。自分の特許手法では、音の始まりを間違えて高い音と検出する傾向になりました。
(自己相関系やFT系の手法もありそうですが代表的なpYINとの比較を行っています。)
ここは、ピッチ検出において難しい課題とされるのですが、そこには理由があります。
人の歌声には、吐息が混ざっていています。
音声合成の分野では、吐息成分が人間らしさに寄与することが知られています。
吐息の部分の音程ってあるようでないようなもんですよね~。
ちゃんと言うと、吐息はノイズに近く、周波数帯域が広いため、高周波を誤検出してもおかしくはない、という事ですね。
ピッチ検出アルゴリズムの多くは、音が一定の周期を持つことを前提としています。しかし吐息が多く含まれる音声は、周期的な成分よりもノイズ的な成分が増えるため、この前提が崩れます。その結果、本来の音程とは異なる周波数を検出してしまうことがあります。
人っぽく歌うほど機械には認識されづらくなります。
吐息を高い音と間違えてもそれってあながち間違えでもなくない?
とか思ってしまいました。
吐息成分には高周波成分が多く含まれるため、それを高い音として検出してしまうのは、アルゴリズムとしては自然な挙動とも言えます。
従来手法では、前後の音を見ながら吐息の中の音程まである程度推定します。
従来手法では、前後のフレームとの整合性を考慮することで、吐息を含む区間でも音程を補完するような処理が行われています。
従来手法の評価は、よいと思うのですが、吐息部分は吐息部分として評価をした方が、良い気がします。
各メーカ工夫していると思うので、音程評価の信頼度が落ちるので、吐息も把握できていて、すでに評価にされているかもしれませんが、カラオケの採点の違和感の中の理由の一つではないでしょうか。
データ
0.3秒かけてホワイトノイズから一定の音になるように信号を混ぜていった場合のシミュレーションデータを示します。
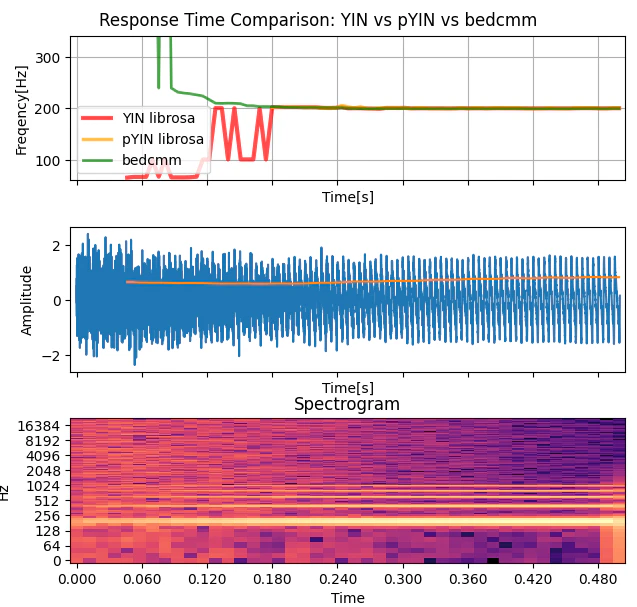
ノイズ成分が多い区間では周波数成分が広がり、明確なピークが現れにくくなっています。この状態ではピッチ検出アルゴリズムは安定した周期を見つけることができず、誤検出や不安定な推定が発生します。
※FTの結果が見やすいように見えますが、低音の音程検出精度の問題で、pYINなどの手法がつかわれます。
自分のつたない歌声だと、提案手法が高音に間違えるのがはっきり出るのですが、シミュレーションデータのみの公開で許してください。
おわりに
自分の特許手法は、インパルスノイズに強いというもっとエンタメ的な用途ではなく、工業的な用途で押しています。もしかしたら、エンタメ用途でも使えるかもしれませんが(本当は使いたいところです)。
こちらの記事(ピッチ検出アルゴリズムpYINに特許技術で挑戦してみた:歌声と環境ノイズの対応)も、よろしくお願いします。