この記事の内容
- 要約システム(抽出型)を作った
- AWSで運用構成を構築した
- サーバーレス構成でなるべく安くした
この記事で紹介しないこと
- 要約アルゴリズムの中身
仕事先で「要約システムを作れないか?」と相談があったので、組んでみました。
仕事先はニュースサイトを運営していて、「投稿されるニュースに要約を掲載したい」というのがモチベーションです。
確かに、大手新聞社のニュースサイトでも3行要約が掲載されていて、記事全文を読んでる時間がない人にはいいコンテンツです。
編集者が自分で要約を書けることに越したことはないのですが、要約の作成というのはなかなか特殊技能のようです(と、編集者から聞いた)
こういう時に自動要約というのは需要があるんでしょうね。
で、自動要約ってどんなのがあるの?
自動要約には大きくわけて2つのタイプがあります。
まず1つ目は__文生成型__。
これは入力文書の意味をアルゴリズムが解釈して、いい感じ(訓練データと似た傾向が出せるように)に要約されたテキストを作成するタイプ。
深層学習が流行りだしてから、ようやく実用レベルに達してきました。
で、もう1つは__抽出型__のタイプ。
入力テキストの中から文書全体の意味をうまく表現できるN個のテキスト(一般的には文が1単位)を選択するタイプです。
こちらは深層学習の以前からもそれなりに実用的なレベルのアルゴリズムが存在してます1
「自動要約、おもしろそうやな」と思い立った方はぜひこの記事もご覧ください。
今回は抽出型のうち、LexRankと呼ばれる2004年のアルゴリズムを使います。
すごい平たく言うと「同じ単語が頻出する文はきっと重要」というアイディアのアルゴリズムです。
Qiitaでもこれまでに面白いアイディアの記事が投稿されています。
今回は対象とするデータがニューステキストです。
ニューステキストは「利用される単語ができる限り統一されている」・「文の論理構成が明確である」という特徴があります。
それだけに、形態素分割のミスも発生しずらいですし、LexRankのグラフ重みづけもうまくいきやすい__気がします__。そして、これまでの私の勘も「まぁ大丈夫だろう」とゴーストがささやきました。
そういうわけで、今回は厳密な調査はすっとばして、とりあえず先に実装しました。2
AWSのコンポーネントのシステム構成
こんな感じの構成にしました。
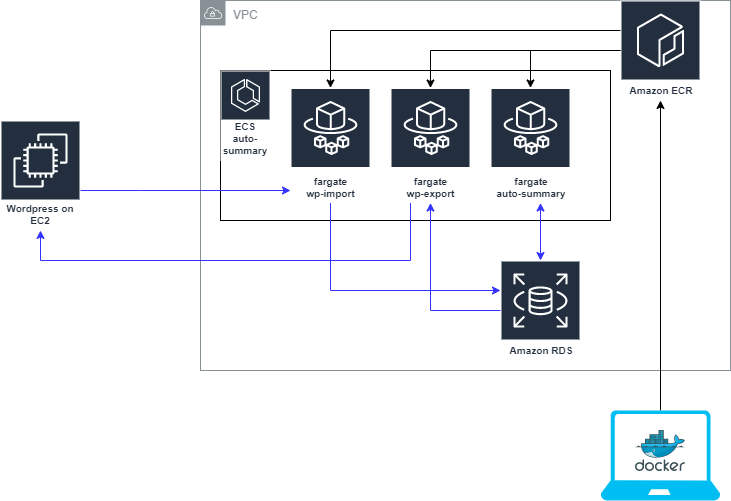
ポイントは次の通りです。
- ニュースサイトはWordpressで運用されてる。
- なるべく運用費は押さえたい。要約の実行はECS Fargate(サーバーレス)にする。
- メンテナンスに外注業者を使うかもしれない。DBを汎用性が高いRDSにする。
役割分担は次の通りです。
- ECS fargate
- wp-import: WordpressからRDSにinsert
- auto-summary: Lexrankで要約。要約結果はRDSに保存。
- wp-export: RDSに保存された要約をWordpressにpost
- RDS
- ニュース記事と要約文の管理。今回のプロジェクトでは、Wordpress以外に記事を管理してるDBがなかったので、ついでに記事データ管理も兼ねています。
RDSのサイズは最小サイズで十分です。
RDSとの通信は1日に数回しか発生せず、コネクションの同時接続も発生しません。
ということで、db.t3.microを選択しました。
この構成で、運用費は月に2,000円弱くらいです。しかも、そのほとんどはRDSの運用費です。
ECS Fargateって?
なんか、さらっと出てきましたが、FargateとはDockerを利用したコンテナサービスです。
実行したいときだけ、計算機コストが発生します。
Batch jobの設定も非常に簡単にできます。
作業手順
もろもろの都合でコマンドは紹介できないですが、作業イメージはこんな順序です。
- ローカルマシンで実装。
- 実装したコードをDockerイメージに入れる。ローカルマシンでDockerイメージを構築する。
- AWSコンソールでECSクラスターを作る。
- AWSコンソールでECR(Dockerリポジトリ)を作る。ローカルのDockerイメージをECRにpushする。
- ECSでタスク定義する。
- ECSでタスクスケジューリングを設定する。
Wordpressとの連携実装
Python用にWordpress APIパッケージがあるので、これを使います。
他にもこういうのもあるので、こっちでもよかったかもしれません。
Lexrankの実装
リクルートテクノロジーズのブログに日本語Lexrankの実装が紹介されてます。
これはPython2版なので、Python3版の実装を使いました。
Lexrankのパッケージがあるので、これでもいいかもしれません。ただし、こっちは形態素分割してる前提なので、Mecabとかで事前に形態素分割してスペース区切りにしておきます。
と、いうことでLexRankを使った抽出型の要約システムを紹介しました。
手元のテキストがニューステキスト的なテキストであれば、割とうまくいく気がします。
AWSでのDocker+サーバーレス構成の構築もお手軽感が高まってきたので、他にもバッチジョブシステム構築に使えそうです。
-
「いつから深層学習はやりだしんや?」という疑問がわいてきそうですが、自然言語処理だと、だいたい2015年くらい?生成型自動要約だと2017年ころからいい感じになってきた__気がします__。RNNを使ったencoder-decoderがブレイクスルーになった感じです。 ↩
-
一応、簡単な評価だけはしました。一般的に要約アルゴリズムの評価にはROUGE-NとBLEUが使われます。しかし、ビジネスサイドの人間にROUGE-NとBLEUの理解をしてもらうのもなかなか大変です。今回は乱暴にもAccuracyでやりました。Excelで表現できるし~。
Accuracy = N(私がOKと判断した要約を持つ文書) / N(入力文書数)↩