この記事は自然言語処理を使って、小説の言葉使いを分析する実験である。パイプラインを作って、言葉の頻度を簡単に分析する。
I recently encountered this amazing Netflix series Anne with an E and was amazed by the story. It's hard to find high-quality movies that pass the Bechdel Test. The story is extremely empowering for girls. Inspired by Hugo Bowne-Anderson from Data Camp, I decided to apply my knowledge in web-scraping and basic Natural Language Processing knowledge to analyze the word frequency in the original book ANNE OF GREEN GABLES.

In this project, I'll build a simple pipeline to visualize and analyze the word frequency in ANNE OF GREEN GABLES.
from bs4 import BeautifulSoup
import requests
import nltk
If this is your first time using nltk, don't forget to include the following line to install nltk data as we'll need to use the stopwords file later to remove all the stopwords in English.
nltk.download()
Simply run this line in your program and a GUI window will pop up. Follow the instructions to install all the data. The installation procedure would take a couple of minutes. After the installation, you'll be good to go.
r = requests.get(‘http://www.gutenberg.org/files/45/45-h/45-h.htm')
r.encoding = ‘utf-8’
html = r.text
print(html[0:100])
Now we can fetch the html version of the book and print the first 100 characters to see if it's right. Before extracting all the text from the html document, we'll need to create a BeautifulSoup object.
soup = BeautifulSoup(html)
text = soup.get_text()
print(html[10000:12000])
Then we'll use nltk and Regex to tokenize the text into words:
tokenizer = nltk.tokenize.RegexpTokenizer('\w+')
tokens = tokenizer.tokenize(text)
print(tokens[:8])
Now we can turn all the words into lower-case for later frequency distribution calculation since it is case-sensitive.
words = []
for word in tokens:
words.append(word.lower())
print(words[:8])
One last step before we can visualize the distribution of frequency of words is to get rid of all the stop words in words list.
sw = nltk.corpus.stopwords.words(‘english’)
print(sw[:8])
words_ns = []
for word in words:
if word not in sw:
words_ns.append(word)
print(words_ns[:5])
Finally, let's visualize the top dist plot and see what are the top 25 frequent words in the book.
%matplotlib inline
freqdist = nltk.FreqDist(words_ns)
freqdist.plot(25)
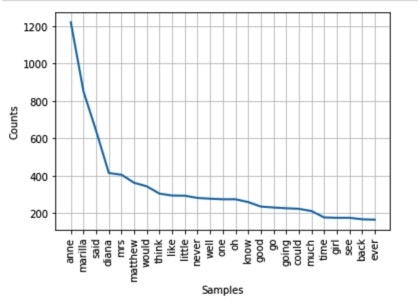
Now we can see the top two supporting characters in the fiction are two females: Marilla and Diana. It's not surprising the name of the Netflix series renamed it as Anne With an ‘E’ as it is a name repeated over 1200 times.