GoogleスプレッドシートのIMPORTXML関数を使ってGoogle Financeから日本株の配当利回りを取得します。
今回は[2914]日本たばこ産業(JT)の配当利回りを取得してみます。

IMPORTXML関数について
IMPORTXML関数の詳細は過去の記事をご参照頂ければ幸いです。
Google Finance から日本株の証券情報を取得する
IMPORTXML関数の引数
IMPORTXML関数の引数に指定する URL と XPath を確認します。
URL
[2914]日本たばこ産業(JT)の証券情報は以下URLで確認できます。
https://www.google.com/finance/quote/2914:TYO?hl=ja
XPath
ブラウザから対象URLにアクセスして配当利回りのXPathを確認します。
今回もGoogle ChromeでXPathを確認してみます。
1. 開発ツールを表示する
"F12"キーを押して開発ツール(Chrome DevTools)を開きます。
(ブラウザ画面上の何も無いところを右クリックして"検証"を選択しても大丈夫です。)
2. Webサイトのソースから、配当利回りの位置を確認する
配当利回りにマウスカーソルを合わせて右クリックして"検証"を選択します。
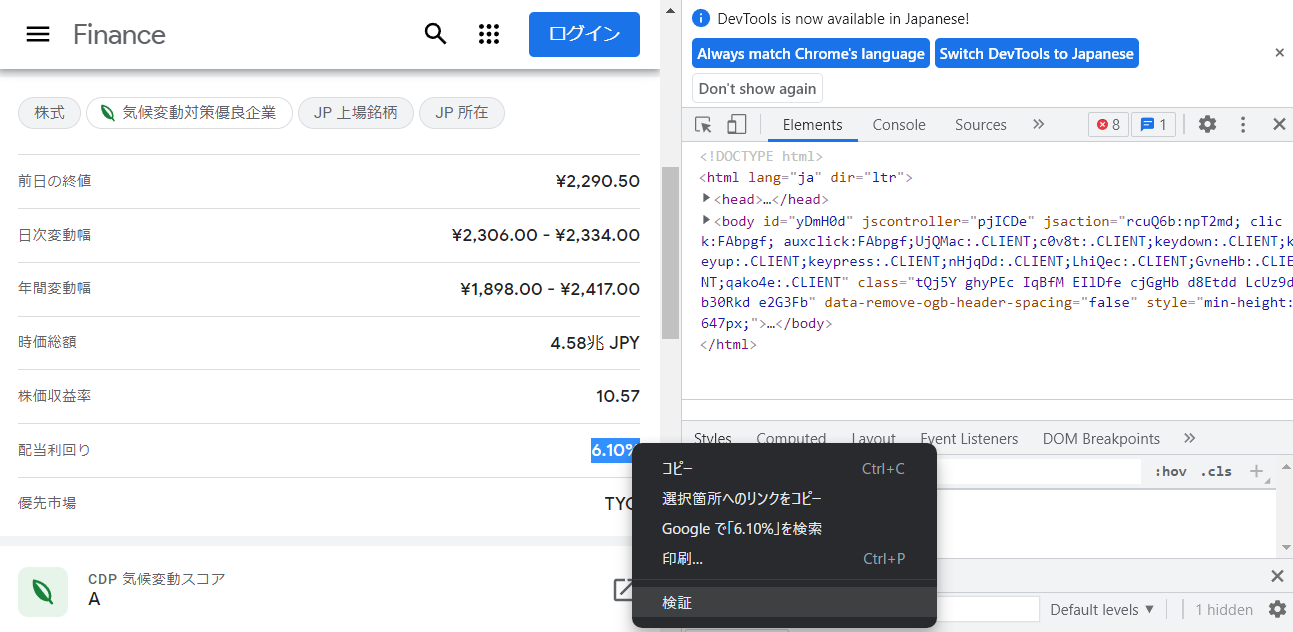
すると、開発ツール側のWebサイトのソースがハイライトされます。
これが配当利回りの位置になります。
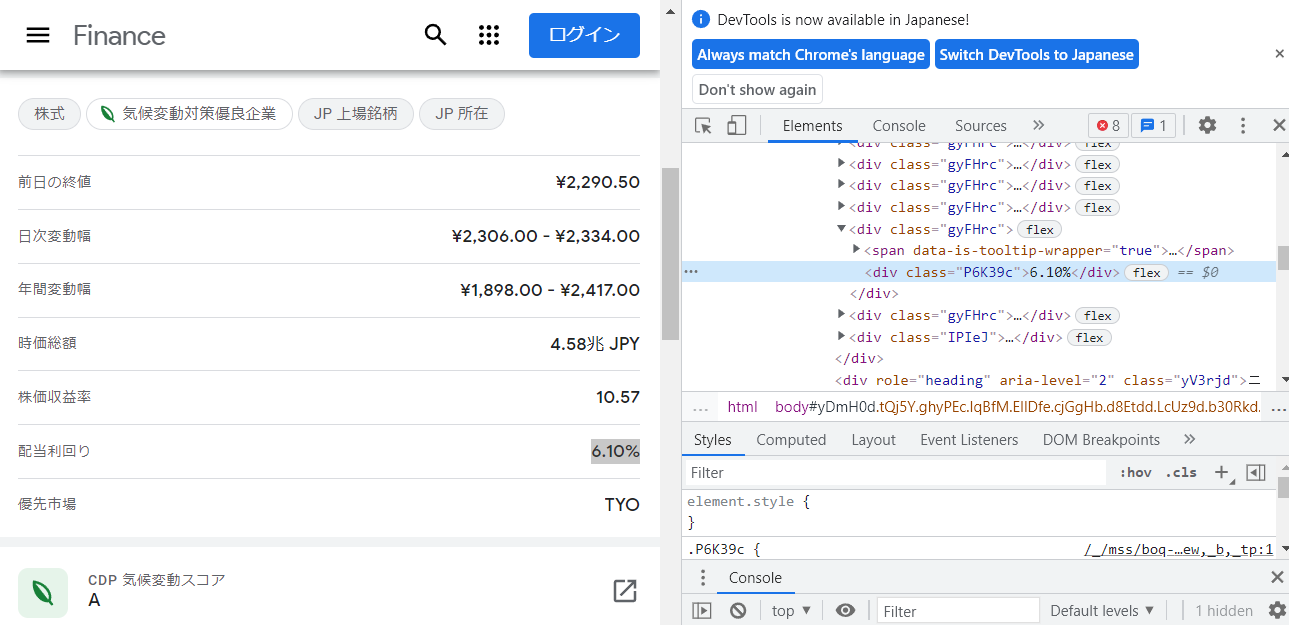
3. 配当利回りのXPathを確認する
ハイライトされた部分を右クリックして Copy -> Copy XPath の順に選択します。
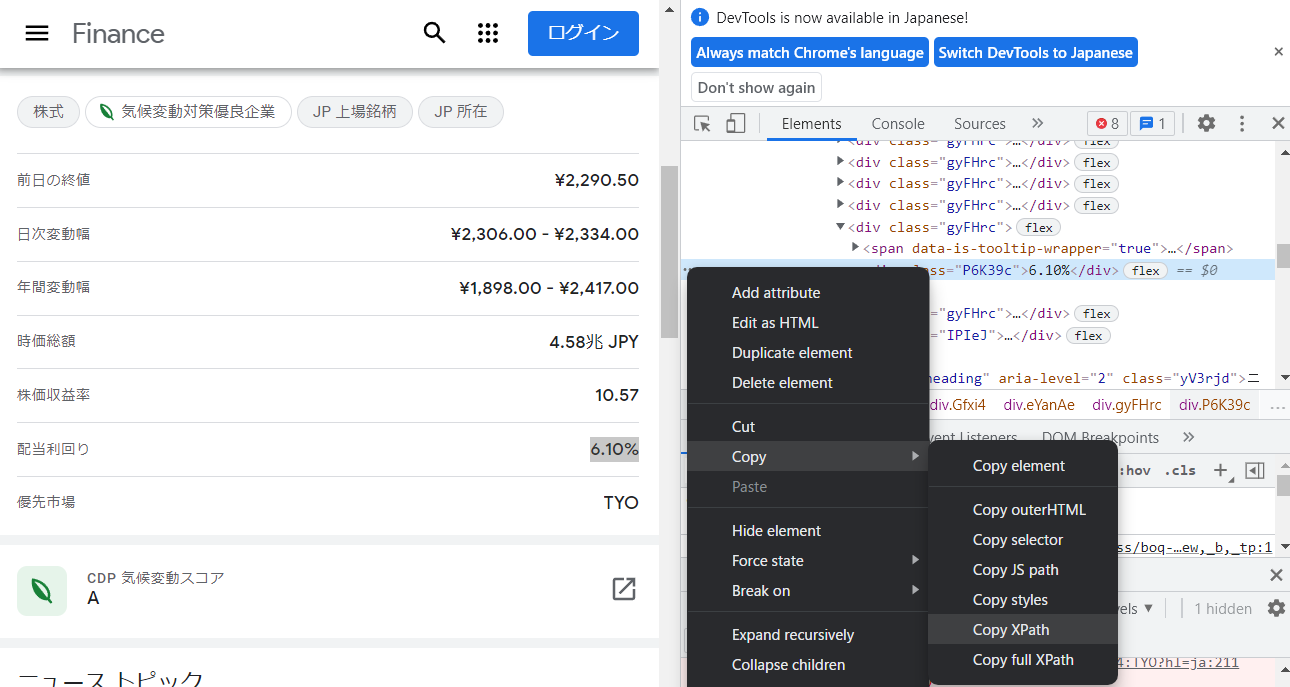
クリップボードにXPathがコピーされたので、一旦テキストファイル等にXPathを貼り付けてみます。
//*[@id="yDmH0d"]/c-wiz/div/div[4]/div/div/main/div[2]/div[2]/div[7]/div
先頭の//*[@id="yDmH0d"]に含まれるダブルクォーテーションは、IMPORTXML関数に入れる際には文字列として認識させる必要があるため、ダブルクォーテーションを2つ続けて入力します。
//*[@id="yDmH0d"]
↓
//*[@id=""yDmH0d""]
【参考】
グーグルスプレッドシートの関数で『ダブルクォーテーション(”)』を文字列として認識させる方法
IMPORTXML関数の引数を整理すると以下の通りになります。
| 引数 | 値 |
|---|---|
| 第一引数 - URL | "https://www.google.com/finance/quote/2914:TYO?hl=ja" |
| 第二引数 - XPath クエリ | "//*[@id=""yDmH0d""]/c-wiz/div/div[4]/div/div/main/div[2]/div[2]/div[7]/div" |
スプレッドシートにIMPORTXML関数を入力
IMPORTXML関数に引数を指定してスプレッドシートに入力します。
=IMPORTXML("https://www.google.com/finance/quote/2914:TYO?hl=ja","//\*[@id="yDmH0d"]/c-wiz/div/div[4]/div/div/main/div[2]/div[2]/div[7]/div")
エラーになりました。
XPathが深過ぎて正しく認識できないのでは?と勝手に想像しています。

エラーの解消方法
XPathを編集してエラーを解消します。
先ほどハイライトされた部分を改めて確認します。
<div class="P6K39c">6.10%</div>
となっているので、第二引数のXPathを//*[@class=""P6K39c""]に置き換えます。
=IMPORTXML("https://www.google.com/finance/quote/2914:TYO?hl=ja","//\*[@class=""P6K39c""]")
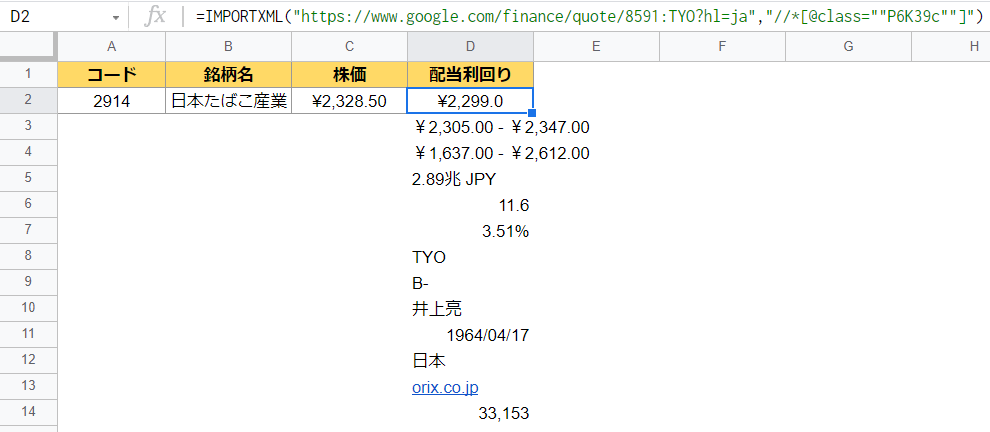
エラーは解消しましたが、配当利回りは取得できていません。
//*[@class=""P6K39c""]が複数あるようです。
もう少し上の階層div class="eYanAe"から見ていきます。
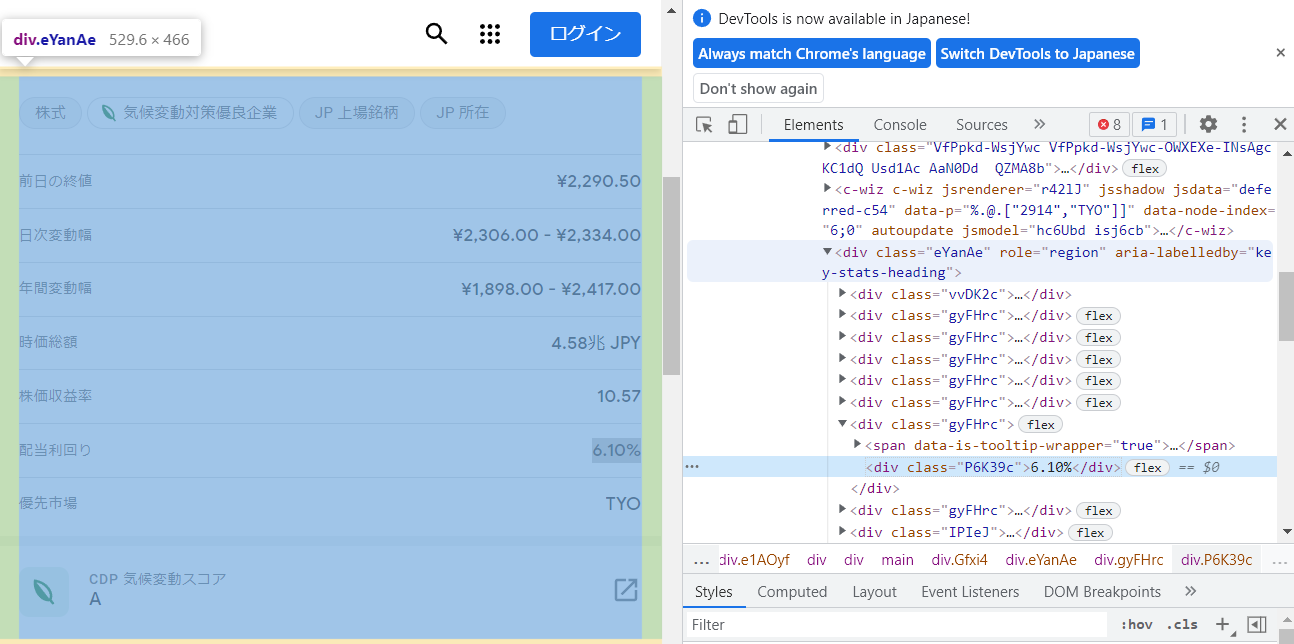
XPathを書き出してみます。
<div class="eYanAe" role="region" aria-labelledby="key-stats-heading"> ※XPath://*[@class="eYanAe"]
<div class="vvDK2c">...</div> ※XPath://*[@class="eYanAe"]/div[1]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[2]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[3]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[4]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[5]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[6]
<div class="gyFHrc">...</div> ※XPath://*[@class="eYanAe"]/div[7]
<div class="P6K39c">6.10%</div> ※XPath://*[@class="eYanAe"]/div[7]/div
XPathをIMPORTXML関数に入れてみます。
※ダブルクォーテーションを2つ続けることを忘れずに。
=IMPORTXML("https://www.google.com/finance/quote/2914:TYO?hl=ja","//\*[@class=""eYanAe""]/div[7]/div")
[2914]日本たばこ産業(JT)の配当利回りを取得できました。

APPENDIX
配当金を出していない銘柄の場合、配当利回りは-と表示されます。
複数銘柄の情報を一覧表示させる場合、-ではなく0.00%とした方が都合が良い場合があるかと思います。
そういった場合、以下のようにSUBSTITUTE関数とTEXT関数も組み合わせて-を0.00%に置換することができます。
=SUBSTITUTE(IMPORTXML("https://www.google.com/finance/quote/2914:TYO?hl=ja","//\*[@class=""eYanAe""]/div[7]/div"),"-",TEXT(0,"0.00%"))
以上、最後まで読んでいただき、ありがとうございました。