タイトルの通り、就職活動のために作ったアプリが意外にも使える子に仕上がったので、自慢します。
最初の方にアプリの紹介と技術制約の話を書いておきます。
「なんでそんなもん作ったんや?」という疑問には、あとの方のセクションで書いてきます。
この記事を読むとうれしくなれること
- ollama.cppの小規模モデルは目的を絞れば使える子だし、弱いCPUマシンでも動く。
- 誤ったLLM出力を前提にしたシステム開発の例。
- 就活のためにアプリをつくるマインドセット。
- ヨーロッパのIT産業がまじヤバい話。
こんなものを作った
言語学習者のための日記アプリを作りました。
動作デモのビデオがあるので、ビデオを見てもらうのが手っ取り早い。
外国語学習の習得テクに「外国語で日記を書く」という手法が古くから知られているし、推奨もされてます。
ぼく自身が多言語の言語学習者で、日常的に日記を書いてるので、個人的な経験からも、この習得テクが良いと信じてます。
が、いつも煩わしく感じてることがあります。
- 学習中の言語で知らん表現、でも別言語では知ってる表現、そういうのに出くわすとものすごい時間を食う。
- ChatGPTもGeminiも、いい品質で誤り訂正してくれる。でも、誤り訂正の管理が面倒なんじゃ。
なので、LLMでいい感じにしてくれるアプリを作りました。いい感じとは、
- 学習中の言語で知らんを表現を別の言語で表現できる。 メタ記号
[ ]で覆う。例えば、I am writing a blog [記事] on Qiita. - LLMが文法誤りの指摘してくれる。
- LLMが表現を指定の言語レベルで書き直ししてくれる。
- 知らん表現、文法誤り、書き直した文はアプリがDBに保存してくれる。
これでぼくが抱えてた問題は2つとも解決しました。
やったね!
ちな、処理をフロー図に示すとこんな感じになります。
技術的な制約
このアプリの開発にあたって、次の制約をつけました。
なんでこの制約が出てきたのか?はあとのセクション「就活のために技術ショーケースを作る」を見てください。
- LangGraphを必ず使うこと。
- LLMはローカル動作すること。
- アプリとDBもぜんぶローカル動作すること。
- 非力なCPUマシン[^1]でも現実的に動くLLMを使うこと。
- RAGを実行すること。
- AgenticLLM風味に仕立て上げること。
AgenticLLM風味に仕立てあげるには、LangGraphを使えば簡単にできます。
で、AgenticLLM風味でシステムを作るために、あえて日記を添削タスクを複数に分割します。
具体的には、
- 知らん表現
[]を翻訳するだけのエージェント - 文法誤り指摘してくれるエージェント
- 日記を指定の言語レベルに書き換えしてくれるエージェント
- アドバイスをしてくれるエージェント
RAGの要件を満たすために、「アドバイスをしてくれるエージェント」では、過去の文法誤りをベクトル検索し、過去の文法誤りをもとにアドバイスしてくれます。
非力なCPUマシンで、ローカル動作させるためにOllama.cppを選定しました。
結果的に、タスクをエージェントに分割したおかげで、非力なCPUマシンで動作可能な小型LLMでも 「使える」 感覚のアプリに仕上がりました。
DBをローカル動作させたいので、DuckDBとChromaDBを選定。
使ってみる
先にも書いたとおり、ぼく自身が言語学習者で作ったアプリのユーザーです。
もちろん、日本語が母語ですが、他に3言語を日常的に使います。
- 英語(C1レベル)
- ドイツ語(B2レベル)
- フランス語(B2レベル)
あと、中国語(A1≒HSK 1)レベルも最近やってます。
A, BやらCというのはヨーロッパ言語共通参照枠の言語レベルのことです。
私が知る限り、世界でもっとも標準化された言語レベル表現です。
B2レベルだとやはり満足感が低いわけで(個人的な意見)。
できれば、B2をC1レベルに向上させたいし、C1の英語もよりC2レベルにしたいわけです。
というわけで、次のケースで数日、使い続けました。
| 日記言語 | []言語 | 書き換え指定レベル |
|---|---|---|
| ドイツ語 | 英語 | C1 |
| フランス語語 | 英語 | C1 |
| 中国語 | 英語 | A1 |
| 英語 | 日本語 | C2 |
LLMはQwen2.5:3Bを選択します。選択理由は現実的なLLMの選定を見ましょう。
上の言語ペアの中で、以下の傾向を観察できました。
- もっとも成功率が高く、出力の品質も高いのは、ドイツ語(英語)とフランス語(英語)。文法誤り指摘も妥当。
- 英語(日本語)は、書き換えがエージェントが元から逸脱した文を作る頻度が高い。
- 中国語(英語)はそもそも
[ ]の翻訳すら失敗する頻度が高い。
LLM出力失敗を前提にした設計
そもそも小規模LLMでまともに動く(期待とおりの正しい出力)を求める方が間違ってるんですね。
なので、ここは考え方を変えてこうしましょう。
LLMの出力は間違っているかもしれない。だから、後で編集できるUIにする。
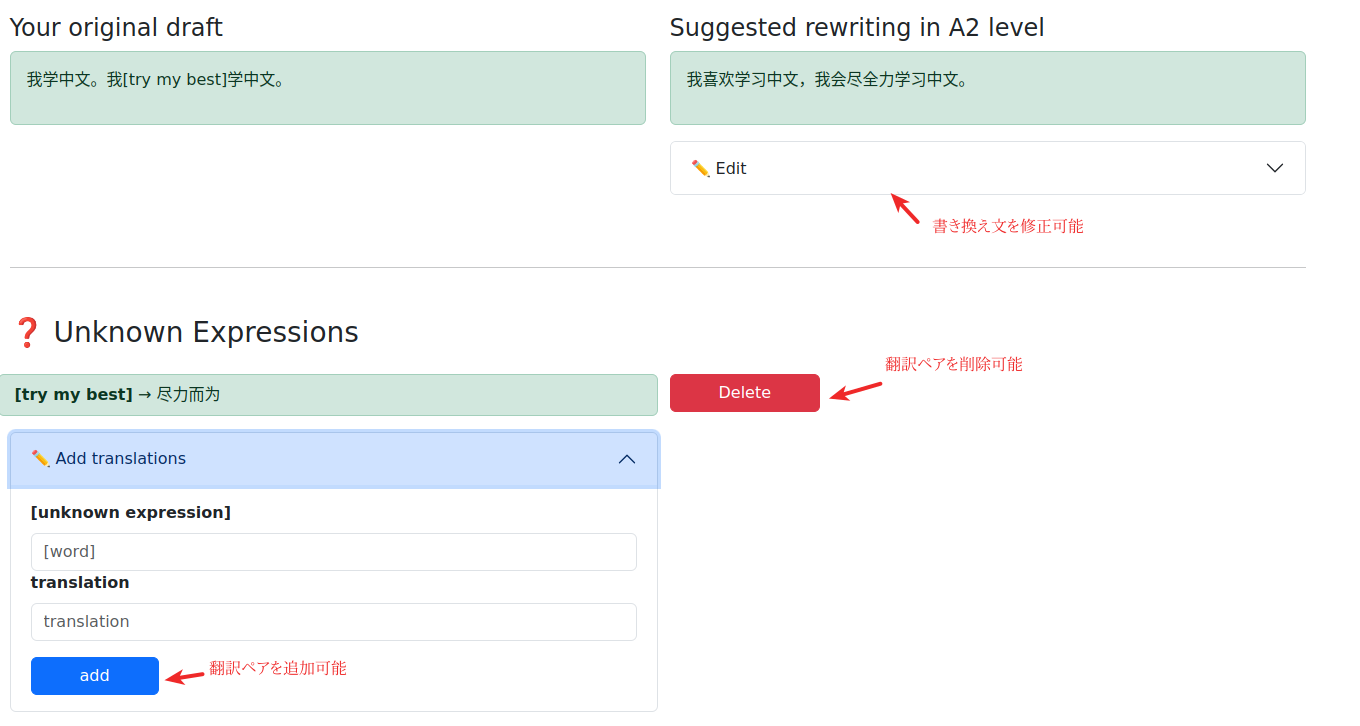
なんか間違ってるっぽいなーと感じたら、ChatGPTやらGeminiに聞いて、人手で修正すればいいんです。
その修正過程もまた言語学習の学習プロセスになってるはず。
就活のために技術ショーケースを作る
そもそも、なんでこんなアプリを作ろうと思い立ったか、って話です。
ぼくは、いま現在、フランスで期限付き雇用研究者やってます。
普段はフランス科学技術庁のGPUスーパークラスタでアホみたいな金額の計算をぶん回してます [^2]。
クラスタにジョブを投げるたびに「ああ、クラスタマシンがうなりあげているんだ」と快感を感じる程度になってきました。
研究者というのは、自由さがあるものの、期限付きの雇用は給料が安くて涙目になります。
かといって、ぼくは教授職を目指せるほどの実績はない。
さっさと産業界で仕事を見つけたほうが幸せというものです。
後述しますが、2025年頃からヨーロッパのIT産業は守りの姿勢に入ってます。
つまり、採用活動を含めた投資に消極的になってる状態です。
実際のところ、消極的な採用活動はマジでゲロヤバ状態になっており、「300社に応募して、面接に至ったのは1社だけ」という話がアメリカでもあるくらいです。
これはアメリカでの例ですが、似た数字の投稿をEU圏でも毎日のように目にします。
困難な就職活動を勝ち抜くたくためには、少しでもResume/CVを良くする必要があります。
少しでもResume/CVの見栄えをよくするためには、「おれ、システムも作れちゃうぜ(研究活動以外もデキるぞ)」というアピールが考えられるでしょう。
で、そのためには、実際にシステムを作ってGithubで公開するのがもっとも手っ取り早いわけです。
どんなシステム・アプリを作るのか?
「自分が好きな分野・必要性を感じてる分野で開発するのはイチバン」。
昔からQiitaの投稿でもよく目にする記述ですし、スタートアップの開発者も似たようなことを言いがちです。
ぼくの場合は、言語学習をしているし、外国語で日記も書いている。
ということで、言語学習の分野でシステムを作ることにしました。
技術要件を決める
あくまで技術デモ(自分の技術アピールのため)なので、なるべく最低限の時間で作り上げたい。
ということで、ぼくがすでに使いこなしてるフレームワークを土台にする(FastAPI, Flask)。
技術デモなので、いま現在の主流フレームワークを使っておきたい。
ということで、LangChain。
さらにさらに、はやりの技術キーワードをCVに書きたい。
なので、RAGとAgenticLLMを無理やりねじ込む。
せっかくつくるなら、少しくらい挑戦もしてみたい。
ぼくは普段からGPUマシンを使いまくってるわけですが、これはぜーんぶ大学と政府のマシン。
ぼく自身はGPUマシンなんて持ってないわけですね。
どうしたものかな、と考えていると、家にあったMiniPCが目に入る。
Ollma.cppでCPU最適化されてれば、MiniPCでも動くんじゃね?
で、やってみたら、それなりの速度で返事を得られる。
ということで、Ollama.cppとMiniPCで動くLLMという制約を決められた。
現実的なLLMの選定
さて、どのLLMを使うべきだろう?
よわよわCPUで動作させるからには、パラメータ数を7B以下に抑えておきたい。
パラメータ数が7B以下で、かつ、ぼくが書きたい言語を扱えるモデルは以下のとおりだ。
| LLM | いいとこ |
|---|---|
| Qwen2.5 3B | 29言語サポート |
| Qwen2.5 7B | 29言語サポート |
| Mistral-7B-v0.3 | 特にEU言語に強い |
| Phi-3.5 Mini 3.8B | |
| Qwen3 0.6B | Thinking modeがある |
いちおう研究者なので、モデルの正確さ評価と実行速度のベンチマークをとって決定した。
正確さ評価には、MUCH datasetのフランス語、ドイツ語サブセットで評価した。
評価はLLM-as-judgeスタイルで実行した。LLMの出力 $y_{\rm hyp}$ をデータセットの正解 $y_{\rm truth}$ と比較し、同じ意味(entailement or not)かどうかを、Geminiに判断させた。
結果だけを書くと、正確さはこうなった。高い正確さ順。
- Mistral-7B-v0.3
- Qwen2.5 7B
- Qwen3 0.6B(thinking)
- Qwen2.5 3B
- Qwen3 0.6B(non-thinking)
- Phi-3.5 Mini 3.8B。
一方、よわよわCPUマシンでの速度比較はこうなった(速い順)。
- Qwen3 0.6B(non-thinking)
- Qwen2.5 3B
- Qwen2.5 7B
- Phi-3.5 Mini 3.8B
- Qwen3 0.6B(thinking)
- Mistral-7B-v0.3
最終的にQwen2.5 3BとQwen 0.6B(non-thinking)を実際に切り替えながら使ってみて、Qwen2.5 3Bを選んだ(主観)。
ヨーロッパのIT産業がマジでヤバい話
(就職活動において、まじヤバいという話)
話題をいきなり変えて、ここからはポエム風味でお送りします。
そもそも、このアプリを作るきっかけになった、ヨーロッパでの就職活動の話だ。
まず最初に、ぼくの就職活動状況を紹介しよう。
現在のところ、ぼくは80社くらい応募して、面接が2件だ。
つまり、 面接到達率が2.5% という状態。
ぼくのスキルと学歴が不足しているとは考えづらい。
自分でいうのも何だが、産業界で10年ちかくコードを書き続けてきたし、フランスで博士学位を取得している。
ヨーロッパ圏で十分すぎるくらいに通用する大学と学位だ。
ここでぼくが博士課程を過ごした友人たちの話も紹介しよう。
1人はEU圏で応募しつづけているフランス人だ。
彼は50社ちかく応募しつづけて、面接到達はゼロの状態だ。
もうひとり(イタリア人)は、80社ちかく応募した後に、2社の面接に到達した。
最終的に彼はアメリカへと行った。
ヨーロッパ人でもこの状態なのだ。
EU市民権を持ってないぼくは、もっと困難と考えるのが普通だ。
一般的に企業は非EU圏の外国人を雇用する際に、VISAのサポートが必要になる。
つまり、余計な書類作業とそのための費用も発生する。
同じ条件のEU人と非EU人がいれば、企業はEU人を選ぶ。
いったいどうしてこんなことになってしまったの・・・?
ここからはあくまで聞いた話と私見をモリモリに混ぜて書いていく。
怪文書の類だと思いながら読んでいただければ幸いだ。
そして、以下に書いていくのはフランスとドイツの話だ。
他のEU諸国のことは、ぼくは知らない。
が、フランスとドイツはEU経済の要なので、この2国の状況を抑えておけば、十分だろう。
リスクと不確定要素がてんこ盛り
まず、おさえておきたい経済背景がある。
フランスはコロナ時期のバラマキの後を未だ引きずっている。インフレは上昇を続けており、電気料金も上昇し続けている。
ドイツも似たようなものだが、ドイツはさらにエネルギー料金の値上がりがウクライナ戦争以降で深刻だ。
戦争以前はロシアからガスを購入していたが、ガス供給がストップしたからだ。
ドイツの冬を暖房なしで超えるのはキツい。
戦争の話が出た。これも大きな要因になっている。
フランス政府もドイツ政府もこの2年ちかくで防衛産業への投資額を上げている。
要するに、ロシアが次に何をするかわかったもんじゃないから、国防レベルを引き上げるという話だ。
もちろん、政府財源は無限じゃないので、防衛予算と投資は別の予算を削って作り出されている。
防衛産業企業に限っては、人材募集も活発になっている。
例えば、フランスのタレス、ドイツのティッセンクルップ、エアバスの人材募集をLinkedinでよく目にするようになった。
が、ほぼ必ず、「EU国籍であること」と明記されている。
さらに2025年からのトランプ関税も経済活動のリスクになっている。
いまのところは関税に変動が起きていないが、奴が何を言い出すかわかったものではない。
フランスの話に限って言えば、2026年の政府予算は、いまだに決定されていない(2026年1月25日現在)[^3]。
信じられない話だが、「今年の予算はまだ決まってません。めんご!決まるまで、去年の繰越でなんとかして」 という状態なのだ。
要するに、あまりにも不確定要素&コントロール不可能要素が多すぎる状態なのだ。
一般に企業活動は不確定要素が多すぎるときには、消極的な姿勢を取る。
だって、リスクが多すぎるのだもの。
AIの開発競争
これは経済研究者と話したときの話だ。
企業が採用活動を控えている、という説は彼も同じだ。
が、彼は「AI開発競争の加熱が採用を控えてる要因になっている」説を言っている。
「AIがすごいから人が要らない」ではなく 、AI開発(というかLLM)の開発スピードが早すぎて、「経営計画と人員計画を決定できない。」が彼の説だ。
確かにLLM技術の成長スピードは異常だ。
見せかけの採用活動
これは別の経済研究者からの話だ。
彼の説では「企業は採用を控えているにも関わらず、募集を続けている。それは株主への外見アピール」だという。
企業は採用をしたくないが、採用活動しないと「成長意思なさそう」と株主に見えるので、ハリボテの採用を出しているのだという。
ぼくの周りにもこれの説を裏付ける話が2件ある。
企業の内部情報から「ウチの事業所は今年は採用しない計画」と聞いているにも関わらず、当該事業所から募集が出ているのだ。
まとめよう。
面接到達率2.5%の世界は誇張ではない。
2026年。ヨーロッパのIT界で新たに仕事を見つけるのは本当に困難だ。
それはヨーロッパ圏の経済先行きリスクを背景に、AI開発競争の加熱が作り出した企業の懸念と不信の結果なのかもしれない。
さらに、「見せかけだけの募集」が量産されてる結果、意味もない応募をし続けている結果なのかもしれない。
どうすればこの世界は落ち着くのだろうか?
ウクライナ戦争が集結し、トランプが沈黙し、LLM新規モデルが1年ちかくは発表されない世界・・・そんな世界が来れば良くなるかもしれない。
そんな世界は来ない気がする。
更新
Ghost jobという存在
怪文書パート「ヨーロッパのIT産業がまじヤバい話」へ興味を持っていただいた方々が一定数いらっしゃるようです。私としてはうれしい限り。
情報収集をしていくうちに、これは私の主観や仮説ではなく、すでに "Ghost job" という名前で一般に確立されてることがわかりました。
Ghost jobの定義は「求人募集が出ている」 & 「求人実態が存在しない」の2つ。
フランスTF1の報道
では、産業セクターを絞らなければ、22%の求人はGhost job。マネージャ職に限定すれば、43%はGhost jobという調査結果が出ています。私の求人範囲、ML/AI/LLMの分野に限られば、おそらくもっと高い割合だと思います(情報ソースは私の経験 ∩ 友人の経験 ∩ LinkedInの投稿)。
Ghost jobはなぜ発生するのか?これは仮説ベースであるものの、複数の仮説が高い確度で存在しています。
- 見せかけのため(to 外部): 「うちは盛況でっせ」を 取引先や株主に アピールするため。
- 見せかけのため(to 内部): 「うちは盛況でっせ」を 従業員 アピールするため。
- 履歴書DBのデータを収集するため。
- 候補者プールを構築するため。
- 企業コンプライアンス上の理由: フランスとドイツでは「内部移動募集の場合でも、公平性のために、求人は一般公募しなければならない」という条項が存在する。
4-5の理由は、ここ数年の話ではなくよく知られた話で、ぼくも知ってました。生成AIが一般ユーザーにも浸透(特にHR部署に浸透)した結果、1.と2.の戦略が顕著に発生するようになってきた様です。
.[^1]: N95 CPU * 4 cores. 16GB RAM.
.[^2]: フランス政府に研究プロジェクト申請したら、使えるようになった。
.[^3]: 2026年度ではなく2026年1月1日からの政府予算の話をしている。