「ひらがな、カタカナ、ローマ字」それぞれで検索しても全て同じようにヒットさせたい
SupabaseでPGroongaのExtentionが追加されたので、タイトルにもある通りの検索機能を実装していきます。
目次
- pgroongaの基本的な使い方
- 「ひらがな、カタカナ、ローマ字」でヒットするようにインデックスを再設定
1. pgroongaの基本的な使い方
PGROONGAの有効化
- SupabaseのExtentionから
PGROONGAを検索します
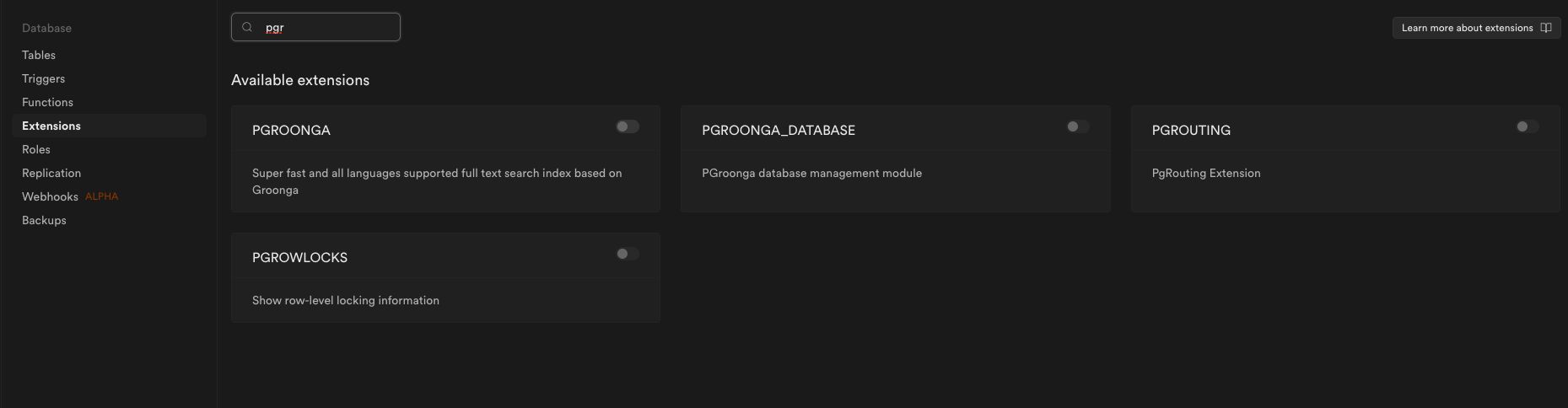
ここでPGROONGAが表示されない場合は、
左メニューのProject Settings(歯車マーク) > Pause project
でDBを再起動してください
2. PGROONGAをONにします
データの用意
- テーブル作成
CREATE TABLE game (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
title text NOT NULL
);
- インデックス作成
CREATE INDEX pgroonga_game_search_index ON game USING pgroonga (title);
- データ投入
INSERT INTO game(title) VALUES('スーパーマリオUSA'),('スーパーマリオブラザーズ'),('ドクターマリオ'),('マリオオープンゴルフ'),
('スーパーマリオランド'),('マリオのピクロス'),('マリオゴルフGB'),('マリオテニスGB'),
('スーパーマリオ ヨッシーアイランド'),('スーパーマリオRPG'),('スーパーマリオカート'),
('ドクターマリオ ワールド'),('マリオカート ツアー'),('ペーパーマリオ オリガミキング'),('スーパーマリオ 3Dワールド + フューリーワールド'),
('マリオゴルフ スーパーラッシュ'),('マリオパーティ スーパースターズ'),('マリオストライカーズ: バトルリーグ'),('マリオ+ラビッツ ギャラクシーバトル');
動作確認
pgroongaチュートリアルによると
pgroongaのインデックスを使った全文検索をするには&@,&@~を使用します。
以下のクエリを実行しスーパーがつくデータのみヒットすることを確認します。
select * from test_game where title &@ 'スーパー';
出力:
| id | title |
| -- | -------------------------- |
| 1 | スーパーマリオUSA |
| 2 | スーパーマリオブラザーズ |
| 5 | スーパーマリオランド |
| 9 | スーパーマリオ ヨッシーアイランド |
| 10 | スーパーマリオRPG |
| 11 | スーパーマリオカート |
| 15 | スーパーマリオ 3Dワールド + フューリーワールド |
| 16 | マリオゴルフ スーパーラッシュ |
| 17 | マリオパーティ スーパースターズ |
いい感じに出力できてそうですね。
インデックスの使用確認
全文検索はインデックスを使用して高速に検索することができます。
EXPLAIN ANALYZE VERBOSEクエリでインデックスが使用されていることを確認しましょう
EXPLAIN ANALYZE VERBOSE SELECT * FROM game WHERE title &@ 'スーパー';
出力:
| QUERY PLAN |
| ---------------------------------------------------------------------------------------------------------- |
| Seq Scan on public.game (cost=0.00..25.88 rows=1 width=36) (actual time=0.053..0.107 rows=9 loops=1) |
| Output: id, title |
| Filter: (game.title &@ 'スーパー'::text) |
| Rows Removed by Filter: 10 |
| Query Identifier: -234713111216255585 |
| Planning Time: 14.876 ms |
| Execution Time: 0.273 ms |
・・・おや?
Seq Scanで検索されていますね。。。
原因は不明ですが、どうやらSupabase上では&@ではなく、後方互換の@@クエリを使用する必要がありそうです。
※原因がわかる方いらしたら教えていただけると幸いです...
ここでIndex Scanにならなかった方は、PGROONGAエクステンションを作成するときに、対象テーブルのスキーマ(デフォルトだとextensions)を指定する必要があるみたいです。
エクステンションを再設定します。
PGROONGAエクステンションの再設定
-
インデックスの削除
DROP INDEX pgroonga_game_search_index; -
PGROONGAエクステンションを一度無効化し、再度有効化する。
このとき、スキーマをpublicする。
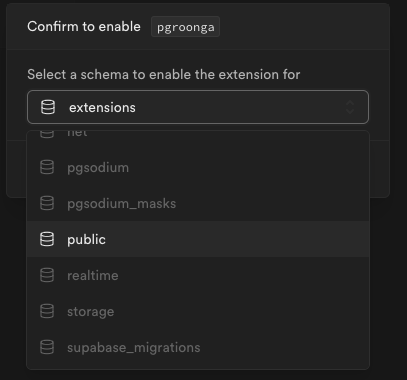
↓
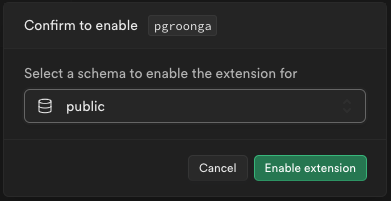
↓ Schema: publicとなっていることを確認
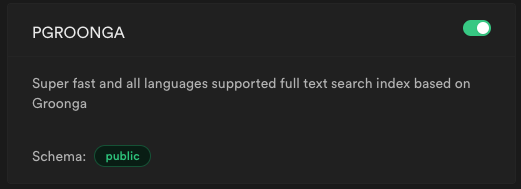
クエリ再実行
EXPLAIN ANALYZE VERBOSE SELECT * FROM game WHERE title &@ 'スーパー';
出力:
| QUERY PLAN |
| -------------------------------------------------------------------------------------------------------------------------------------------------- |
| Index Scan using pgroonga_game_search_index on public.game (cost=0.00..8.93 rows=13 width=36) (actual time=0.669..0.680 rows=9 loops=1) |
| Output: id, title |
| Index Cond: (game.title &@ 'スーパー'::text) |
| Query Identifier: -788482272138655105 |
| Planning Time: 15.636 ms |
| Execution Time: 0.862 ms |
Index Scan using pgroonga_game_search_indexという出力結果が出ているので正しくインデックスが使用されていますね。
コストを見比べても分かる通り、インデックスが使用されている方が高速です。
Seq Scan: cost=0.00..25.88
Index Scan: cost=0.00..8.93
基本的な準備ができた上で本題です。
ひらがなやローマ字で検索するとどうでしょう
SELECT * FROM game WHERE title &@ 'すーぱー';
SELECT * FROM game WHERE title &@ 'su-pa-';
こちらは何もヒットしません。
これらでもヒットするように設定を変更していきます。
2. 「ひらがな、カタカナ、ローマ字」でヒットするようにインデックスを再設定
インデックス設定の見直し
pgroongaのインデックス設定を見直し、ひらがなやローマ字でもヒットするようにします。
pgroongaには以下の3つの要素が設定できます。
- ノーマライザー:text型とvarchar型の等価性をカスタマイズするモジュールです。
- トークナイザー:キーワードの抽出方法をカスタマイズするモジュールです。
- トークンフィルター:トークナイザーが抽出したキーワードをフィルターするモジュールです。
[参考URL]https://pgroonga.github.io/ja/reference/create-index-using-pgroonga.html
インデックス設定
トークナイザーとトークンフィルターを組み合わせてみます
- インデックス再作成
DROP INDEX pgroonga_game_search_index;
CREATE INDEX pgroonga_game_search_index ON game USING pgroonga (title)
WITH (
tokenizer = 'TokenBigramSplitSymbolAlphaDigit',
token_filters = 'TokenFilterNFKC100("unify_to_romaji", true, "unify_kana", true, "unify_hyphen_and_prolonged_sound_mark", true)'
);
トークナイザーのTokenBigramSplitSymbolAlphaDigitはバイグラム処理を行います。
つまり、データが2文字づつに分割されたものがインデックスされます。
例:スーパーマリオUSA
スー,ーパ,パー,ーマ,マリ,リオ,オU,US,SA
トークンフィルターのTokenFilterNFKC100はUnicode 10.0用のUnicode NFKC(Normalization Form Compatibility Composition)を使ってテキストを正規化するフィルターです。
ここで使っているオプションは以下の三つです。
-
unify_to_romaji: ひらがなとカタカナをローマ字に正規化する -
unify_kana: 全角ひらがな、全角カタカナ、半角カタカナの文字を同一視する -
unify_hyphen_and_prolonged_sound_mark: ハイフンと長音記号を"-" (U+002D HYPHEN-MINUS)に正規化する
以上によって、トークナイザーで分割されたトークンが、トークンフィルターで正規化されて、それが検索対象文字列となります。
実際にひらがなやローマ字でヒットするか試します
- ひらがな
SELECT * FROM game WHERE title &@ 'すーぱー';
| id | title |
| -- | ---------------------------------- |
| 1 | スーパーマリオUSA |
| 2 | スーパーマリオブラザーズ |
| 5 | スーパーマリオランド |
| 9 | スーパーマリオ ヨッシーアイランド |
| 10 | スーパーマリオRPG |
| 11 | スーパーマリオカート |
| 15 | スーパーマリオ 3Dワールド + フューリーワールド |
| 16 | マリオゴルフ スーパーラッシュ |
| 17 | マリオパーティ スーパースターズ |
ヒットしました!
- ローマ字
SELECT * FROM game WHERE title &@ 'su-pa-';
結果なし
あれ?ローマ字では引っかかりませんね。
ここでノーマライザーも追加します
DROP INDEX pgroonga_game_search_index;
CREATE INDEX pgroonga_game_search_index ON game USING pgroonga (title)
WITH (
normalizers = 'NormalizerNFKC100("unify_to_romaji", true, "unify_hyphen_and_prolonged_sound_mark", true)',
tokenizer = 'TokenBigramSplitSymbolAlphaDigit',
token_filters = 'TokenFilterNFKC100("unify_to_romaji", true, "unify_kana", true, "unify_hyphen_and_prolonged_sound_mark", true)'
);
normalizers = 'NormalizerNFKC100("unify_to_romaji", true, "unify_hyphen_and_prolonged_sound_mark", true)',この一文を追加しました。
ノーマライザーはテーブルの内容を指定のノーマライザーによって正規化します。
正規化する内容は以下の二つです。どちらもトークンフィルターで指定したものと同じで処理内容も一緒です。
unify_to_romajiunify_hyphen_and_prolonged_sound_mark
これによりローマ字でもヒットするようになるはずです。
SELECT * FROM game WHERE title &@ 'su-pa-';
| id | title |
| -- | ---------------------------------- |
| 1 | スーパーマリオUSA |
| 2 | スーパーマリオブラザーズ |
| 5 | スーパーマリオランド |
| 9 | スーパーマリオ ヨッシーアイランド |
| 10 | スーパーマリオRPG |
| 11 | スーパーマリオカート |
| 15 | スーパーマリオ 3Dワールド + フューリーワールド |
| 16 | マリオゴルフ スーパーラッシュ |
| 17 | マリオパーティ スーパースターズ |
問題なくヒットしました。
pgroongaにおけるトークナイザーとノーマライザーにの違いについて
pgroongaにおけるトークナイザーとノーマライザーにの違いについて、正直公式ドキュメントを見てもはっきりと分からないので自分なりの考察を残しておきます。
トークナイザーは以下によると、インデックス構築時とクエリ検索時に正規化されるようです。
- インデックス構築時
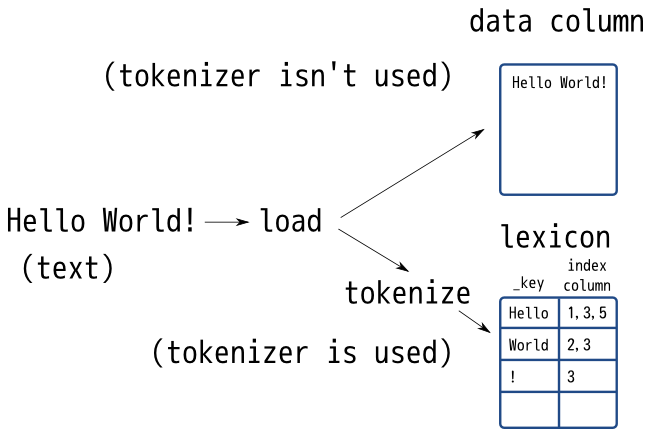
- クエリ検索時
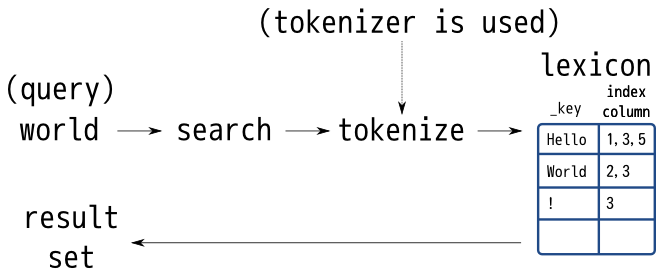
[トークナイザー概要]https://groonga.org/ja/docs/reference/tokenizer/summary.html
ノーマライザーは以下の引用によるとテーブルに関連づけて正規化を行なっているようです。
これはテキストをトークナイズするときとテーブルのキーを保存するときに使われます。
...
ノーマライザーモジュールはテーブルに関連付いています。テーブルは0個か1個のノーマライザーモジュールを持つことができます
[ノーマライザー概要]https://groonga.org/ja/docs/reference/normalizers.html
トークナイザーは検索側、ノーマライザーはテーブル側の正規化と考えればいい?
今回紹介した方法も検索側とテーブル側に同じような正規化を行なったからと考えると納得がいくが、きっと勘違いなんだろうな。。。
それぞれハッキリと役割が分かれていることが自分の中で整理できました!
ノーマライザー: 文を正規化する役割。(スーパー -> su-pa-)
トークナイザー: 文を分割(トークン化)する役割。 (su-pa- -> su,u-,-p,pa,a-)
上記を踏まえると、
今回のケースではノーマライズした後にトークナイズすることでやりたいことが満たせているのでtoken_filtersは必要無いですね!
最後に
今回のご紹介した全文検索は私たちが開発しているサービス 「U-GAME」 に組み込んでいます。
今まで遊んできたゲームの記録とレビューを残せるサービスです!
- U-GAME: https://u-game.vercel.app/
レビュー評価に関しては、他にない評価基準を設けており、ネガティブなイメージを払拭した評価のみが選択可能です。
これにより、今まで遊んできたゲームの思い出たちが他の人のレビューによってマイナスなイメージへと変換されません笑
ぜひ試してみてください!
以上です。
参考
pgroongaチュートリアル: https://pgroonga.github.io/ja/tutorial/
pgroongaリファレンスマニュアル: https://pgroonga.github.io/ja/reference/
supabaseにpgroonga設定: https://zenn.dev/hmatsu47/articles/supabase_pgroonga_flutter
トークナイザー概要: https://groonga.org/ja/docs/reference/tokenizer/summary.html
ノーマライザー概要: https://groonga.org/ja/docs/reference/normalizers.html