はじめに
XとThreadsをどちらも使っていて投稿が出てくるアルゴリズムが違う事をひしひしと感じています。
Xは、バズりを生むためになるべく共感するような投稿が表示されるように感じていて、Threadsは、意見の食い違いがあってもトピックのみを合わせて表示される感覚がしています。
精神衛生上はXの方がいい気がしますが、意見の交流を求めるならThreadsの方がいい、気がします。
ただ、Threadsもヘイトになっていてあまりいい意見交換みませんがね。
上記のような仮定に基づいて、どちらのプラットフォームが栄えるのかシミュレーションしてみたので投稿したいと思います。
モデルの設計
LLMに聞きながら適当に調整して作りました。
ユーザの定義
- 多次元意見ベクトル: 各ユーザーは「政治」「技術」「食文化(ヴィーガンへの賛否など)」などのトピックについて、$0.0$(保守的/否定的)から$1.0$(進歩的/肯定的)の価値観を持っています。
- 承認欲求のフィードバック: Like(承認)をもらうほど発信数が増え、自分の意見に対する確信(極端化)が強まります。
- ユーザは、post、like、blockの動作をしその様子をシミュレーションします。
動作のモデル化
-
共感とLike(指数関数的モデル):意見が近いほど、指数関数的に大きなLike(承認)が発生します。指数型Likeモデル共感は線形ではなく、意見が極めて近い時に爆発的に発生します。$$Like = e^{-\frac{dist^2}{\sigma^2}}$$このガウス分布型の計算により、「少しのズレが熱量の低下を招く」SNSのリアルを再現しました)
-
閾値の範囲内では、議論と揺らぎ(ランダム・ウォーク)が起きます。:意見が少し違う場合、歩み寄るか反発するかは確率(50%)で決まります。SNSの「その日の気分」による揺らぎを再現しました。
-
ブロック機能(情報の遮断):意見の距離が一定以上($0.85$ 以上)離れると、その二人は二度と出会わなくなります。
-
postは、likeが増えた場合と議論が生まれた場合に、増加するような仕組みにしました。
XモデルとThreadsモデルの違い
- X型(エコーチェンバー型): 3つのトピックすべてを総合して「自分と最も価値観が近い人」を優先的に表示します。
- Threads型(ランダム・トピック型): 3つのうち「たまたま1つだけ」共通点がある人を表示します
シミュレーション結果
同調や議論を生む閾値を$0.1$、$0.3$、$0.5$と変更して、結果を比較してみました。
閾値が低いほど自分に近い意見しか興味がなくなるという事で、高いほど興味がない話にも影響を受けるという事です。
閾値0.1の時
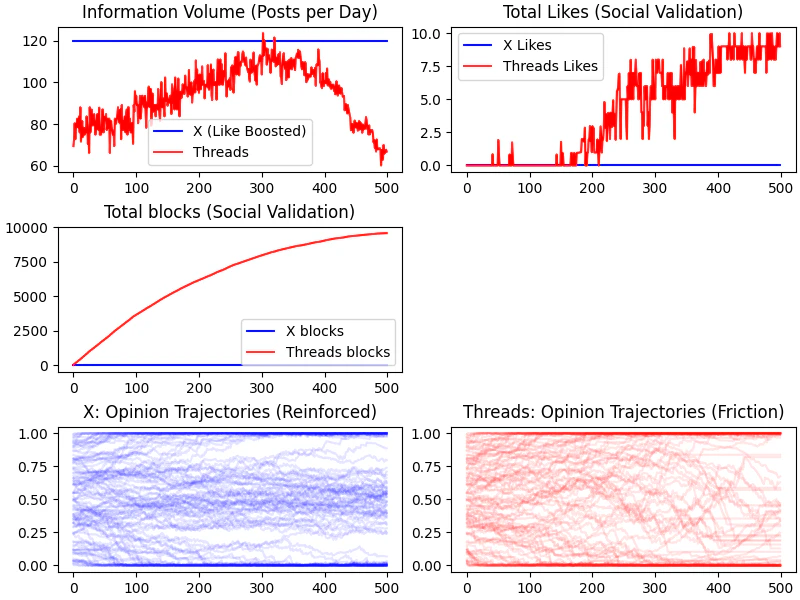
あまり他人の投稿に興味がないので、全体的にpostやlikeの数字が低くなります。
Xにlikeが全然つかないのも面白いですね。
Threadsのブロック数のみ順調に伸びていきます。
結果から見ると、現実から遠いシミュレーション結果となってしまいました。
関心の幅は意外と広いようですね。
閾値0.3の時
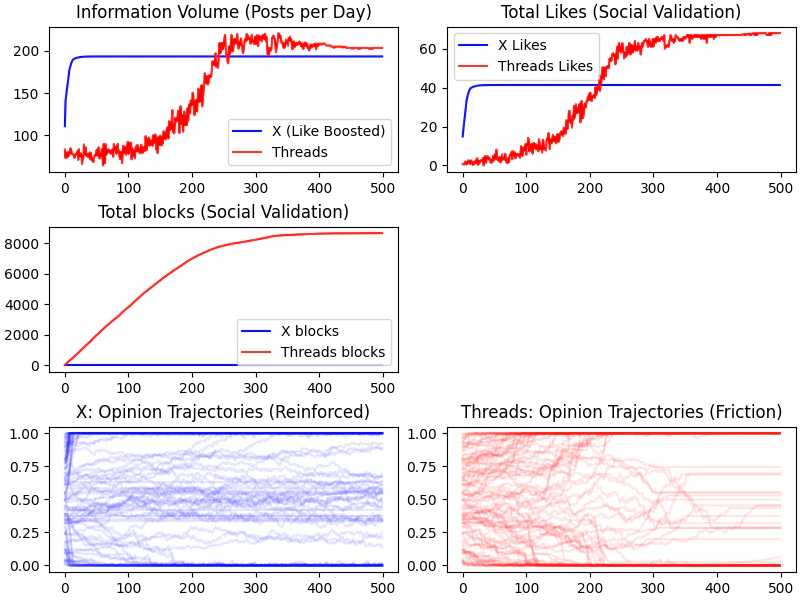
このくらいの関心度が一番現実的な、気がします。
ポスト数は、最初は、Xの方が早く多くなりますが、徐々にThreadsの方が多くなります。Threadsの方が最終的には栄えるというシミュレーション結果ですね。
しかし、面白いのは意見の分断は、Threadsの方があるんですね。
議論するが故に意見が分離していくようです。(まぁ、そういうシミュレーションしてるんですけどね。)
Xの方は、興味のない投稿は見なくなるので、分断が放置されずに意見が残る傾向にあるようです。
閾値0.5の時
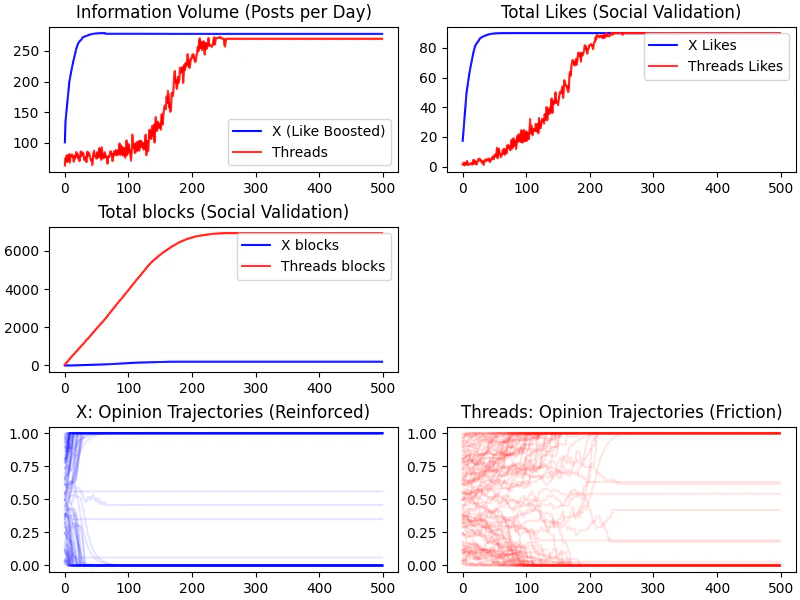
現状より人が多くのポストに関心を持つパターンです。
post数やlike数を見ると最初は、Xの方が多いですが、最終的にはあまり変わらなくなりますね。ブロック数はひたすらThreadsの方が多いですが。
意見の分断具合を見ると、Xでは意見の分断が非常に早く生まれるようです。
パラメータによって変わるのは面白い結果ですね。
まとめ
現実的なシミュレーション結果を見ると、時間をかけてThreadsの方が少しだけ活性化しそうです。
Xは、意見の衝突が生まれないため、postやlikeが伸び悩む傾向にあるようです。
意外な結果としては、適度な興味範囲をユーザが持っていれば、Xを使用する方が意見の分断は生まれにくいという事もわかりました。
そもそものモデリングが意見の分断を生みやすいモデルではあるので、一概には言えませんが。
最後に
XとThreads両方使ってみて感じた差異をモデル化してシミュレーションする事によって、どちらのSNSが栄えるか判定してみて、Threadsの方が有利かなという結論を得ました。
意見の分断が進むのは、根本的に議論ができない事に原因があるように感じます。
このモデルが、合わなくなった方が、いい気がしますね。
興味のある人は、パラメータ弄って遊んでみてください。
別のモデル化案も大歓迎です。
プログラム
import numpy as np
import matplotlib.pyplot as plt
# --- パラメータ ---
NUM_AGENTS = 100
ITERATIONS = 500
CONFIRMATION_BIAS = 0.3 # 同調・反発の境界線
REPULSION_FACTOR = 0.04
BLOCK_THRESHOLD = 0.85
LEARNING_RATE = 0.08
NUM_OF_TOPICS = 5
np.random.seed(42)
# 初期意見:一様に分布
agents_init = np.random.rand(NUM_AGENTS, NUM_OF_TOPICS)
# 初期意見:0.5付近(中立)に分布
#agents_init = np.random.normal(0.5, 0.1, (NUM_AGENTS, NUM_OF_TOPICS))
def simulate_final(initial_state, algo_type='X'):
agents = initial_state.copy()
block_matrix = np.zeros((NUM_AGENTS, NUM_AGENTS), dtype=bool)
history = {'opinions': [], 'posts': [], 'blocks': [], 'likes': []}
last_likes = np.zeros(NUM_AGENTS)
for _ in range(ITERATIONS):
history['opinions'].append(agents.copy())
daily_posts = 0
daily_likes = 0
current_likes = np.zeros(NUM_AGENTS)
for i in range(NUM_AGENTS):
visible_indices = np.where(~block_matrix[i])[0]
visible_indices = visible_indices[visible_indices != i]
if len(visible_indices) == 0: continue
# マッチング
current_visible = agents[visible_indices]
if algo_type == 'X':
# 全体の傾向から似た意見を選ぶ
dists = np.linalg.norm(current_visible - agents[i], axis=1)
target_idx = visible_indices[np.argsort(dists)[0]]
else:
# ランダムにトピックを選択
chosen_topic = np.random.choice(np.arange(NUM_OF_TOPICS))
topic_dists = np.abs(current_visible[:, chosen_topic] - agents[i, chosen_topic])
target_idx = visible_indices[np.argsort(topic_dists)[0]]
target_op = agents[target_idx]
dist = np.linalg.norm(agents[i] - target_op)
# --- 案B: 指数関数的なLikeモデル ---
# 距離が離れると急激にLikeが減る(ガウス分布型)
# ここでは閾値に関わらず「近さ」そのものを評価
like_on_this_post = np.exp(- (dist**2) / (0.2**2))
if dist < CONFIRMATION_BIAS:
# 同調ゾーン
current_likes[target_idx] += like_on_this_post
daily_likes += like_on_this_post
# 意見遷移:承認による「端っこへの加速」
direction_to_edge = np.sign(agents[i] - 0.5)
agents[i] += LEARNING_RATE * (target_op - agents[i])
agents[i] += 0.05 * direction_to_edge * last_likes[i]
# ポスト数:承認(last_likes)が次の発信のガソリンになる
daily_posts += 1.0 + (last_likes[i] * 2.0)
else:
# 反発・ブロックゾーン
if dist > BLOCK_THRESHOLD:
block_matrix[i, target_idx] = True
daily_posts += 0.1
else:
# --- 確率的な議論の処理 ---
# 50%の確率で相手に歩み寄り(0.01)、50%で反発(0.04)
if np.random.rand() < 0.5:
# 議論による歩み寄り(同調よりは弱め)
agents[i] += 0.01 * (target_op - agents[i])
else:
# 反発による硬化
direction = agents[i] - target_op
agents[i] += REPULSION_FACTOR * direction
daily_posts += 1.2 # 議論(レスバ)中はポスト数が伸びる
agents[i] = np.clip(agents[i], 0, 1)
last_likes = current_likes.copy()
history['posts'].append(daily_posts)
history['likes'].append(daily_likes)
history['blocks'].append(block_matrix.sum())
return np.array(history['opinions']), history
# 実行
op_x, stat_x = simulate_final(agents_init, 'X')
op_t, stat_t = simulate_final(agents_init, 'Threads')
# --- 可視化 ---
fig, axes = plt.subplots(3, 2, figsize=(8,6),constrained_layout=True)
# 1. ポスト数(盛り上がり)の推移
axes[0, 0].plot(stat_x['posts'], label="X (Like Boosted)", color='blue')
axes[0, 0].plot(stat_t['posts'], label="Threads", color='red')
axes[0, 0].set_title("Information Volume (Posts per Day)")
axes[0, 0].legend()
# 2. Like総数の推移
axes[0, 1].plot(stat_x['likes'], label="X Likes", color='blue')
axes[0, 1].plot(stat_t['likes'], label="Threads Likes", color='red')
axes[0, 1].set_title("Total Likes (Social Validation)")
axes[0, 1].legend()
# 3. block総数の推移
axes[1, 0].plot(stat_x['blocks'], label="X blocks", color='blue')
axes[1, 0].plot(stat_t['blocks'], label="Threads blocks", color='red')
axes[1, 0].set_title("Total blocks (Social Validation)")
axes[1, 0].legend()
axes[1,1].axis('off')
# 4. 意見の遷移(X)
for i in range(NUM_AGENTS):
axes[2, 0].plot(op_x[:, i, 0], color='blue', alpha=0.1)
axes[2, 0].set_title(f"X: Opinion Trajectories (Reinforced)")
# 4. 意見の遷移(Threads)
for i in range(NUM_AGENTS):
axes[2, 1].plot(op_t[:, i, 0], color='red', alpha=0.1)
axes[2, 1].set_title(f"Threads: Opinion Trajectories (Friction)")
#fig.tight_layout()
plt.show()
コードは GitHub に置いてあります: