毎回新しいアカウントを作るとき、よくこんなメッセージに邪魔されます。
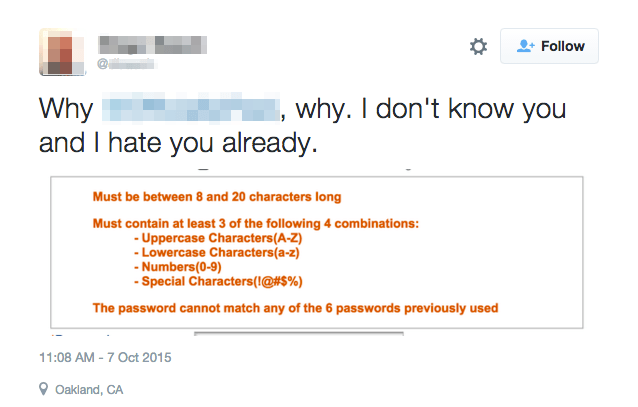
では、いいパスワードは一体どんなやつなのかい?これから、Data Campから勉強したNIST パスワード規則をPythonでやってみる。日本語が母語ではないので、説明が辛い時は英語にしますので、許してください。
The repository is at https://github.com/Bing-Violet/Bad-passwords-and-the-NIST-guidelines with the data sets available.
There're loads of criteria for a good password. It's hard to define what is a good password. However, the National Institute of Standards and Technology (NIST) gives you a guide not to make a bad password from the cyber-security perspective.
# Importing the pandas module
import pandas as pd
# Loading in datasets/users.csv
users = pd.read_csv("datasets/users.csv")
# Printing out how many users we've got
print(users.count())
# Taking a look at the 12 first users
print(users.head(12))
Passwords should not be too short
# Calculating the lengths of users' passwords
users['length'] = users['password'].str.len()
# Flagging the users with too short passwords
users['too_short'] = users['length'] < 8
# Counting and printing the number of users with too short passwords
print(users['too_short'].count())
# Taking a look at the 12 first rows
print(users.head(12))
Passwords shouldn't be Common passwords
Common passwords and combinations should be avoided as they could be expected. General common passwords include but not restricted to:
- Passwords obtained from previous breach corpuses.
- Dictionary words.
- Repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).
- Context-specific words, such as the name of the service, the username, and derivatives thereof.
# Reading in the top 10000 passwords
common_passwords = pd.read_csv('datasets/10_million_password_list_top_10000.txt', header=None, squeeze=True)
# Taking a look at the top 20
print(common_passwords.head(20))
We fetch the common password list, then find out all the passwords fall in this category.
# Flagging the users with passwords that are common passwords
users['common_password'] = users['password'].isin(common_passwords)
# Counting and printing the number of users using common passwords
print(users['common_password'].count())
# Taking a look at the 12 first rows
print(users['common_password'].head(12))
Passwords should not be common passwords
By the same token, passwords shouldn't be common words. This may not apply to local Japanese people, as the list we fetch here only contains popular English dictionary words.
# Reading in a list of the 10000 most common words
words = pd.read_csv('datasets/google-10000-english.txt', header=None, squeeze=True)
# Flagging the users with passwords that are common words
users['common_word'] = users['password'].str.lower().isin(words)
# Counting and printing the number of users using common words as passwords
print(users['common_word'].count())
# Taking a look at the 12 first rows
print(users['common_word'].head(12))
Passwords should not be your name
We should also flag passwords that contain users' names as a bad password practice.
# Extracting first and last names into their own columns
users['first_name'] = users['user_name'].str.extract(r'(\w+)', expand = False)
users['last_name'] = users['user_name'].str.extract(r'(\w+$)', expand = False)
# Flagging the users with passwords that matches their names
users['uses_name'] = (users['password']==(users['first_name']))|(users['password']==(users['last_name']))
# Counting and printing the number of users using names as passwords
print(users['uses_name'].count())
# Taking a look at the 12 first rows
print(users['uses_name'].head(12))
Passwords should not be repetitive
### Flagging the users with passwords with >= 4 repeats
users['too_many_repeats'] = users['password'].str.contains(r'(.)\1\1\1')
# Taking a look at the users with too many repeats
print(users['too_many_repeats'])
All together now!
Now let's combine the criteria listed above and filter out all the bad passwords.
# Flagging all passwords that are bad
users['bad_password'] = (
users['too_short'] |
users['common_password'] |
users['common_word'] |
users['user_name'] |
users['too_many_repeats'])
# Counting and printing the number of bad passwords
print((users['bad_password']==True).count())
# Looking at the first 25 bad passwords
print(users['bad_password'].head(25))
This is how we can filter out the bad passwords in a data set. And similar approaches can be adopted for your current database if you already have some users and want to improve the security for their accounts. ![]()