どうもこんにちは.私も人工知能,大好きです.
実は好きが講じてとあるロボットスタートアップで家族型ロボットの人工知能の開発に携わっています.人工知能っていうと,もう既にバズワード化してしまっていますね.深層学習や強化学習,汎用人工知能とかニューラルネットワーク,ゲームAIとか自動運転等々,まあなんだかいろいろな言葉が飛び交っています.
でも私の個人的な出発点って,本当は純粋に動物のような知能をロボットとして現実につくりたいという思いが第一で,役に立つとかってことは実は二次的な興味だったりするんですよね.人工知能の技術を使ってなんでもいいからオモロイものをつくってやろうというバイタリティのあるエンジニアの方々のようなモチベーションも自分には薄かったりします.
このノートは,そのような自分が ひとつの動物としての知能をつくる という目標に向かってこれまで集めた雑多な知識のうち.ある程度整理のついた部分を再整理してまとめたいと思いまとめました.それらは動物$+$ロボット$+$知能という組み合わせで,一つの分野に収まるものではないながらもそれぞれがそれぞれの強弱でつながっています.
勉強会などでお会いする機会のあった人たちと話で気づいたのですが,不思議なことに,深層学習をモリモリ使ってすごい認識器をつくるひとも,ゲームの中で人工知能技術を使って生き生きとキャラクターを動かすひとも,"あなたは人工知能をつくっているんですか?" 聞くととどこか不安気で気まずそうな顔です(機械学習をやっているか,という問いには逆に結構自信満々に答えてくれるのですが).
- コンピュータゲームのAIにはどういう前提があるか?
- 認識器をつくるということは,どういうことなのだろう?
- 強化学習に欠けているものはなんだろう?
- 動物では実際どうなっているんだろう?
これらの疑問を,少なくとも自分は以前持ちました.それぞれに対して自分はそれ相応の答えを持っています.この記事でこれらの問いに触れることもあるでしょう.今回はすこしポエミーですが,人工知能について少し底の方から話したいと思います.生物学の方は素人なので,間違い等ございましたら教えていただけると幸いです!;)
思ったより長くなってしまったので,新書サイズのPDFを作成しました.(バージョンが異なるため,このノートとは若干の違いがあります)
なお,この記事は私個人の経験に基づく妄想ノートのため,筆者の所属する組織における内容,製品,開発とは何ら関係ありませんのでご了承ください.
目次
- 身体:最初の疑問
- 生態とデザイン
- 知識と記憶と世界のモデル
- カエルの眼はカエルの価値感について何を語るか
- 統合と生命の幻影
- おわりに : 動物としてのロボット
身体:最初の疑問
Keywords : 身体性
動物のような知能をもったロボットを実現したい,ということを究極的な目標にしてみましょう(別にそこに理由はありません.自分の場合は,単にある日やりたくなったからでした).その時のイメージってどういうものでしょう?犬みたいな?猫みたいな?それとも腕がついているようなロボット?むしろもっと変な形のロボットでしょうか?
知能レベルってどういう程度のものでしょうか?これもやはり犬みたいな?それともラットとかネズミみたいなの?(たぶん,殆どのひとはネズミの知能がどの程度か正確に知っている人はいない気がします)逆に,虫とか単細胞生物のようなものでしょうか?(ハエトリグモの獲物獲得の複雑さを考えたら,虫程度とか笑っていられない気がします)
変な疑問をぶつけたのですが,これらは「身体による制約 はロボットと知能を考える上で必ず出てくるよね」ということをまず念頭に入れておきたかったからです.また,実現したいことはなんでしたっけ?を立ち返るものでもあります.たとえば自分の場合,家庭向けのロボットで,サルほどではないにせよニワトリよりは頭が良さそうで生き生きとしているといいなあ.とか思います.
でも実現できるロボットというのは必ず何らかの身体的制約があるわけで,それ故にリアルタイムでロボットの中で動作している人工知能にできることは 与えられた身体に対して最善を尽くす ことまでです.家庭内のエージェントが総合的に言って何をもって最善かはそれ自体かなりの難問です.
もう少し人工知能/機械学習的にいえば,システムへの入力と出力のインターフェースと(必ずしも既知とは限らない)外部のダイナミクスが与えられた上で "最適な"(あるいはそれに近い)出力系列を出すことが,外に放り出されたロボットの人工知能にできる最大限のことだと言えます.それでは人工知能の知識はここでの意味のロボットの設計には利用できないのでしょうか?ここでは深く述べませんが,できると考えています.その点については世界のモデルに関する箇所でもう少し説明したいと思います.
前置きが長くなってしまいました.要するに家庭用のロボットがそこそこ良い性能で,これに "ニワトリよりは頭が良さそうで生き生きとしている感じの知能" を作りたいんですが,どうしたらいいんでしょう?私はその方法にまだ到達できていませんが,そのための正しい梯子を登っていきたいと考えています.そのなかで自分の中でこれは今後も揺るがない,という内容を紹介したいと思います.
生態とデザイン
Keywords : 4つのなぜ,生態
私達が想像する動物は皆,移動している,あるいは動いていることがほとんどだと思います(もしかすると,イソギンチャクやツリガネムシみたいな固着性の動物を想像する変わった人もいるかも知れませんね.でも,ここではそれでもOKです).
その動物,なぜ動いているんでしょうか?
4つのなぜ
こういった問いに対する話題を人と話すときは気をつけなければいけません.動きの生理的な仕組み,進化的な理由,それとも単に相手が生殖のターゲットとして働きかけているだけなのか,それぞれの相手の興味の中心に応じて,話す内容が全く変わってしまいます.このような混乱は生物学にも当然ありました.
それぞれの興味にはそれぞれまっとうな理由があり,これを分類したものは提唱した行動生物学の祖,Nikolaas TinbergenにちなんでTimbergen の4つのなぜと呼ばれています.このスローガンは,動物の特定の行動について議論するときには4つの異なるアプローチがあることを主張しています.
- [機能・適応] その個体のその行動が,現在の環境で 生存・生殖になぜ利益をもたらしているかの理解
- [メカニズム] なぜその行動が個体で実現されるかという仕組みの理解
- [発生] その個体がDNAからなぜ形成されるかに関する理解
- [進化] なぜその個体はこれまでの世代を経てそうなっているのかという理解
ロボットについて語るときは主に機能とメカニズムの2つについて議論する事が多いと思います.特に,ロボットの動きについて話すときは,相手がエンジニアか,リサーチャーかアーティスト,あるいはビジネスマンなのかと,相手によって全く話す言葉と関心のある情報が異なります(分野によって異なる言葉で同じものを指している場合や,少しずれている場合もあります).
多くのエンジニアはメカニズムの話以外に踏み込みません.また多くのアーティストは機能や適応について,直感で話そうとします.ビジネス/マーケット・あるいはディレクター気質のある人はロボット個体を超えた,ある種その個体の生態(社会にはどのようなニッチが存在するか)であったり進化の範囲にある内容を話題にするかもしれません.それぞれの人が混在する場合,その場は何について議論しているのかを明確にしなければ容易に消化不良な会話となります.そういったときに,この4つのなぜという視点が効いてきます.
相手と"行動"について話すとき,自分が議論したい内容と違っていてもどかしい思いをするかもしれません.そういう時は,個人的な方法論では,まず今はどの種の問いについて議論しているのかをまずははっきりさせる必要があります.自分で考えるときも,自らがどの種類の問いについて考えているかを意識することでより領域がクリアになります.
ロボットの生態
あなたが想像する動物ロボットはどのようなサイクルを回して生活するのでしょうか?それぞれに意味を見出すのは難しいかもしれませんが,まずはイメージしてみましょう.その身体はすでに与えられているとします.季節で変化はないでしょうか?夜は何らかの理由で寝るんでしょうか?昼はどうしているんでしょうか?お掃除ロボットのように充電の必要があるんでしょうか?なにか他に仕事があるんでしょうか?
現実のロボットでは,生物の進化のような膨大な時間と個体を利用数を利用して現実世界に生態をまったくのゼロから形作ることは現実的に難しいです.環境中である程度明確な目的関数が設定できるのであれば,シミュレーションで実時間より高速に行うことで評価可能かもしれません.しかしシミュレーション対象として人とのコミュニケーションを含んでいたり,ヒトの社会的な特性に深く依存した動きを目指す場合はシミュレータの開発や評価関数の定義自体が困難なため,メリットは限定的なものとなります.
以上の理由から,動物ロボットのラフな生態についてはその仕様を十分に加味した上で,ある程度のデザイン作業が必要です.とはいえラフに決める中で振る舞いをパラメトリックに定義して,後で部分的に最適化する可能性は残ります.このデザインにはまず,ロボットの仕様や特性から想定されている基本的なリズムを描いてみることから始めるのが良いのではないでしょうか.
同様の実際的な問題解決型の考え方を非常に初期に広げたのが,心理学者の戸田正直が考案したきのこ食いロボットの設計という仮想的な問題です. これは仮想的に未知の惑星で動くロボットの知能を設計するという思考実験で,究極的な目標(エネルギーを充填しながらウラニウム鉱石を最大限採掘する)を解決する目的思考で知能を捉えていきます.McFarland と Bösser もまた同様に,ロボットを家庭内に生息する動物と見立ててお掃除ロボットに関する考察を広げています[15].近年では実際にロボットが可動する状況で,より実際的な問題としてとらえることができるのではないかと思います.

図:きのこ(Wikipediaより)
ロボットの基本的な生態・行動のサイクルが決まったら,それらを実際に実現することになるでしょう.少なくともここで重要な点は,機械学習や特定のアルゴリズムやソリューションを使うようなエンジニアリングを前提とするのではなく総合的に言ってどのような動物・行動を実現したいかを前提とすることだと私は思います.それも個々の特定の動きではなく,もっとより長いスパンでの全体的な印象や方針が重要だと考えます.
もちろん,最新のソフトウェアパッケージ・継続的インテグレーション・深層学習等の最新のアルゴリズム・統一された行動の理論等のそれぞれは作業効率の向上や継続可能な開発をサポートするものかもしれません.ある種のアルゴリズムを使用しなければそもそも多くの内容が実現困難なものもあるかもしれません.確かにそれは各々の機能を実際に実現するためにはその通りです.おそらくは計算リソースを含む,ハードウェアの設計時においてそのような議論はむしろ重要な場合が多いと思われます.
しかしながら,それは中身の話であって最終的なロボットの振る舞いや生活を伺う上では関係のないことです.むしろ,ソフトウェアが全くわからないひとが動物に対して当然のように抱いている直感・先入観を当然として目に見え触れることができるようにし,技術的な高度さよりも,どのような動物であるかを伝えきることの方が優先順位は高いものではないでしょうか.そしてそれは逆も然りと感じます.
身体的な特性に大きく拘束されるロボットにおいて動物ロボットの振る舞いに対するデザイン作業が重要となる以上,それを行う人間にはロボットを動かすイメージとしての想像力と同時にロボットシステムとその特性に関する理解が望まれると考えています.ロボットは特に,シミュレーション等で想定された画面の中での動きと実際のロボットで動かした場合とで印象は大きく異なります.これは現実のマシンに実際には不備があるということ以前に,心理的な問題もあるように見えます.そのためどんなロボットでも必然的に,このデザイン作業と実現をより多くのサイクルを回して最適な答えを探していく必要があるでしょう.そのため,ロボットの行動の開発にはアジャイル開発を行う必要が出てくるのではないかと思います.
判断に困るのは,リッチな入力が与えようとしたときに,それを適切に出力として統合するイメージがその時点で無い場合です.特にエンジニアによく見られる誤りだと思いますが,素材となる情報を追加することで常にロボットのふるまい全体としてのパフォーマンスが向上すると考えている場合があります.必要なのは全体の統一感であるため,一点において派手な演出を組み込むことは振る舞い全体にひずみを加えることになるかもしれません.
なぜその情報を加えるのか・なぜそれがその動物にとって価値があるのか・どのようにそれは発現するのかといった議論がなければ,それは非常に強引な感覚を受けます(その一方で,認識技術の開発は基本的にハードウェア開発のように慣性の大きいもの.その認識技術をスクラッチで作る必要があるとして,急に必要となるとロバストに使えるようになるには基本的に時間が必要というジレンマがあります).
知識と記憶と世界のモデル
Keywords: Partially Observable Markov Decision Process, 記憶の必要性, 世界モデル, 予測, ゲームAI
note: この章の POMDPと記憶 と ネコの話 は私のアイデアの核心が書かれていますが,数式が追えない方は読み飛ばしてしまうのも一つの読み方だと思います
なにか直近に関する短期的な記憶,というものが存在していれば様々なメリットがある,というのは誰でも思い当たることではないでしょうか.再帰型ニューラルネットワークをトレーニングして使うとか,何らかの情報をデータベースに保持しておくとか,いろいろと実装上のアイデアは存在すると思います.では,必ずその記憶という機能が無ければ解決できない場面というのは一般的に言ってどういう状況なのでしょうか?意思決定問題の中でそういった疑問に答えてくれるのが,部分観測Markov決定過程(Partially Observable Markov Decision Process:POMDP)と,それに対する強化学習(PO Reinforcement Learning:PORL)問題の枠組みと理論です.
POMDPと記憶
POMDPは計画問題の一つで,意思決定するエージェントが環境の状態(State, $s$)に関連する部分的な観測情報(Observation, $o$)と報酬(Reward, $r$)を受け取り,それとの確率的な相互作用のもとで将来的な報酬の重み付き総和$G = \sum_{t=0}^\infty \gamma^t r_t$を最大化する行動(Action, $a$)を取ることが目標です(下図). 環境は複数の条件付き確率,状態遷移モデル$P(s'|s,a)$・観測モデル$P(o|s)$・報酬関数$r(s,a,s')$(または$P(r|a,s)$)で構成されています.そして,エージェントにとってこれらパラメータが既知,つまりすべての観測確率が$P(o|s)=P(o|m)$でかつすべての遷移確率が$P(m'|m,a)=P(s'|s,a)$,だと仮定した状況を想定します.

図:POMDPによる相互作用モデル
POMDPは人工知能では極めて重要な問題で,個人的には自律エージェントにおいて課題となりうる問題はPOMDPの設定によって全て表現できると考えています.詳しい話はPOMDPの専門書に譲るとして,ここではその結論だけを紹介することにしましょう.
POMDPでは得られた経験(観測・行動)の系列をもとにBayesフィルターを使って状態を推定し,その確率分布(信念, $b=P(s|o_{<t}. a_{<t})$, $x_{<t}$は時刻$t$までの系列)をつかってエージェントの行動を決定すれば,最適な方策を得ることができると知られています($a \sim P(a|b)$).解析的なPOMDPの解き方は計算量が非常に大きいことが知られていますが,ここの説明もまた本稿の主題ではないため,割愛します.
POMDP自体は無味乾燥な表現ですが,非常に似た形式をもつ推論問題のSLAM(Simultaneous Localization And Mapping)を知っている方はより生き生きとした内容を想像できるかもしれません.ここではPOMDPにおける状態と信念が動物ロボットにおいてもつ意味を考えたいと思います.
より具体的に考えてみましょう.ロボットでは自身がもつセンサー(カメラ,Lidar,マイクロフォン,あるいは画像認識の結果など)によって観測を構成します.SLAMと同様の考え方をして,その観測を生み出した原因(状態)を推定することでロボットは状態を推定します(信念をもちます).では,この観測を生み出す環境の状態とは直感的にどういうものでしょうか?
私がもつ状態についての1つの自然な解釈は,ロボットを含んだ外界すべての物理的な状況を表す/それに対応するものです.「すべての物理的な状況」に関してはいろいろと程度があると考えられますが,ロボットが現在直接センサーでわかること以外に現実的には様々な物理的状況が存在していて,これが将来の観測に影響を与えています.例えば冷蔵庫の中身を知ることのできないロボットが眼の前の冷蔵庫の扉を開けるとき,開けたあとでの光景は開ける前には観測できないが確かに存在する,冷蔵庫の中身の物理的な状況によって変わります.
「そこの冷蔵庫にプリンが入っている」等の言葉をそのロボットが理解するとは,物理的状況がシンボリックな情報によって操作されることに等しいのではないでしょうか.これらは実際には,なにも統一的な確率モデルで構成されているとは限りませんが,ある処理とある処理はいまは統計的な独立性を仮定してるんだよな・・・等のバックグラウンドとして把握しおくことに意味があると思います.世界モデルは,一つの究極的なセンサ・フュージョンの姿と言えるのではないでしょうか(むしろ物理世界は,ヒトが理解できるという特性を持った表象のひとつの形態といったほうがより適切なのではないかと疑ってます).
繰り返すようですが,ロボットが状態を経験(観測・行動の系列)から推定した事後確率の分布が信念になります.信念は経験に合致する物理的状態を推定した結果にほかならないため,冷蔵庫の例で言えば中身を確認したあとに扉を閉めても中の状況を,そこにあるであろう物理的状態として保持することを含んでいるでしょう.これは我々が日常的に**(短期的な)記憶**とよぶものと合致するものが多いと私個人は考えます.しかも記憶を利用しないエージェント(観測に対して反射的に行動を決定するエージェント$a \sim P(a|o)$)と真の状態を知っているエージェントとを両者が実現できる最適な方策のパフォーマンスで比較した場合,前者はいくらでも性能を悪くすることが可能であることが知られています(本質的に解けない問題がある[1].
POMDPにも状態と観測の関係やダイナミクスの複雑さによって実際にはさまざまな状況がありえます.大塚はそういったPOMDPをその難しさに応じていくつかタイプ別に分類しています[2]. POMDPを解いて得られるふるまい自体もおもしろく,自らの信念が曖昧な場合はまず現状を確認するために確認できる情報を取りに行くといった行動などが創発します[3].
先程の前提の通り,POMDPは意思決定エージェントにとっての世界のモデル(観測モデル $P(o|m)$ ,状態遷移モデル $P(m'|m,a)$,報酬関数 $r(s,a,s')$ )が全て既知としてスタートします.POMDPをこういう事前知識なしに解こうとする分野はPORLと呼ばれる強化学習の分野になります.POMDPの知見によって,真のモデルから得られた事後確率,すなわち信念を入力として行動を選択することで最適な行動決定規則が得られます.POMDPの自然な類推から,まず世界のモデルを学習させてそのあと学習器の内的な状態(信念に相当)を使って行動を学習させるというアプローチが考えられます.
これらは実際に Hutter や David Ha & Schimidhuber,それに大塚が取っているアプローチで,前2つは Feature Reinforcement Learning や World Model などと呼ばれています.これに限らず,暗黙的にこのような形式で世界モデルと方策の学習を同時に行っている研究も数多く存在します.世界のモデルに関しては先の短期的な記憶と比較してより長い目で更新する必要があるため,行動の学習とは別のより長期的な記憶あるいは,この世界に関する知識と言えるものだと考えられます.

図:World Model (https://worldmodels.github.io/ より)
ネコの話
ところで,以前人工知能が猫認識をしたというGoogleの研究者(当時のAndrew Ngのチーム)の話題が出ていましたね.あの状況,**様々な画像を独立同分布としてサンプリングしてきて教師なし学習をさせたものが,なぜBiologicalな文脈で意味がありそうということになってるんでしょうか?**それも実は,POMDPの文脈で大枠として理解できます.あの内容は制限付きボルツマンマシンを畳み込み結合状に制限してスタックして教師なし学習させた結果,猫に反応するセルが上位の層で出現したという内容でした(内容の意味することが高度なので,正しく報道できているメディアは無かったと記憶していますが).
私の理解では,まずその種の動物が長い間かわらぬ環境・生態で進化してきたと仮定します.動物の生態・行動がほぼ変わらないとした場合,これはPOMDPで一定の行動方策 $\pi$ で行動を取り続けた状況と解釈できます.するとPOMDPの状態遷移のみに着目すれば,これは背後のMarkov過程が無限に続いているという極限の近似ととらえることができます.極限的にはMarkov過程はその性質から,方策に依存したある定常分布 $P_\pi(s)$ をもちます.なので十分長い間エージェントが(ときには世代を超えて)存続していると考えた場合,観測モデルを使って各画像 $o$ は $P(o|s)P\pi(s)$ から生成されていると近似的に考えることができます.
このサンプリングの偏りが,データ中の画像の種類の偏り,つまり生態に応じた視覚的入力の偏りを反映しています.粗い近似ですが,ある生態の動物がある方策で動き続けた結果(これはデータの分布に暗に組み込まれています),もし動物の脳が生成モデルと同様の構造を持っているのであれば階層的な構造によってネコ細胞が生じていてもおかしくないよと主張しています.そして脳は,どうやらすくなくとも階層的な認識しているぞと考えられています[4].
いわゆる AI
ゲームAI,特にNPC(Non-Player Character)を操作する場合はこの文脈ではどういう状況に当たるのでしょうか?コンピュータゲームに関してはよく現実の状況との違いを認識しておかないと完全に混乱します.ゲームのキャラクターの場合,世界の情報はプレイヤーの状態を除いて基本的にすべて観測することができ,かつそれらの遷移も既知なため,世界のモデルとその瞬間の世界の状況(=状態 $s$)がほぼ既知な状況で行動していることになります.ゲームそのものがエージェントにとっての世界であり,同時に世界モデルでもあるという二重の状況のため,ゲームのキャラクターにおける知能とはなにかを考えるときはその点を意識しなければ混乱を生じます.敵モンスターなどのNPCは動きのリアリティのために,デザイナーから故意に観測$P(o|s)$を定義され情報を削られている状況で動いていると解釈します.
世界のモデルは認識に関して,1つの究極的な状況を表現していると言えます.POMDPは,自律的なエージェントがたとえ自らの周囲の環境に対するすべての知識(真の確率モデル)を持っていたとしても最適に動くことは本質的に異なる難しさがあることを示しています.先の節では認識系を開発していたり,ゲームAIを作っている人が「人工知能をされているんですか?」という言葉でなんともいえない返事をするという経験があると述べました.なにか直感的に本人の中で納得できない点があるのではないかと思います.私の個人的な見解によれば,認識とは別に行動は全く異なる点があることを両者は(少なくとも,直感的に)理解しているものの,機械学習エンジニアは行動を欠けた形で開発する点,ゲームAIは認識に関して既に完成された認識に対するマッチポンプな状況でエージェントを動かしている点で疑問が残るのではないでしょうか.
中身を知っている人にとっては既に十二分に認識していることですが,人工知能は,人間あるいはその他自然中のエージェントから知的情報処理を抽出し,抽象化し,また拡大した知能そのものに対する知識の集合体です(下図).だいたいの人と話すときは自然のなかのエージェントを想像していて,しかも自分は知能に関する議論に一定の自負があるような体で話してくるのでとてもめんどくさいのが本音ですが,我慢して気さくに話しましょう.それが世間というものでしょうか.
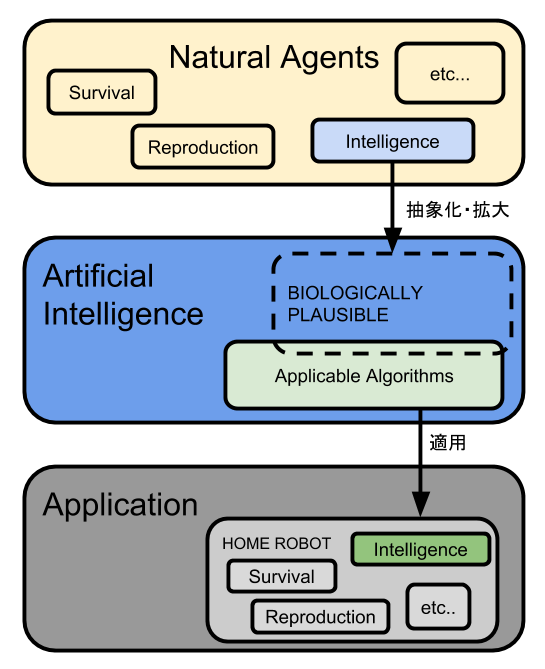
図:人工知能と自然のエージェント・動物ロボットとの関係
ロボット,特に私が今関わっているような動物ロボットは,認識と行動に関して全体的にふるまいの開発者が自ら意識を持って関わっていかなければなりません.少なくとも私は,それがどのような手法で作られているかによらず,一周回って通常我々が日常で想像する人工知能を作っていると思っています.なので,私はなんのためらいもなく「人工知能を作っている」と自己紹介をします.
カエルの眼はカエルの価値感について何を語るか
Keywords: 環世界, 動物行動学, 鍵刺激, Fixed Action Pattern, ヒキガエル, 強化学習
環世界と行動
前節の世界のモデルは,認識で求められる究極的な状況,つまり自身を含んだ全物理的状況を推定し,動物ロボットにとって想像する限りもっとも強力な認識・非言語的な記憶能力を与えて行動を決めようという考え方でした.この認識はPOMDPという計画問題に対するものなので,問題の与え方,つまり報酬関数の設定に関しては任意です.しかしまあ,完全な物理世界のモデルをロボットに搭載することは(少なくとも,ここ10年では)現実的に不可能です.
より現実的な計算機での実行を考えることにしましょう.動物ロボットにとって目的・好ましいもの・苦手なもののようなものが決まっている(つまり,仕様が決まっている)のであれば,ロボットの世界は物理世界全体とその物理的変化から何らかの取捨選択を行ったもので十分な場合が多いでしょう.程度の問題が違うだけで,必ずロボットが持つ世界の縮小は必要です.私達人間も,世界の裏側の降雨量や部屋の中の空気の流れを常に気にしながら生きている人は極めて稀です.
自らに必要な情報を取ってくる,そのための認識という考え方はロボットだけではなく,生物においてもUexküll(ユクスキュル)が提唱するような環世界論として有名です.UexküllはKant哲学から環世界論を出発したため,そこからKant哲学やSchopenhauer,そして仏教・ウパニシャッドへと広がっていけます.この辺りを事前知識として味見すれば,GibsonのAffordanceは自明なもののように理解できるのではないでしょうか(とはいえ,自分は哲学の方は味見以上は踏み込まないことにしましたが).環世界論では,動物は生存に十分な程度の認識能力を持ち,その主観的な世界の中で生きており,世界に関する全てを認識しているのではない等の主張をします.
小さいライントレーサーみたいなロボットを作っていると実感する内容ですね.線をたどる,それだけを目的にしたロボットは極めて小さくてロボット近傍だけに関する世界で動いています.Uexküllの文献では明瞭ではありませんが,日本の書籍ではより後年の渡辺慧という物理学者・情報科学者の「認識とパタン」という書籍ではより明らかに説明されています.機械学習に関わる全ての人間が扱う距離という概念が独立したものとしては存在し得ず,我々あるいはその生物における何らかの価値判断を反映したものである等の主張をみにくいアヒルの子の定理という数学から出発して議論を展開しています.
Uexküllの環世界論の少し後に動物行動学(ethology)は成立しました(豆ですが,動物行動学のLorenzと環世界論のUexküllは交流があったようです).動物行動学は動物の行動やパターン,どのようなきっかけでその行動が発現するかといった実験を数多く見ることができます.動物行動学を通して,モジュール化された行動の発現のきっかけとなる鍵刺激の認識とそれにつながる本能的な行動パターンに対する客観的な視点での動物の見方を学ぶことができます.
ロボットのみを扱ってきた人やアーティストといった生物に科学的な接点のなかった方々は,動物の行動に(健全だが,ロボットを考える上では過度の)ある種の神秘的な気持ちを抱いてしまう傾向がどうしてもあるように感じるため,古典ではあるのですが本能の研究のような動物行動学の書籍をおすすめしたいです[5].このような本では事実上,動物の認識器官に対するデバッグ/テスト行為が行われているため,動物は日常私達が考える直感からかけ離れた反応をすることを知ることができます.超正常刺激と呼ばれる行動学上の概念に対しては,機械学習エンジニアであれば間違いなく overfittiing 等の概念を連想すると思います.

図:超正常刺激を利用しているカッコウの托卵(Wikipediaより)
この鍵刺激を考えるにあたってカエルの視神経の反応に関する研究が Lettvin(grand-mother cellの名付け親として著名), Maturana(Autopoesisで著名), McCullochとPittsのグループで行われました.このような人たちの思想の上で形式ニューロンがその著者たち(McCullochとPitts)から生まれ,果たして半世紀以上たった今となって深層学習による認識器があると考えると心震えるものがありますよね.
Ewertは更に,動物行動学では開けてこなかった行動の際の脳活動を計測することで,野生動物(ヒキガエル)の行動学と神経活動をひとつなぎにして研究を行い,この分野は神経行動学(neuro-ethology)と呼ばれる分野となりました.書籍 "神経行動学" は邦訳されているものがあり,少し古い点もあるものの行動の観察から神経細胞の発火まで一貫して説明されているため,とても楽しめる内容です.近年の神経活動に焦点があってその動物の現実的な生活とは離れてしまった多くの神経科学の教科書と比較すると(興味の焦点が異なるので仕方がないのでしょうけど),私は生の動物の生活の姿からはじめるこの教科書が大好きです.

図:カエルの眼は多くを語る(Wikipediaより)
また,動物は以上の鍵刺激と諸条件の組み合わせ実行される Fixed Action Pattern (FAP)と呼ばれる,(どこまでが"本能"的で,どこまでが後天的かについてはまだ議論の余地の残るところのようですが)一連の大枠として遺伝的に決まった行動を取ることが知られています.また動物行動学の祖の一人,Niko Timbergenは動物の行動を説明する上で行動の階層性という概念を提案しました.この概念はロボティクスにおいてのSubsumption Architectureや階層強化学習などに受け継がれています.
階層的な制御機構の学習においては個々の行動モジュールや動きの基本的なダイナミクスを提供するmotor primitives/central pattern generators (CPGs)などが初期設定として重要ですが,動物の行動学を覗いてみるとほとんどはある程度FAPが遺伝的に形作られた上で,その動きや鍵刺激の調整や切り替えといったfine-tuningに学習が用いられています.だからといって動物の丸パクリをすれば全て良いわけではなく,最終的に実現したい知能に合わせて判断すべき部分ではないでしょうか.
ちなみに,現在の深層強化学習は動物で言えば進化的なスケールで獲得するような内容を学習させている側面もあるため「動物のように学習する」というよりは,基本は背景となる原理が同一といった程度の最適化手法の一つという程度の認識でいるべきだと思います.
"懐き" のメカニズム
動物が人間と仲良くなるということはどういうことでしょうか?いかにしてそれをロボットで実現すればよいのでしょうか?そもそも 仲良くなるとはどういうことか が簡潔に書かれているため,私はSaint-Exup'eryの「星の王子さま(Le Petit Prince)」にかかれている1節を定期的に読み返すことがあります.以下の文は,キツネが王子さまに "なつく=仲良くなる" とはどういうことかを説明する一文です.
きみがおいらをなつけるんなら、おいらのまいにちは、ひかりがあふれたみたいになる。おいらは、ある足音を、ほかのどんなやつとも聞きわけられるようになる。ほかの音なら、おいら穴あなぐらのなかにかくれるけど、きみの音だったら、はやされたみたいに、穴ぐらからとんででていく。それから、ほら! あのむこうの小むぎばたけ、見える? おいらはパンをたべないから、小むぎってどうでもいいものなんだ。小むぎばたけを見ても、なんにもかんじない。それって、なんかせつない! でも、きみのかみの毛って、こがね色。だから、小むぎばたけは、すっごくいいものにかわるんだ、きみがおいらをなつけたら、だけど! 小むぎはこがね色だから、おいらはきみのことを思いだすよ。そうやって、おいらは小むぎにかこまれて、風の音をよく聞くようになる……[6]
私はここにいくつかの重要なポイントがあると思っています.
- [刺激に対する行動の変化] 「おいらは、ある足音を〜穴ぐらからとんででていく。」.仲良くなった相手とそうでない相手に対して,同じ鍵刺激に対して異なる振る舞いをする
- [予測に基づく行動] 「きみの音だったら、〜とんででていく。」 .入力に対する反射のみではなく,将来の状態を予測して行動する
- [一般化能力・連想] 「あのむこうの小むぎばたけ〜風の音をよく聞くようになる……」.共通した特徴を持つものに対して,影響が波及する
刺激に対する行動の変化は,同様の鍵刺激に対しても異なる行動・振る舞いをみせることを意味します.また,重要な特徴に対して選択的に行動を強化するという捉え方もでき,個人に対する適応という視点でも解釈することができると思います.
予測に基づく行動は手がかり刺激を受け取ったあと,将来の状況を予測して動くことです.先回りや,相手の行動を予測した行動を表現しています.どうも動物も予測しながら行動を決定していることが最近わかっています[7].
一般化能力・連想は,良い経験をしたときに結びつけた視覚的特徴を,異なる物体の視覚的特徴(この場合は小むぎと王子様の髪の毛)である程度似通った評価・予測を行えることを示しています.私はこれらが,動物ロボットがヒトともう1段仲良くなるために必要な要素だと感じています.
これらそれぞれ,非常に実現が難しい内容ではありますが,この単純な状況はヒキガエル(Bufo bufo)でも観察できます.まず前提として,ヒキガエルの目はほぼ固定されていて動かないため眼球運動が少なく,ほとんどの場合は運動体を見ていると考えられています.野生のヒキガエルは通常,餌となる小さくて動くものや虫やミミズ・イモムシのような細長いものが,長い方に進むものを視覚的な刺激としてエサ取り行動を開始します.一方で,草木が風で揺れるような細長いものが,ワイパーのように動くものは無視します.さらに,大きくて動くものに対してはそれを鍵として逃避行動を開始します[8].

図:王子さまとキツネ(青空文庫より)
それ故,ひとが野生のヒキガエルに餌をあげようとして手などで餌をつまんであげても,ヒキガエルは逃げてしまったり食べなかったりしてしまいます.ところがそれでも飼い続けて餌をあげているとたまに食べるときがあるので,そういうことを根気強く数週間続けているとヒキガエルは次第に人の手から餌を食べるようになります[9][10].実はこのメカニズムに関してはEwertのチームが詳細に調べていて,多くのことがわかっています[11].
手前味噌な話ですが,私はこれが動物と人間が仲良くなるもっとも基本的な状況だと考え,論文を書きました[12].一般化能力・連想を畳み込みニューラルネットワークによる画像認識と特徴抽出と捉え,予測に基づく行動と鍵刺激に対する行動の変化を単純な強化学習による行動の修正(古典的条件づけ)として表現し,ヒキガエルの人馴れ実験の再現を行いました.結果としては幸い定性的に実際の野生のヒキガエルと同様の判定や人馴れ実験と同様な結果が得られました.論文で試した実験はかなりエイヤとやったものなので,とても家庭用のロボットに入れられるようなものではありません.ただ,そのためのエッセンスは得られたのではないかなと思う私にとって思い出深い実験です.いつか個人的に両生類ロボットをつくって,より実際的なものを作ってみたいという野望は残っています.
世界モデルの縮小・物理的解釈の利点
動物に対する話から,ロボットの話へ少しもとに戻しましょう.「ある特定のものに対する検出器・認識機能をつくる」とは,動物ロボットを考えるにおいてどのような意味を持つのでしょうか?これまで述べてきたように,私は動物の世界にあるような世界モデルの縮小にあると考えています.ただし,世界モデルの作成には注意が必要だと思います.近年の深層強化学習による from-scratch での学習では自律的に認識器を暗黙的に獲得する可能性は十分存在すると考えられますが,一方でエンジニアリングとして持続可能な開発を実現するためには人間にとって理解可能な表現であることも重要だと考えられます.
これは動物ロボットのようにファンシーな感じのロボットではなくて,自動運転車のようなもっとガチガチのロボットを考えてみると想像しやすいのではないでしょうか.そこで必要となる継続的な認識・世界モデルの性能向上を万人のエンジニアに対して着想を持たせるに至るには,人間も理解できるシミュレータ・可視化技術として世界モデルを開発することがその後最終的に多くの人間にとって合理的に動きやすいと私は信じています.ROSにおけるRvizはどのような背景で作成されたのか私は知らないのですが,このようなロボットにおける統合された情報の可視化は継続的な発展において本質的に重要な事項だと考えます.

図:Rviz (Wikipediaより)
生態をデザインした際に,私達は動物ロボットが直面する様々な基本的な状況や問題を書き出しました.これら一つ一つをロバストに実現することが第一の目標であり,その実現のためにはそれぞれ必要とされることを個別に,たとえば時には世界モデルをすっ飛ばしてロボットの体勢を立て直すといったことも十分にあると思います.しかし世界モデルを通した"記憶のある合理的な行動"は,行動に文脈のある(ニワトリ以上の!)より高度な知性には必要不可欠であると私は考えています.
また,FAPのようにモジュールにされた行動をどのようなタイミングで出し,それを修正していくのかはヒトとロボットの信頼関係を築くために必要な要素ではないかと私は考えます.私は強化学習は行動の最適化と同時に,またそれを通してPersonalizeを行ってヒトとロボットの間に特別な関係を築く際のダイナミクスを表現するものでもあるのではないかと最近は思うときもあります.
統合と生命の幻影
Keywords: アニメーション,Life-Long Machine Learning,表現的解決
これまでの内容で,認識(世界モデル)・行動(鍵刺激・FAP)・学習といった個々のコンポーネントについて,それらの解釈や部分的な実現について説明してきました.近年のロボティクス文脈の深層強化学習はこれまでになかったような,多くの基本的課題を解決しています.そうでなくても,これまでのロボティクスも限定的でありながらも多くの問題を解決できるものでした.これまで得ることができなかった,現実的な環境での画像認識や音声認識といった認識側のブレークスルーも起こりました.しかし,それらシステムの統合は単純な問題で,家庭用のロボットはすぐに家族の一員となれるのでしょうか?私は,まだやるべきことが多く残されていると感じています.
ニワトリよりは頭が良さそうで生き生きとしている感じの知能という雑な目標において,純粋にエンジニアリングのみで解決できるのかというというと,私はそうではないと考えています.たとえば,生物においても,なぜそういうことをするのか不明という動きは普通に存在します.ちょっと特殊な例ですが,線虫がするような恐竜検出器[13]といったような,なぜ存在するのかよくわかっていない行動のデザインは進化的な文脈でしか捉えられない可能性もあるのではないでしょうか.同様の文脈は家庭用ロボットにも存在すると思います.
先にお話したとおり,家庭用ロボットは人とのコミュニケーションを避けることができず,またそのシミュレーションも効果は限定的と言えます.ある程度の試行錯誤的な行動バリエーションの探索はある程度人間においても行わなければいけないのではないでしょうか.スクラッチからの学習や経路計画によって得られる内容は興味深いものもあると思います.しかし同時に,コミュニケーションという複雑な過程に関して言えば,ヒトの文化的背景を踏まえた方向づけされた探索もまた最初のたたき台として優れているのではないかとも思われます.
ロボットアニメーターと表現的解決
アニメーションという言葉は分野や専門の度合いによってさまざまな捉えられ方をする場合があるので,ここでは予め動きが決められているか,センサ情報等に基づきその瞬間瞬間で動きが動的に生成されているかに関わらず,ある一定の品質が満たされている自然な動きというくらいの意味で使いたいと思います. これまでのセルで書かれたアニメーションやCGアニメーション,ゲームでのキャラクターモーションといったメディアでの動きは物理的な拘束が存在せず,積極的に物理的な動きを絵に加えることでリアリティを加えたり,あるいは恣意的に物理を無視することで大きな効果を生む表現が生み出されてきました[14].むしろ,ロボットにおけるアニメーションは演劇やダンス等の身体表現に近い部類と言えるかもしれません.そういう視点で,大阪大学の石黒研究室のロボット演劇を見つめるとより深い理解ができるのではないだろうかと思います.
この文脈でいえば,ロボットにおけるアニメーションの特殊な点はダンス・演劇レベルの身体的・物理的な拘束がキャラクターの表現において存在し,それらの特性を十分生かして行う必要があるという点だと言えるでしょう.別分野からのアニメーターにとっては,新しい拘束の受け方ではないかと思います.むしろ,演出とよばれる範囲なのかもしれません.それを機械学習による最適化をサポートツールとして作成していくべきか,個々の作業者の"学習・勘"に頼るべきかは,やった上で判断がくだされることでしょう.ただし,これまでの認識システムがそうだったように,何らかの機械的な補助は必要になってくるのではないかと私は想像しています.その場合,アニメーターは個々の微細な動きもそうですが,センスとしては演出により大きな比重を持つことになるのでないでしょうか.
ロボットの生態として必要な機能を実現する際,FAPとして何らかの解決をはかるにせよロボットの身体によってはそれ自体では解決が難しく,何らかのコミュニケーション手段によって解決する必要が出てくると考えられます.たとえば,故障しちゃった!という場合に自らが直せないのであれば何か対策を取らなければなりません.私はこのような場合の問題解決を,物理的・数理的に解決する通常の問題解決とは異なり,ロボットの身体およびコミュニケーション器官による表現でもって解決するという意味で個人的に表現的解決と呼んでいます.ロボットの物理的限界に起因する表現的解決は豊橋技科大の岡田研究室で提唱されている弱いロボットに通じる部分も感じています.

図:アニメーションは現実以上に伝える力を増幅させる(Wikipedia.12 basic principles of animationより)
適応し続けるために
家庭用ロボットは長い時間ひとと一緒に過ごします.その間のいくらかの経験によってロボットが変化していく,つまりその経験を学習に用いていくことは自然に連想されることでしょう.ロボットがその場で学習するのは,1つは1種類のソフトウェアで無限のバリエーションの家庭・個人に対応するため,そしてもう1つはその製品の平均としての品質を継続的に向上させるためだと私は考えています.決して,そのように唄えばよく売れるというような腐った理由ではありません.個人への対応はその製品の品質をその個人に最適化していくという意味で,平均的な品質の向上を含んでいるのかもしれません.ただ,連想される技術は変わってきそうに思います.
個人的には,個々の個体の経験は全体のロボットに還元することも確かに重要である一方で,各家庭・各個人に対するPersonalizationこそが学習の本丸だと思います.それは先に紹介した"星の王子さま"とも重なる部分があるように思うためです.そのような学習は近年進展の目覚ましい画像認識をはじめとする高度な認証システムによって成立するものだと思います.単なる辞書ではなく,特徴量をもとにしたよりソフトな推論が"星の王子さまのキツネ"の連想を成立させるための一歩となるのではないでしょうか.非常に多くのロボットが各家庭にばらまかれるような状況は,人類の歴史上まだなかったことです.それに伴った新たなフィールドでの技術が生まれてくることでしょう.
図:王子さまの訪れたバラ園には,自分の知る特別なバラはいなかった(青空文庫より)
こういった流れで,私はLife-Long Machine Learningと呼ばれる分野に興味を持っています. Life-Long Machine Learning はNever-ending Learning や Continual Learning などとも言われ,統一的なフレームワークは少しづつ整備されれているものの未だ探索の時期にある分野です.Life-Long Machine Learningでは1つのエージェントが複数のタスクを与えられ,それに次々と適応させる問題を扱います.オーソドックスな設定では,$N$個のタスクを学習した後から$N+1$個目のタスクを学習する際,過去の学習結果を利用してより高速に新しいタスクを解決することが求められます.
Life-Long Machine Learningはテスト駆動開発と呼ばれるソフトウェア開発の手法のサイクルにとても似ており,テスト駆動開発の全自動化がLife-Long Machine Learnigの一つの実現形態なのではないかと妄想しています. 各家庭から機密性を保持したまますべてのロボットに情報を還元するアプローチは多く考えられていますが,むしろ私は各家庭に特異な情報で延々と適応し続けるロボットのエージェントに対する研究に興味を持ち始めています.
融合のために
これまでの話の中で出てきた個々のコンポーネント・動きが統合されることで,それは1つの動物・キャラクターが表現される必要があります.1つのキャラクターを描く際に,それを複数の人間で分担し統合を図る技術はソフトウェア・エンジニアリングよりもアニメーションにおいての作業手順として存在するのではないでしょうか.キャラクターアニメーションの歴史はコンピュータサイエンスのそれより長いものです.ディズニーやジブリをはじめアニメーションの現場では,より優れた表現を行うために様々な工程や分業が行われています.
それはゲーム(プロシージャル-アニメーション)の開発でも同様だと考えています.そして端的にいえばこれまでのロボットにおいて動きをつける際,既存の大規模な手法との融合はあまり図られてこなかったのではないかと推察しています.それを踏まえ私は個人的な標語として,ソフトウェアとしてのロボティクスとアニメーションにおける技術との融合的な分野を表す**アニマロボティクス(Animarobotics)**という用語を(勝手に)作って呼んでいます.単にアニメーションの作業やノウハウをロボットの動きに輸入するでもなく,またアニメーターがロボティクスを単に学ぶでもなく,1つの存在を自然に成立させるための新しい体系的知識と作業手順を作り出すことが可能ではないかと私は考えています.しかし一方で,一般的に理解されるには多くの前提が成り立たなければいけないことも感じています.
おわりに : 動物としてのロボット
なぜそのロボットはそこにいられるんでしょうか?何らかの理由でそのロボットは市場を獲得し,工場で生産され,社会に一時的であるにせよ安定的に繁栄しているのであれば,この世界に何らかのニッチを形成していそうです.それとも,そのロボットはただ1つ作られた特殊な1体なんでしょうか?
私は動物のようなロボットを作りたいというのもそうですが,ロボットを動物として捉えてそれを繁栄させるという視点で考えることも好きです.それらは表と裏をなしていて,殆どの場合は作りたいという視点で問題は解決されるのでしょうけど,後者は動物学者がロボットを見つめるときの視点で[15],より大局的な考察によって出てくるアイデアや思想も重要だと私は考えます.ただし後者の視点で共感を得ることは,大学の外ではまず極めて稀なことだと思います.常にそういった表と裏の考え方を行き来,あるいはちゃんぽんにして考えることは複雑で,自分では統一されていない部分もありながら進んでいきます.ただたまに,私はこのような場所で何度も立ち止まって,これまで進んできた道を振り返る機会を大切にしています.
このノートでは,これまで私が考えてきたロボットの人工知能についてひどく偏った個人的な思想を展開してきました.自分は個々の動きの詳細もその文脈が気になるものの,動物的なロボットとしての知能・生態全体に対する統一感に興味の中心があることが振り返ってみると実感します.私はそれがときには目的関数に表現することも困難な内容すべてを含んだ合理性によって実現されると信じています.ここでの話とは別に,生態や行動に対する根源的な疑問に対する自分なりの意見を"最弱の強いAI"として別の場所で展開しています[16].ご興味のある方は論文を参照していただけると幸いです.
自然言語処理や音声処理・画像処理といった多くの技術が実用化に進んでおり,優れたそれら入力をもとにいかにより高度で"自然な"出力・表現として表出させるかこそが次なるステップだと思います.かつてのアニメーションもそうだったように[14],ロボットが当然動く,という技術的土台が成熟し始めた今の時代だからこそ,その先のつくりかた自体を考え作り出していくことができるのだと思います.その先にはロボットはエンジニアリングではなく今の映画やゲームのように,民主化された表現のための1種のメディアとなるのではないでしょうか.
参考文献
[1] Singh, Satinder P., Tommi Jaakkola, and Michael I. Jordan. "Learning without state-estimation in partially observable Markovian decision processes." Machine Learning Proceedings 1994. 1994. 284-292.
[2] Otsuka, Makoto. "Goal-oriented representation of the external world: a free-energy-based approach." Nara Institute of Science and Technology (2010).
[3] Thrun, Sebastian, Wolfram Burgard, and Dieter Fox. Probabilistic Robotics. MIT Press, 2005.
[4] Van Essen, David C., and Jack L. Gallant. "Neural mechanisms of form and motion processing in the primate visual system." Neuron 13.1 (1994): 1-10.
[5] Tinbergen, Niko. "The study of instinct." (1951).
[6] Antoine de Saint-Exup¥'ery(訳:大久保ゆう)."あのときの王子くん(Le Petit Prince)",青空文庫.
[7] Johnson, Adam, and A. David Redish. "Neural ensembles in CA3 transiently encode paths forward of the animal at a decision point." Journal of Neuroscience 27.45 (2007): 12176-12189.
[8] Ewert J.-P. (1980) Neuroethology. (Springer, Berlin, ISBN 3-540-09790-2)
[9] Ewert, J-P., A. W. Dinges, and T. Finkenst"adt. "Species-universal stimulus responses, modified through conditioning, reappear after telencephalic lesions in toads." Naturwissenschaften 81.7 (1994): 317-320.
[10] Gestalt Perception in the Common Toad - 2. Modification of Prey Recognition by Learning : https://av.tib.eu/media/15242#t=00:01,00:18
[11] Ewert, J-P., et al. "Neural modulation of visuomotor functions underlying prey-catching behaviour in anurans: perception, attention, motor performance, learning." Comparative Biochemistry and Physiology Part A: Molecular & Integrative Physiology 128.3 (2001): 417-460.
[12] Yoshida, Naoto. "From retina to behavior: prey-predator recognition by convolutional neural networks and their modulation by classical conditioning." Adaptive Behavior 24.4 (2016): 195-218.
[13] Andrew Brown (原著), 長野 敬 & 野村 尚子 (翻訳),"はじめに線虫ありき―そして、ゲノム研究が始まった", 青土社(2006)
[14] Thomas, Frank. "Johnston O.. Disney Animation: The Illusion of Life." Abbeville Press, New York 21 (1981): 200-219.
[15] McFarland, David and Tom Bösser. "Intelligent behavior in animals and robots." (1993).
[16] Yoshida, Naoto. "Homeostatic agent for general environment." Journal of Artificial General Intelligence 8.1 (2017): 1-22.