TL;DR
このご時世、機械学習知らないのはアルファベットかけないのと同じ、、、
(ちなみにMySQLのクエリかけないのはひらがな書けないのと同じらしい)
それは言い過ぎかもしれないが、機械学習少しは知らないとまずい感あると感じている。
数学的に本質的に理解して、既存のツールも使いこなせるっていうのが目標!!
ちょうど、機械学習の勉強会があってメンバーが僕よりも理解度が高い方々だったので、参加することにしました。
その記録も兼ねています。
具体的にはこの本を読んでいます。
[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践(Vahid Mirjalili)
この記事の内容は「3.3章ロジスティック回帰を使ってクラスの確率を予測するモデルの構築」に対応しています。
まずは数理的に理解する。そして、実際に実装してみる。という感じで進めていこうと思います。
ちょっと数学的な内容中心かもしれない、、、
やりたいこと(とちょっと背景)
ある一つのデータ(データセット)がある時、そのデータが自分の知りたいカテゴリに分類されるのかを判定する。
ということがやりたいこと。
例えば、ある人のCT画像(データ)を見てこの人がガン患者であるかどうかを判定することを考えるとイメージができると思います。
この、CT画像を見てガン患者かどうかを判定したいときに、いくつか方法があります。
その一つにパーセプトロンを用いた分類があります。
詳しくは人工ニューロンとパーセプトロン【機械学習再勉強】を参考にしてください。
本記事をざっと見てさっぱりわからんという人はまず↑の記事を読んでから戻って来ていただけるといいかもしれないです。
パーセプトロンは、入力されたデータを閾値で分け出力結果と教師データの誤差を逐一修正していくというものです。
一方、ADALINE、ロジスティック回帰は入力されたデータを出力する前に活性化関数を通して、確率で分類の正誤の判定と、教師データとの誤差を評価します。
この誤差から重みをどんどん更新していき、最後に閾値で分類判定し出力します。
イメージ的には↓のような感じ。
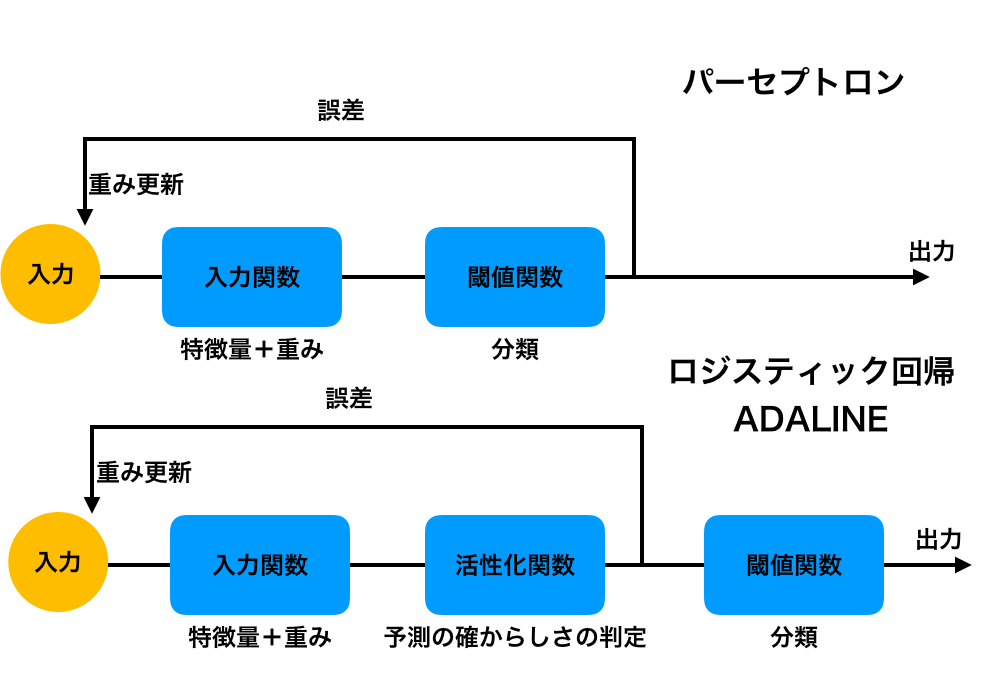
ADALINEとロジスティック回帰は本質的には活性化関数が違うだけです。
ADALINEの方は活性化関数が一番シンプルな線形モデル(直線)で、
ロジスティック回帰は後で出てくるロジスティックジグモイド関数なるものです。
活性化関数の形がどんな形かで、学習の仕方が変わるのでここが一番の肝です。
ロジスティック回帰の活性化関数
活性化関数の意味は、入力$x$、重み$w$が与えられた時に、入力が自分の知りたいクラスにどの程度の確からしさで属するかということを評価することです。
例えば、あるCT画像(入力 $x$、$w$)に対して、ガンである確率(自分の知りたいクラスに属する確率)が0.8という感じで活性化関数は確率を返して来ます。
パーセプトロンでは活性化関数を通していないので、ガンである確率が0.5より大きいものについてはガンである!と判定されていました。
つまり確率が0.6でも0.8でもとにかく0.5より高ければガン認定みたいな大雑把さがあったということです。
それに対して、活性化関数を通すと、ガンである確率が高くても、0.6と0.8では違うよねということを考慮して重みを更新されます。
ここで、一度総入力についておさらいしときます。
$x = (x_0, \cdots, x_m)^T$という$m$個の特徴量をもつ特徴量ベクトルと
$w = (w_0, \cdots, w_m)^T$という特徴量に対応した重みベクトルから総入力は
$$ z = w^T\cdot x $$
で表されました。
これは、$z = 0$という方程式が表す直線が$w$と直交するため、$w$と$x$の内積を大きくしていくような学習をしていけば、自ずと、$z = 0$が表す直線は求めるべき境界線に近づいていくよね!ということでした。詳しくはパーセプトロンの記事を見てください。わかりやすく書いてあります。
さて、活性化関数をどうするかという問題ですが、発想としては、
- 総入力が大きければ大きいほど(小さければ小さいほど)、活性化関数が返す確率が高くなる(低くなる)
- 総入力が0の時は確率0.5を返す
というのが自然でしょう。
これを満たす一つの関数としてロジット関数というものがあります。
$$\mathrm{logit}(p) = \log\frac{p}{1-p}$$
この関数は単調増加かつ確率$p=0.5$の時に0になるという便利な関数です。
こいつを総入力と対応させちゃおうという発想で、
$$\mathrm{logit}(p(y=1|x)) = z$$
とすればいい感じの判定ができるのではないかということです。
ここで、$y$はクラスを表しています。(ガンである→$y=1$,ガンでない→$y=0$).
$p(y=1|x)$というのは特徴ベクトル(CT画像)が与えられた時、$y=1$である(ガンである)確率という意味です。
アルゴリズム的には入力を与えた時にガンである確率を返して欲しいので、上の式の逆関数を求めます。
$$p(y=1|x) = \frac{1}{1+\mathrm{e}^{-z}}= \phi(z)$$
となります。
この$\phi(z)$がロジスティックシグモイド関数と言われる関数で、ロジスティック回帰における活性化関数になります。
形こんな感じ↓
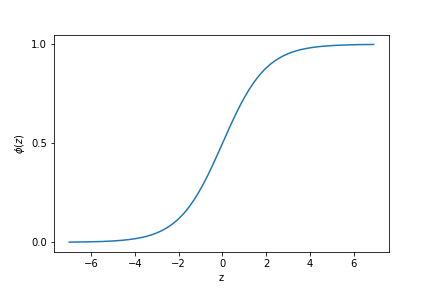
活性化関数が完全に直線だったADALINEと比べると、ある程度大きな入力があった場合は返す確率が大きくなるということでしょうか。
相対的に、あまり大きくない入力に対してはその分類判定は信じず、確率は低く出力しようという意味があるんだと思います。
重みの学習
活性化関数が表せたので、あとは重みの更新のアルゴリズムを決めちゃいましょう。
ADALINEは活性化関数が線形だったので誤差平方和をコスト関数にして、コスト関数を最小にするような重み$w$に更新していきました。
一方で、ロジスティック回帰では$p(y=1|x)=p(y=1|x, w)=$を$w$の尤度関数と見ることで、尤度を最大とするような$w$を求めてやろう!というのが重み更新の方針です。
最尤推定を使うということです。
尤度は以下のようにかけます。
$$L(w) = P(y|x,w)=\prod_{i=1}^nP(y^{(i)}|x^{(i)},w)=\prod_{i=1}^n(\phi(z^{(i)}))^{y^{(i)}}(1-\phi(z^{(i)}))^{1-y^{(i)}}$$
$n$はサンプル数で、$i$番目のサンプルの条件付き確率を掛け合わしたものが全体の確率分布になります。$i$番目のサンプルについて、$y=1$となるとき$p(y|x, w)=\phi(z)$になり、$y=0$となるとき$p(y|x, w)=1-\phi(z)$になることを考えると最左辺のような表式になります。
この表式を対数尤度に書き換えると以下のようになります。
$$l(w)=\log L(w)=\sum_{i=1}^n(y^{(i)}\log(\phi(z^{(i)})) + (1-y^{(i)})\log(1-\phi(z^{(i)})))$$
最尤推定の考えで、この尤度関数が最大になるような$w$を見つければ良いということなので、こいつの符号を反転させたやつをコスト関数にしてしまえばいいんです!
ここが結構嬉しいところ!!
というわけでコスト関数は
$$J(w)=-l(w)$$
になります。
実装
上のことを踏まえて実際にロジスティック回帰の分類器を作る。
やることとしては2次元正規分布をするグループを二つ作り、そいつらを分類する境界線を引く!というものを作ります。
データを作る
正規乱数でいい感じに分類できそうな2つのグループを作る
やってること自体はパーセプトロンの記事と同じ。
# mean座標, var, sizeの配列
dataNum = 100
group1 = [2., 5., 0.4, dataNum]
group2 = [4., 1., 1.1, dataNum]
# 二つのグループについて正規乱数で位置を決める
group1axis1Dist = np.random.normal(group1[0], group1[2], group1[3]);
group1axis2Dist = np.random.normal(group1[1], group1[2], group1[3]);
group2axis1Dist = np.random.normal(group2[0], group2[2], group2[3]);
group2axis2Dist = np.random.normal(group2[1], group2[2], group2[3]);
# 特徴量1、2のベクトル
# axis1_train, axis2_train: サンプル数 * 特徴量の個数 (200 * 2)
axis1_train = np.hstack((group1axis1Dist, group2axis1Dist));
axis2_train = np.hstack((group1axis2Dist, group2axis2Dist));
# 目的変数のベクトル
label_train = np.hstack((np.ones(group1[3]), np.zeros(group2[3]) ))
分類器
ここが一番大事です!!
誤差更新アルゴリズムの中では、
- 総入力を入力データと重みから計算
- 活性化関数で確率計算
- 重み更新
を行なっています。
活性化関数はactivationで定義しています。
ここをreturn zに変えるとADALINEになります。
class LogisticRegression(object):
# 初期化
def __init__(self, eta=0.05, n_iter=100, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
# 誤差更新アルゴリズム
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
self.cost_ = []
for i in range(self.n_iter):
net_input = self.net_input(X)
output = self.activation(net_input)
errors = y - output
self.w_[1:] += self.eta * X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = -y.dot(np.log(output)) - ((1 - y).dot(np.log(1 - output)))
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
def activation(self, z):
return 1. / (1. +np.exp(-np.clip(z, -250, 250)))
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, 0)
計算
あとは計算するだけ!
作ったデータを作ったクラスに入れて回す!
X_train_01_subset = np.vstack((axis1_train, axis2_train)).T
y_train_01_subset = label_train.reshape((-1))
lrgd = LogisticRegression(eta=0.05, n_iter=100, random_state=1)
lrgd.fit(X_train_01_subset, y_train_01_subset)
おまけ
作図してみた
w0, w1,w2 = lrgd.w_
x1data = np.arange(1., 5., 0.1)
x2data = -w1/w2*x1data-w0/w2
plt.plot(x1data, x2data)
plt.scatter(group1axis1Dist, group1axis2Dist, color='red')
plt.scatter(group2axis1Dist, group2axis2Dist, color = 'blue')
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.show()
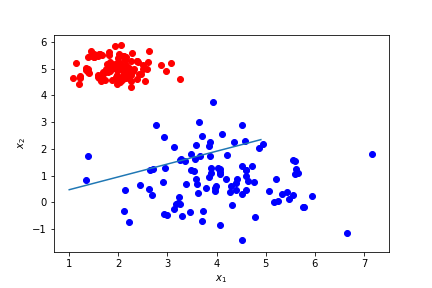
一回だけ重みを更新した状態。(n_iter = 1)
なんとなく引けてるけどちゃんと分類できていないサンプルはある。
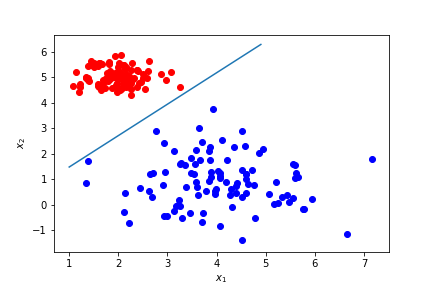
100回イテレーション回した状態。
だいたいここで収束している。
ちゃんと分類できている。
終わりに
単層パーセプトロンがちゃんとわかってれば大したことない。
更新アルゴリズムはほぼ同じだし、違うのは活性化関数だけ。
本質的には活性化関数がとても重要な役割を担っていることが非常によくわかる。
本当はL2正則化についても触れたかったが、一番本質的なところだけとりあえずあげておこうと思います。