はじめに
ロジスティック分布のKLダイバージェンスを計算してみたいと思います。ロジスティック分布についてはこちらを参考にしました。まずはロジスティック分布について紹介し、その後、2つのロジスティック分布のKLダイバージェンスを計算していきたいと思います。
ロジスティック分布
ロジスティック分布は連続確率分布の一つで、その累積分布関数がロジスティック関数のものです。ロジスティック分布には2つのパラメータ$\mu,s$があり、$\mu$は実数全体、$s$は正の実数に値をとります。確率変数$X$の確率分布関数$F$は
F(x;\mu,s)=\frac{1}{1+\exp\left(-\frac{x-\mu}{s}\right)},~~x\in\mathbb{R}
と表されます。ここで、$\exp(x)$は$e^x$と同じ意味で$e$はネイピア数を表しており、$e$の右肩に複雑な式を書いてしまうと見にくくなるのでこのように表現しています。$\mathbb{R}$は実数全体を表しています。$(\mu,s)=(0,1)$とすると分布関数は
F(x;0,1)=\frac{1}{1+\exp\left(-x\right)}
となるので、これは機械学習の活性化関数でよく使われるシグモイド関数に対応していることがわかります。
また、密度関数$f$は
f(x;\mu,s)=\frac{\exp\left(-\frac{x-\mu}{s}\right)}{s\left\{1+\exp\left(-\frac{x-\mu}{s}\right)\right\}^2},~~x\in\mathbb{R}
となります。これは確率分布関数$F$を微分すると得られます。加えて、分母分子に$\exp((x-\mu)/s)^2$をかけると
f(x;\mu,s)=\frac{\exp\left(\frac{x-\mu}{s}\right)}{s\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}^2}
とも表されます。KLダイバージェンスの計算にはこちらを使っていきます。さらに、ロジスティック分布の期待値$\mathbb{E}[X]$、分散$Var[X]$はそれぞれ
\mathbb{E}[X] = \mu,~~Var[X] = \frac{\pi^2s^2}{3}
となります。
KLダイバージェンス
KLダイバージェンスについて簡単に紹介します。こちらの記事でも書いています。
KLダイバージェンス
D_{KL}\left(p~\big|\big|~q\right)=\int_{-\infty}^{\infty} p(x)\log\frac{p(x)}{q(x)}dx
は確率分布$p$と確率分布$q$の距離を測ります。2つの分布が近いと0に近づき、遠いと大きな値となります。また、0以上に値をとり、2つの確率分布が一致すると0で最小となります。
ロジスティック分布間のKLダイバージェンス
それでは、2つのロジスティック分布間のKLダイバージェンスを計算していきたいと思います。つまり、2つの密度関数$p(x;\mu,s)$と$q(x;\nu,t)$のKLダイバージェンスを計算します。念のため、$p$と$q$を書くとそれぞれ
p(x;\mu,s)=\frac{\exp\left(\frac{x-\mu}{s}\right)}{s\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}^2},~~q(x;\nu,t)=\frac{\exp\left(\frac{x-\nu}{t}\right)}{t\left\{1+\exp\left(\frac{x-\nu}{t}\right)\right\}^2}
のようになっています。以下、計算式です。丁寧な変換をしているので冗長な計算になっていたり、計算していく箇所に密度関数の式を書いていったりしていますので混乱しないよう追ってみてください。次のように計算していくと
\begin{align*}
D_{KL}\left(p~\big|\big|~q\right)
&=
\int_{-\infty}^{\infty} p(x)\log\frac{p(x)}{q(x)}dx\\
&=
\int_{-\infty}^{\infty} p(x)\log\frac{\frac{\exp\left(\frac{x-\mu}{s}\right)}{s\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}^2}}{\frac{\exp\left(\frac{x-\nu}{t}\right)}{t\left\{1+\exp\left(\frac{x-\nu}{t}\right)\right\}^2}}dx\\
&=
\int_{-\infty}^{\infty} p(x)\log\left[\frac{\exp\left(\frac{x-\mu}{s}\right)}{\exp\left(\frac{x-\nu}{t}\right)}\frac{t\left\{1+\exp\left(\frac{x-\nu}{t}\right)\right\}^2}{s\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}^2}\right] dx\\
&=
\int_{-\infty}^{\infty} p(x)\Biggr[\log\exp\left\{\left(\frac{x-\mu}{s}\right)-\left(\frac{x-\nu}{t}\right)\right\}+\log\frac{t}{s}\\
&~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
\left.+\log\left(\frac{1+\exp\left(\frac{x-\nu}{t}\right)}{1+\exp\left(\frac{x-\mu}{s}\right)}\right)^2 \right]dx\\
&=
\int_{-\infty}^{\infty} \Biggr[p(x)\left(\frac{(t-s)x-\mu t+\nu s}{st}\right)+p(x)\log\frac{t}{s}\\
&~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
\left.
+p(x)\log\left(\frac{1+\exp\left(\frac{x-\nu}{t}\right)}{1+\exp\left(\frac{x-\mu}{s}\right)}\right)^2 \right]dx\\
&=
\int_{-\infty}^{\infty}p(x)\left(\frac{(t-s)x-\mu t+\nu s}{st}\right)dx
+\int_{-\infty}^{\infty}p(x)\log\frac{t}{s}dx\\
&~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+\int_{-\infty}^{\infty}p(x)\log\left(\frac{1+\exp\left(\frac{x-\nu}{t}\right)}{1+\exp\left(\frac{x-\mu}{s}\right)}\right)^2dx\\
&=:
I_1+I_2+I_3
\end{align*}
を得ます。ここで、最後にはそれぞれの積分を前から順に$I_1,I_2,I_3$とおいています。よって、この$I_1,I_2,I_3$をそれぞれ計算できればよいことになります。まず、$I_1$を計算していくと
\begin{align*}
I_1
&=
\int_{-\infty}^{\infty}p(x)\left(\frac{(t-s)x-\mu t+\nu s}{st}\right)dx\\
&=
\int_{-\infty}^{\infty}\frac{t-s}{st}xp(x)dx+\int_{-\infty}^{\infty}\frac{-\mu t+\nu s}{st}p(x)dx\\
&=
\frac{t-s}{st}\int_{-\infty}^{\infty}xp(x)dx+\frac{-\mu t+\nu s}{st}\int_{-\infty}^{\infty}p(x)dx\\
&=
\frac{t-s}{st}\mu+\frac{-\mu t+\nu s}{st}\\
&=
\frac{\nu-\mu}{t}
\end{align*}
となります。4行目の計算は期待値の定義と密度関数の積分は1になることを用いました。次に$I_2$を計算していきます。これは簡単で、
\begin{align*}
I_2
&=
\int_{-\infty}^{\infty}p(x)\log\frac{t}{s}dx\\
&=
\log\frac{t}{s}\int_{-\infty}^{\infty}p(x)dx\\
&=
\log\frac{t}{s}
\end{align*}
となります。最後に$I_3$を計算していくと、
\begin{align*}
I_3
&=
\int_{-\infty}^{\infty}p(x)\log\left(\frac{1+\exp\left(\frac{x-\nu}{t}\right)}{1+\exp\left(\frac{x-\mu}{s}\right)}\right)^2dx\\
&=
2\int_{-\infty}^{\infty}p(x)\log\frac{1+\exp\left(\frac{x-\nu}{t}\right)}{1+\exp\left(\frac{x-\mu}{s}\right)}dx\\
&=
2\int_{-\infty}^{\infty}p(x)\log\left\{1+\exp\left(\frac{x-\nu}{t}\right)\right\}dx\\
&~~~~~~
-2\int_{-\infty}^{\infty}p(x)\log\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}dx\\
&=:I_{31}-I_{32}
\end{align*}
を得ます。$\log$の性質を使って$I_3$の積分を$I_{31}$と$I_{32}$に分割しました。まず、$I_{31}$の積分は複雑で求めることが難しいので、密度関数$p$での期待値
\begin{align*}
I_{31}
&=
2\mathbb{E}_p\left[\log\left(1+\exp\left(\frac{X-\nu}{t}\right)\right)\right]
\end{align*}
として表現しときます。計算するときには、この期待値はモンテカルロ積分などで求めます。
次に$I_{32}$は置換積分、部分積分法、ロピタルの定理を用いて、
\begin{align*}
I_{32}
&=
2\int_{-\infty}^{\infty}\frac{\exp\left(\frac{x-\mu}{s}\right)}{s\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}^2}\log\left\{1+\exp\left(\frac{x-\mu}{s}\right)\right\}dx\\
&=
2\int_0^{\infty}\frac{1}{(1+y)^2}\log(1+y)dy~~~~~~(\because)~y=\exp\left(\frac{x-\mu}{s}\right)\text{と置換}\\
&=
2\int_0^{\infty}\frac{1}{(1+y)^2}dy + 2\left[\frac{1}{1+y}\log(1+y)\right]_0^{\infty}~~~~~~(\because)~\text{部分積分法}\\
&=
2\left[-\frac{1}{1+y}\right]_0^{\infty}
+
2\left[\frac{\log(1+y)}{1+y}\right]_0^{\infty}~~~~~~(\because)~\text{ロピタルの定理}\\
&=
0-(-2)-(0-0)\\
&=2
\end{align*}
と求めることができます。以上から、2つのロジスティック分布のKLダイバージェンスは
\begin{align*}
D_{KL}\left(p~\big|\big|~q\right)
&=
\frac{\nu-\mu}{t}
+\log\frac{t}{s}-2\\
&~~~~~~+2\mathbb{E}_p\left[\log\left(1+\exp\left(\frac{X-\nu}{t}\right)\right)\right]
\end{align*}
となりました。
簡単なシミュレーション
KLダイバージェンスを求めてきたので、パラメータの変化によってKLダイバージェンスがどのように変化するのかPythonで確認していきます。簡単のため、分布関数$p$のパラメータは$(\mu, s) = (0,1)$の場合、すなわち、分布関数がシグモイド関数の場合として設定します。このとき、分布関数$q$のパラメータ$(\nu, t)$を変化させたときにKLダイバージェンスがどのように変化するのかを確認していきます。
まずは、KLダイバージェンスを求める関数を定義していきますが、一点問題があります。それは、先ほど求めた2つのロジスティック分布間におけるKLダイバージェンスには期待値計算があります。また、この期待値は分布$p$上での期待値なので、この分布に従う$N$個の乱数、すなわち、$$x_1,\dots,x_{N}\overset{\text{i.i.d.}}{\sim}p(x)$$を用いて
\begin{align*}
\mathbb{E}_p\left[\log\left(1+\exp\left(\frac{X-\nu}{t}\right)\right)\right]
\approx
\frac{1}{N}\sum_{i=1}^N\log\left(1+\exp\left(\frac{x_i-\nu}{t}\right)\right)
\end{align*}
のように近似して求めたいと思います。それでは、分布$p$からどのように乱数を発生させるのかというと、逆関数法を用いたいと思います1。逆関数法とは、一様乱数と分布関数の逆関数を用いて乱数を発生させる方法です。まず、分布関数の逆関数を求めます。
\begin{align*}
&F(x;\mu,s)=\frac{1}{1+\exp\left(-\frac{x-\mu}{s}\right)}=:y\\
\Leftrightarrow
&
x = s\log\left(\frac{1-y}{y}\right)+\mu
\end{align*}
により、
y=F^{-1}(x;\mu,s)=s\log\left(\frac{1-x}{x}\right)+\mu
となります。よって、逆関数法により乱数を生成させる手順は次のようになります。
Step1:区間$[0,1)$上の一様乱数$u_1,\dots,u_N\overset{\text{i.i.d.}}{\sim} U(0,1)$を発生させる。
Step2:各$u_1,\dots,u_N$に対して、$F^{-1}(u_1;\mu,s),\dots,F^{-1}(u_N;\mu,s)$を求めます。この$F^{-1}(u_1;\mu,s),\dots,F^{-1}(u_N;\mu,s)$が求めたい乱数になります。
# 必要なライブラリ
import numpy as np
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
def logistic_KLdiv(mu = 0, s = 1, nu = 0, t = 1, N = 10 ** 6):
# 乱数の生成
ru = np.random.rand(N) # Step1
rl = s * np.log( (1- ru) / ru) + mu # Step2
#期待値の近似計算
e = np.log(1 + np.exp((rl - nu) / t)).mean()
return (nu - mu)/t + np.log(t / s) - 2 + 2 * e
◆**$\nu$を固定した場合における$t$の変化**
$\nu=0$と固定した場合における$t$の変化を描画してみたいと思います。コードは次のようになります。
x_list = np.arange(0., 10., 0.02)[1:]
y = [logistic_KLdiv(mu = 0, s = 1, nu = 0, t = x, N = 10 ** 6) for x in tqdm(x_list)]
plt.plot(x_list ,y)
plt.vlines(x_list[np.argmin(y)], -0.5, 10., "blue", linestyles='dashed')
plt.grid()
plt.ylim(-0.5,10)
plt.show()
これをプロットした結果は
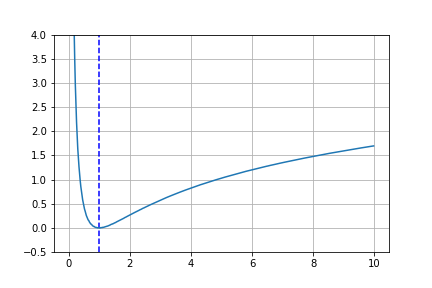
のようになります。青色の縦線は、KLダイバージェンスが最小となる値を示しています。このときの$t$の値は1.0となりましたので、ちゃんと求まっていることがわかります。
◆**$t$を固定した場合における$\nu$の変化**
次に$t=1$と固定した場合における$\nu$の変化を描画してみたいと思います。コードは次のようになります。
x_list = np.arange(-5., 5., 0.02)
y = [logistic_KLdiv(mu = 0, s = 1, nu = x, t = 1, N = 10 ** 6) for x in tqdm(x_list)]
plt.plot(x_list ,y)
plt.vlines(x_list[np.argmin(y)], -0.5, 10., "blue", linestyles='dashed')
plt.grid()
plt.ylim(-0.5,4)
plt.savefig("change_of_nu.png")
plt.show()
これをプロットした結果は
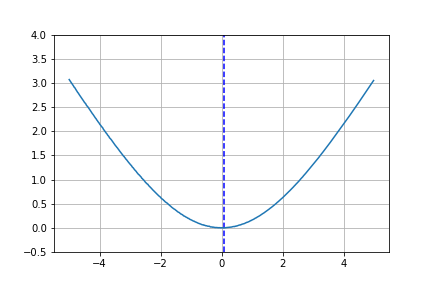
のようになります。青色の縦線は、先ほどと同じようにKLダイバージェンスが最小となる値を示しています。このときの$\mu$の値は0.0599となりました。理論的には0になるべきですがこれは期待値の部分を近似しているための誤差だと考えられます。それにしても0に近い値ですので良い感じです。
まとめ
2つのロジスティック分布間のKLダイバージェンスを求め、簡単にシミュレーションし確認をしました。期待値の部分を乱数で近似したことによる誤差はありますが大方良い感じかと思います。
-
Pythonでは、ロジスティック分布から乱数を発生させる関数がありますので、そちらを用いたい場合は調べてみてください。 ↩