Natural Language Classifierとは?
Bluemixでは様々なWatson APIが使えるようになっているが、その中に文章を入力すると、その文章がどのような内容か分類(クラス分け=Classify)してくれるAPIである**Natural Language Classifier(NLC)**というものがある。これを使ってユーザーが入れてきた質問が果たして何に関する質問なのか分類しちゃおう、というのが今回のお話。
NLC概要
まずはNLCについて簡単に説明しよう。NLCは入力された文章の内容から、クラス分けしてくれる**分類器(Classifier)である。分類してくれるといっても何も無いところから分類はできない。分類するための材料として、どういう文章はどんなクラスか、という情報が必要だ。これをNLCではGroundTruth(GT)といったりする。RRでもGTという言葉が出てくる。いい日本語訳がなかなか無いわけだが、意味的には分類のための「基礎知識」や「前提知識」と言うとイメージが湧くだろうか。システムにとって自分の知識を形成するためのただひとつの「拠り所」**といってもいいかもしれない。
「この文章だったらこのクラスに分類してくれ」という情報をたくさん集める。多ければ多いほどよい。この情報がGTとなり、最終的にはNLCのクラス分けの精度に響いてくるのである。
以下にNLCの使い方の例を示す。
例えば、新聞から集めた文章を「天気」「政治」「スポーツ」の3つのカテゴリーに分けたとしよう。それをNLCに入力して学習させ、天気、政治、スポーツを振り分けることができる分類器(Classifier)を作ったとする。
学習が完了したNLCに対して、ある文章を入力する。NLCは文章の構造を解析し、GTとの関連度合いを計算し、どのクラスに分類されるかを返す。正確には、可能性が高い順に返す。ここで注意して欲しいのは、NLCは必ず自分が知っている何かしらのクラスに分類するということだ。つまり、3つのカテゴリーとは関係ない「芸能」の文章を入れたとしても、NLCは天気の確率何%、政治の確率何%、スポーツの確率何%という情報を返す。この確率は全て足すと100%になる。つまり、NLCは登録されているクラス以外は返せないのである。これはいいのか悪いのか。
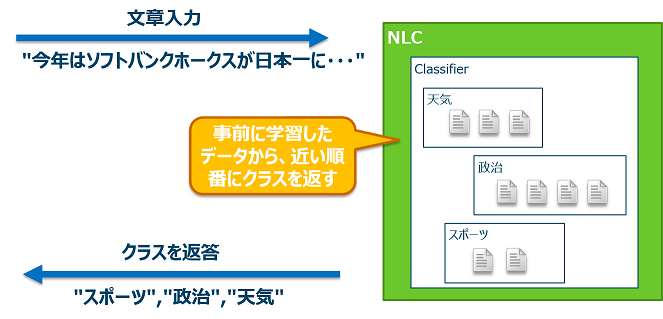
NLCの構成
前置きはこのくらいにして、早速NLCを作ってみよう。
NLCの学習用データフォーマットは単純で、CSV形式のファイルに文章とクラスをひたすら並べていくだけである。
文章1,クラスA
文章2,クラスB
文章3,クラスA
上の例だと、文章1と3はクラスAに、文章2はクラスBの文章であることを示している。
さて、このデータを作るのに、自分で頑張ってもいいが、ここではツールを作ってみたので紹介しよう。RRのトレーニングデータを生成するツールを機能拡張し、RR用のデータ(FAQ)を元にしてNLC用のCSVも生成するようにした。
# !/bin/bash
if [ $# -ne 2 ]; then
echo "Usage: $ createWatsonData.sh <FAQ.csv> <DomainName>" 1>&2
exit 1
fi
filename=$1
OUTGT=$2"-GT.csv"
OUTDOC=$2"-Doc.json"
OUTNLC=$2"-NLC.csv"
# ファイル初期化
cat /dev/null > ${OUTGT}
cat /dev/null > ${OUTDOC}
cat /dev/null > ${OUTNLC}
echo "{" >> ${OUTDOC}
CNT=0
# ループ
while read line; do
# カウンターをまわす
CNT=`expr ${CNT} + 1`
# カンマで区切る
i=`echo ${line} | cut -d ',' -f 1`
j=`echo ${line} | cut -d ',' -f 2`
# GT
echo \"${i}\",\"${CNT}\",\"4\" >> ${OUTGT}
# Doc
echo \"add\":{ \"doc\":{ \"id\":\"${CNT}\", \"body\":\"${j}\" }}, >> ${OUTDOC}
# NLC
echo ${i},$2 >> ${OUTNLC}
echo $2 ${i},$2 >> ${OUTNLC}
done < ${filename}
echo "\"commit\" : { }" >> ${OUTDOC}
echo "}" >> ${OUTDOC}
echo "TOTAL RECORD = " ${CNT}
さてこれにより、データは準備できたので、早速NLCの構成をしていこうと思う。
NLCインスタンスの作成(とトレーニング)
ここではCurlを使って構成する方法を紹介する。NLCにはサンプルアプリケーションもあり、そちらを自分のNode.js環境で稼働させると、GUIを使ってインスタンスを作成したり削除したりトレーニングしたりすることができるので、興味のある方は試してみてほしい。
インスタンスの作成にはCurlで以下のコマンドを実行する。"language"キーに設定できる値は今現在は"en"(英語)、"pt"(ポルトガル語)、"es"(スペイン語)の3つのみ。**だがここは"ja"と入れてみる。**すると、なんということだろう。日本語でトレーニングできるようになったではないか。と大げさに言うほどのことではなく、誰でも試したくなっちゃうとこですよね。
curl -k -i -u "<NLCユーザーID>":"<NLCパスワード>" -F training_data=@<トレーニング用CSVファイル> -F training_metadata='{"language":"ja","name":"<分類器名>"}' "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers"
たくさん応答が返ってくるが、ポイントは最後のJSONのところ。ここで出てくるは今後も必要になるのでちゃんとメモっておくこと。(よく出てくる「分類器」という言い方がどうもしっくりこないので、「NLC」と訳してたりします。Classifier_id → NLC-ID とか。
{
"classifier_id" : "<NLC-ID>",
"name" : "<NLC名>",
"language" : "ja",
"created" : "2015-12-03T03:11:21.513Z",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/<NLC-ID>",
"status" : "Training",
"status_description" : "The classifier instance is in its training phase, not yet ready to accept classify requests"
}
分類器のトレーニング
分類器を作成する際に読み込ませたCSVファイルを使ってトレーニングが開始されている。トレーニングの状況は、上記JSONでいえば**"status"キーの値で判断できる。これが"Training"のままだとまだトレーニング中である。トレーニングが完了すると、"status"は"Available"**に変わる。
{
"classifier_id" : "<NLC-ID>",
"name" : "<NLC名>",
"language" : "ja",
"created" : "2015-12-03T03:11:21.513Z",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/<NLC-ID>",
"status" : "Available",
"status_description" : "The classifier instance is now available and is ready to take classifier requests."
}
分類のテスト
最後にテストだ。テストはcurlでもブラウザーでもどちらからでもよい。以下はCurlで試す例。
curl -k -G -u "<NLCユーザーID>":"<NLCパスワード>" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/<NLC-ID>/classify" --data-urlencode "text=<質問文>"
例えば、iPhoneとAndroidのクラス分けをするNLCに対して「Androidのバージョンを確認する方法が知りたい」と入れたとする。
curl -k -G -u "<NLCユーザーID>":"<NLCパスワード>" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/<NLC-ID>/classify" --data-urlencode "text=Androidのバージョンを確認する方法が知りたい"
このリクエストに対する回答はこのようになった。
{
"classifier_id" : "<NLC-ID>",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/<NLC-ID>",
"text" : "Androidのバージョンを確認する方法が知りたい",
"top_class" : "Android",
"classes" : [ {
"class_name" : "Android",
"confidence" : 0.9954465033012547
}, {
"class_name" : "iPhone",
"confidence" : 0.004553496698745301
} ]
}
99%以上でAndroidであり、iPhoneである可能性は1%以下である。
おわりに
NLCは多段・多重に組み合わせることで様々な可能性を秘めていると思う。
例えば、1段目で大きくざっくりと分類し、2段目で少し詳しく、3段目で詳細にクラス分けする。具体的には、1段目で「東北」であると分類し、2段目では「宮城県」であると分類し、3段目で「仙台市」であることを分類する、などだ。作成するNLCインスタンスは多くなるが、その分紛れも少なくなり、より正確に分類が可能になるだろう。
または、並列して分類した結果を組み合わせてより精度の高い判断することもできるだろう。例えば、ある料理に関する文章を食べ物NLCに入れると「和食」が返り、食材NLCに入れると「小麦粉」が返ってきたとしよう。これらを組み合わせると「うどん」を導き出すことができる。「小麦粉」だけだったらパンやスパゲッティーかもしれないが、これに「和食」という情報が組み合わさることで、より範囲を絞っていける。
ぜひ色々な使い方を考え、そして試してみて欲しい。