はじめに
以前書いた「BluemixのNatural Language Classifierで文章を分類してみる(日本語)」の最後に、**「NLCは多段・多重に組み合わせることで様々な可能性を秘めていると思う。」**と書いたが、そのまま放り投げっぱなしだったので、少しフォローしようと思う。
具体的には、NLCの多段化と、あいさつクラスの追加だ。
NLCを使ってみて思ったこと
NLCで入力文章をクラス分けできる。入力文章も分け方も明確ならば、単純にクラス分けできると思うけど、実際使ってみると思ったようにクラス分けできずに困ったことはないだろうか。
それは主にトレーニングデータの準備に起因することが多いのだと思う。つまり、クラス分けした全てのクラスについて、そのクラスをユニークに認識できるようなトレーニングデータが十分に集まっていないのである。ちゃんとたくさんデータを集めれば精度よく判定してくれるはずだ。
とは言え、他の全てのクラスをにらんだ上で、対象のクラスが一意に決まるようにデータを収集していくって、とっても大変ということで、これを少しでも楽にする方法が無いか考えてみた。
NLCの判定ロジック(想像)
NLCの判定が悪くなる原因を考える前に、NLCがどんな原理でクラス判定をしているのか想像してみた。ここの動きは外部にはわからないブラックボックスなので、一般的なクラス分けの手法や、実際に使ってみた経験から、こんな感じじゃないのかなーというのを書き出してみた。間違っているかもしれない。
以下は筆者の想像です。違っているかもしれませんがあしからず。
NLCは、入力されたデータを形態素解析して単語と品詞を取得しているだろう。そしてそれらの単語でベクトル空間を作る。この際に、単語のジャンル(天候関係の言葉とか気温関係の言葉とか)も考慮してベクトル化しているかもしれない(NLCのデモのページにある「台風」はトレーニングデータにないけど天候クラスに分類できるという文言から推測すると)。
トレーニングが完了し、ある文章が入力されたら、NLCはその文章を作成したベクトル空間にマッピングして、どのクラスの空間にマッピングされるかによってクラス判定しているのではないだろうか。となると、クラスを定義する際の文章内の単語の出現の有無や回数が、クラス判定に影響を与えていると考えられる。
という(妄想の)動きを前提に、どういう場合にどういうことが起きるか整理してみた。
1) 1クラスあたりのトレーニングデータが少ない場合
トレーニングデータは例文みたいなものだけど、それが少ない場合、トレーニングデータには無い単語が入ってくるとお手上げだ。最低でもそのクラスであることが特定できるように、そのクラスで使われる専門用語は全て網羅するような例文をトレーニングデータとして用意する必要がある。
(これが超大変なんだけど、こればかりはどうあがいても避けられない模様・・・)
2) クラスを代表するキーワードが他のクラスにもある場合
あるクラスと別のクラスで、トレーニングデータの中に同じ単語が使われていると、意図しないクラスに分類されてしまうことがしばしばある。それがそれなりに関連のある分野のクラスであればいいが、全く関連がないクラスだとげんなりしてしまう。この場合は、共通していない方の単語がどのクラスに属するかでクラスが決まるが、回答のConfidenceは高くはないだろう。例えば、文章中に単語が2つあって、1つだけ共通していたら、共通していない方の単語のクラスに振り分けられる確率は、単純計算で五分五分になる。実際はもっと複雑な計算が含まれているだろうし、単語も3つ4つになればそれだけ片方に重みがかかるだろうが、それでもConfidenceが低くなるのは容易に想像できる。
(単語が増えれば増えるほど、今度はさらに別のクラスと重複する可能性も増えていくのも注意)
3) 文章が短すぎてクラスを特定できない場合
これはもうどうしようもない。人間の会話でも、「昨日のアレ、面白かったよね」とか言われてもよくわからない。対象を特定できる情報が「昨日」しかないからだ。これでわかったらエスパーだ。「昨日のドラマ、面白かったよね」と言われれば、ドラマなんだなということはわかるが、どのドラマかわからない。「昨日の下町ロケット、面白かったよね」と言われれば、下町ロケットだということはわかるので、このあたりからようやく対応できるようになる。だが、もう少し詳しく、「昨日の下町ロケットで、佃社長が教授に啖呵きった場面が面白かったよね」と言われると、かなり特定できるだろう。
このように、入力文からクラスを判断しようとしたときに、文章が短すぎるとどうしようもないのである。この場合はそもそもNLCに入れて判断させることすらあきらめるというのもひとつの手であろう。もちろん、応答としては「もうちょっと長い文章を」とか「もう少し詳しく質問して」とか「詳しい状況を教えて」とか伝えることも忘れてはいけない。
4) トレーニングデータに無いクラスの質問をしたのに、Confidenceが高く出てくる
これはのConfidenceは相対評価であるというのに起因していると思われる。**NLCの出力を見ると、全クラスのConfidenceを足し合わせると1.0(100%)になる。**そのため、つまり、実際には関連は低くても、他のクラスがより関連が低ければ、相対的に高いConfidenceになる可能性もある。
本当は無関係な質問のため、ほとんどのクラスにはひっかからないが、何か1単語だけでも既存のクラスにひっかかるようだと、そのクラスを回答する可能性が十分にあるし、実際そうなってしまったこともある。
解決策その1 NLCの多段化
正直、1)と3)はどうしようもないと思う。1)は頑張るしかないし、3)もNLCに入れる前に何か手をうつというのが解決策になるのだろう。
でも2)は何とかなると思う。それが**「NLCの多段化」**である。
多段化しないとこうなる
NLCを多段化しないとどうなるだろうか。1つのClassifierで全てをまかなおうと頑張ったらこうなるのではなかろうか。

クラスがたくさんありすぎて、人間だってどれを選べばいいか困ってしまう。NLCだって図で示すように、いろんなクラスが低いConfidenceで返ってきて、どれが正解か判断できないことが起こると予想される。
NLCの多段化
で、多段化したほうがいいよね、という話だが、要するに、同じ文章を解析するにしても、まず大項目として大体のジャンルを絞り、中項目に絞り、さらに小項目に絞り・・・と、ある程度特定できるところまで絞るのである。ヘルプセンターに電話をした場合も、「○○の相談は1を、××の相談は2を押してください」と言われる。あれと同じ理屈だ。違うのは1つ絞るごとに次の入力を聞くのではなく、1つ絞ったら絞ったものに対して同じ文章を入力して再度絞っていくところ。つまりユーザーにとっては1回質問しただけで、最後まで絞込みをしてくれる。
文章だと分かりづらいので絵にしてみたのがこちら。
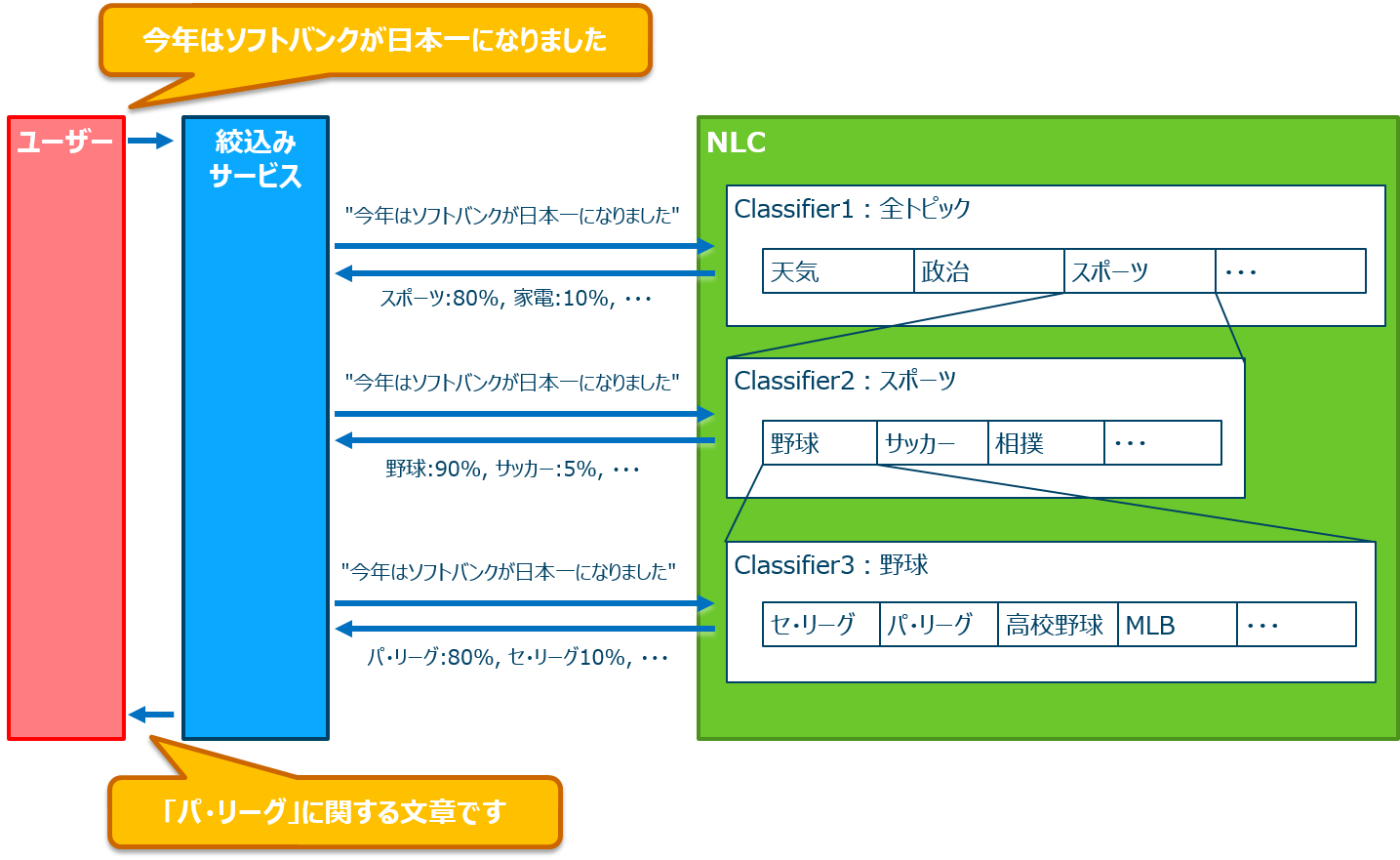
左端のユーザーがした質問を、真ん中の青いサービスがNLCに何度か問いかけて対象を絞る。この例では、1回目の問い合わせで全トピックの中から「スポーツ」であることを絞り込み、次にスポーツのClassifierに対して同じ質問を投げると「野球」であることがわかる。さらに野球のClassifierに対して同じ質問を投げると「パ・リーグ」の話題であることがわかった。というシナリオだ。
これのいいところは、「阪神」と入れたときに「阪神電鉄」なのか「阪神百貨店」なのか「阪神タイガース」なのかわかりづらいが、他の用語で早い段階でスポーツに絞り込めれば、その後は阪神電鉄や阪神百貨店のクラスの要素に引きずられないということだ。少しずつ対称ドメインを絞っていくことで、考慮しないといけない用語の範囲も絞り込んでいく。そうすれば人間の頭でも把握できる範囲まで絞っていけるのではないだろうか。
このユーザーとNLCの仲介をする人を、センスのかけらもないが**「絞込みサービス」**とした。Curatorとか言いたかったけど、Watsonの他のサービスや用語と区別できなくなりそうだったので、安直に絞込みサービスとした。
解決策その2 あいさつクラスの追加
あと問題になるのは、**「あいさつ」**だ。「こんにちは」とか「ありがとう」とか、人間だったら言うし、人間だったら自然に受け答えする。あいさつを考慮していないNLCにこれを入れると、どこかのクラスに無理矢理割り振ってしまうからあまりよろしくないだろう。
では、NLCの前にあいさつされたらNLCに入れずにあいさつで返すというロジックを追加したらどうだろう。これに対する私の答えはナンセンスだ。やってもいいのだが実は意味がない。というのも、**入ってきたのがあいさつかどうか、どうやって判断するのだろうか?**判断ロジックにあいさつの種類をひたすら書いていく?色々なバリエーションがあるがどうなのだろうか?結局のところ、あいさつかどうかを調べるためにNLCを使うのが一番なのではないだろうか。
あいさつ判定用のClassifierを作る必要はない
あいさつ判定用のClassifierを作る必要はないというのが私の考え。というのも、実際に実装しようかなと思ったときに、NLCはトータル100%で返答する問題のため、あいさつクラスだけをデータとして投入しても意味がない。他のクラスがあってはじめてNLCの意味を成す。**「あいさつでひっかけるクラス」と「次の質問に通すクラス」**が必要ということだ。
では**「次の質問に通すクラス」をどう作るか。それを考えたら、結局は通常の質問分類に使うNLCに入れ込むのが現実的**なのである。Classifierが1つだけならそこに入れればいいし、多段化するならば1段目にあいさつクラスを入れて、あいさつはそこで網にかけてしまうのがいいだろう。
あいさつはどう用意すべきなの?
あいさつはパターンが決まっているし、そんなに変わるものでもない。なので、**「日本語あいさつのテンプレート」**を作れば再利用可能だと思う。私が作ってみたテンプレートはこちら。
おはよう,朝のあいさつ
お早う,朝のあいさつ
おはようございます,朝のあいさつ
お早うございます,朝のあいさつ
おはよー,朝のあいさつ
おはよ,朝のあいさつ
こんにちは,昼のあいさつ
こんにちわ,昼のあいさつ
こんちは,昼のあいさつ
こんちわ,昼のあいさつ
今日は,昼のあいさつ
今日わ,昼のあいさつ
こんばんは,夜のあいさつ
こんばんわ,夜のあいさつ
今晩は,夜のあいさつ
今晩わ,夜のあいさつ
ばんは,夜のあいさつ
ばんわ,夜のあいさつ
おばんです,夜のあいさつ
お晩です,夜のあいさつ
はじめまして,出会いのあいさつ
初めまして,出会いのあいさつ
よろしくおねがいします,お願い
よろしくお願いします,お願い
宜しくお願いします,お願い
よろしく,お願い
ヨロシク,お願い
4649,お願い
夜露死苦,お願い
さようなら,別れのあいさつ
さよなら,別れのあいさつ
ばいばい,別れのあいさつ
バイバイ,別れのあいさつ
おやすみなさい,寝る時のあいさつ
おやすみ,寝る時のあいさつ
ありがとう,お礼
サンキュー,お礼
39,お礼
Thank you,お礼
あり,お礼
ゴチになります,お礼
ごちになります,お礼
いただきます,食事前のあいさつ
頂きます,食事前のあいさつ
いただきマンモス,食事前のあいさつ
ごちそうさまでした,食事後のあいさつ
ご馳走様でした,食事後のあいさつ
ごちそうさま,食事後のあいさつ
ご馳走様,食事後のあいさつ
ごっそさん,食事後のあいさつ
ゴチ,食事後のあいさつ
ごち,食事後のあいさつ
分類はこんな感じにした。
| 種類(クラス) | 内容(例文) |
|---|---|
| 朝のあいさつ | おはよう、おはようございます、お早う |
| 昼のあいさつ | こんにちは、今日は |
| 夜のあいさつ | こんばんは、今晩は |
| お願い | よろしくお願いします、お願いします、お願い |
などなど。
まだまだ例文が足りないので今後パターンを拡充していく必要がある。
課題は、「おやすみ機能」とか「おはようお知らせ機能」みたいなものを検索しようとしてあいさつと間違えられるかもしれないということだ。うーん、これはどうすればよいのだろう・・・。
おわりに
今回はめちゃくちゃ長くなってしまった。2つに分けてもよかったかもしれないが面倒なので1つのままにする。NLCで遊ぶと結構楽しい。RRもいいけど難しい。NLCの方がシンプルな割に使いやすくて便利なので万人ウケしそうだ。みんなが使ってもっと便利な使い方が見つかるといいなー。
補足(2015/12/09追記)
一晩考えてみたけど、やっぱり1段目の回答は「あいさつクラス」にまとめてしまうのがいい気がしてきた。2段目にあいさつだけのClassifierを作り、そこに最初の文章を投入してあいさつの種類を分類してから応答を決める方が、汎用的でデータの更新にも強い感じがする(ちゃんと確率計算とかしたわけではなく感覚的なものですが)。