この記事のタイトルは、AMDが4Cで発表した1つのスピーチから来ました。 Compute Shaders: Optimize your engine using compute(3).
概念
Compute ShaderはGPUで実行するプログラムであります。よく話しましたが、先にGPUを紹介する必要があると思います。ご存知のとおり、CPUとGPUは2つの異なる構造ですが、両者の違いは何ですか?
1.CPUは低遅延に基づいているデザイン
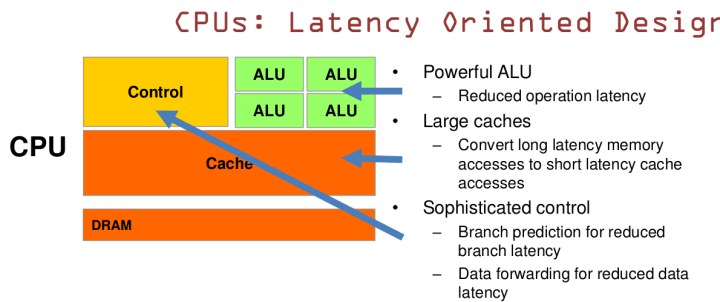
CPUには、操作遅延を減らすための強い算術ロジックユニット、メモリアクセスの遅延を減らすための巨大なCache、または複雑なコントローラーがあります。分岐予測を使用して分岐遅延を減らし、データ転送を使用してデータ遅延を減らします。
これと言えます:CPUがロジック制御とシリアル計算方面に優れています(1)。
2.GPUは大スループットに基づいているデザイン
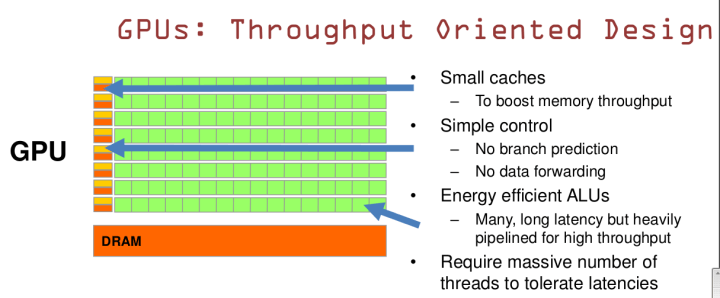
GPUには、スループットを促進するための小さなCacheがあります。分岐予測とデータ転送のない簡単なコントロールがあります。効率の高い省エネルギーALUがあり、遅延が長いALUがたくさんありますが、高スループットのためにパイプライン化されています。遅延を減らすために、多数のスレッドを開く必要があります。
これに対応して、「CPUが集中的な並行しやすいプログラムの計算に適しています」と言えます(1)(2)。
3.GPGPU
見られるのは、CPUとGPUがそれぞれに自分の得意ことがあります。では、シリアルにCPUを使用し、パラレルにGPUを使用し、この両者を組み合わせることができます。この技術はGPGPUと呼ばれ、つまりGPUを使用して汎用計算を行う技術です(General Purpose Computing on GPU)(1)。

ただし、一般的に、GPUは画像レンダリングの執行によく使われることがわかりました。では、汎用計算を行うために、NVがCUDA、KhronosがOpenCL,MicrosoftがDirectComputeつまりCompute Shaderをリリースしました。そして、さまざまなグラフィックAPIもCSをリリースしました(25)。
4.ComputeShaderをサポートするグラフィックAPI

10から、DXがCompute Shader/Direct Computeをサポートしていますが、比較的大きな制限があります。DX11のComputeShaderには、より強い機能があります(もちろん、DX12も同じです)(6)。ですから、一般的にUnityでCSを使用する時に、またShader Target4.5(つまりShader Model 5)を要求します(19)。
OpenGLは4.3からのCSをサポートします(ただし、MacOSXは4.3をサポートしていません)。 ESは3.1以降CSをサポートしています(5)。
MetalとVulkanの両方がCSをサポートしています(4)(7)。
さらに、PS4とXbox One(DX11.2)もCSをサポートしています(19)。
5.Computeパイプラインとグラフィックスパイプラインの比較
いくつかの画像を介して、計算パイプラインと従来のグラフィックスパイプラインの違いを簡単に比較します。

コンピューティングパイプラインが非常に簡単になっていることが見られます(3)。
(GPU Rendering Pipelineに関しては、この画像を参考できます(14)。)
ハードウェア側から見ますと:
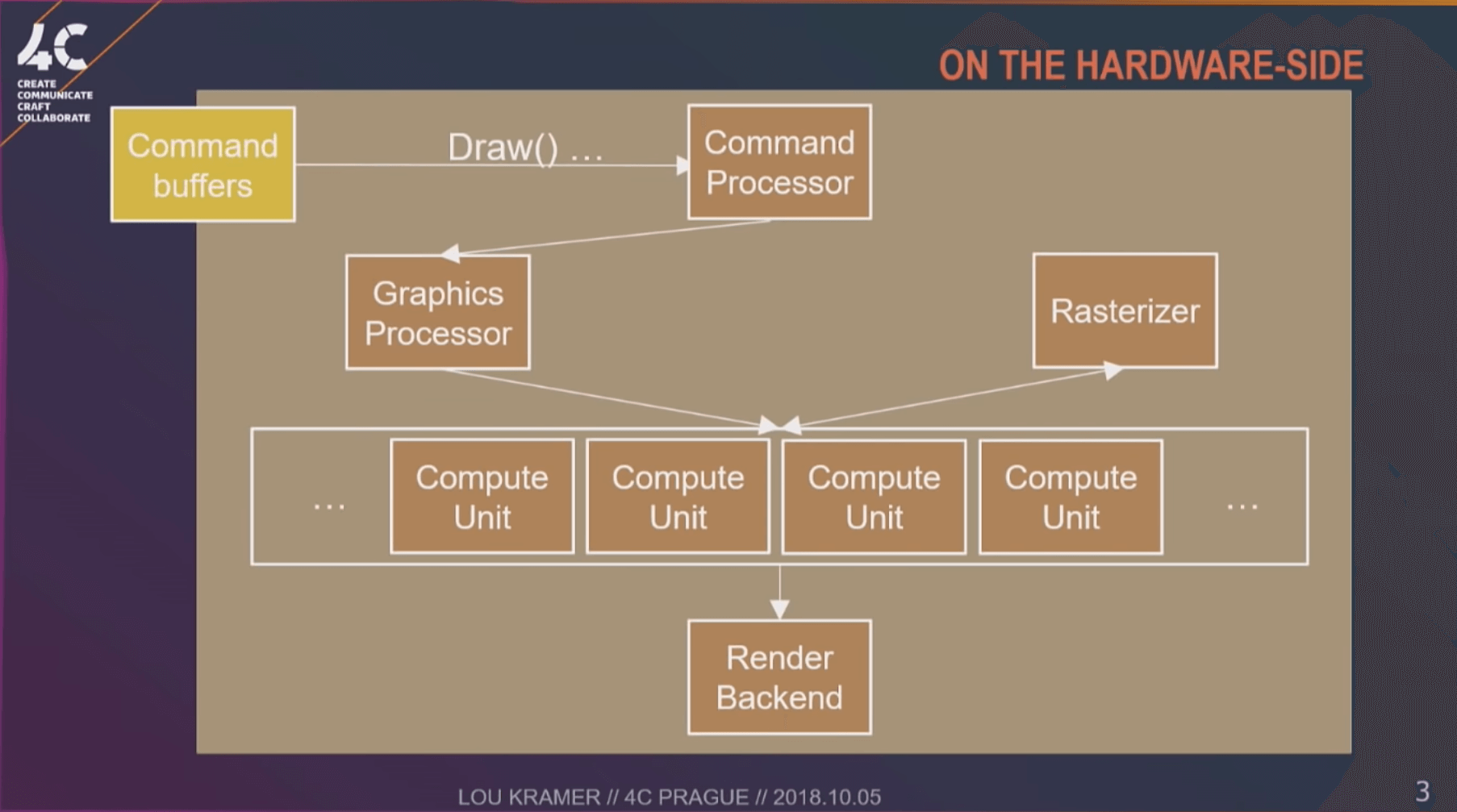
上図は、グラフィックスパイプラインがハードウェア側のワークフローです(3)。
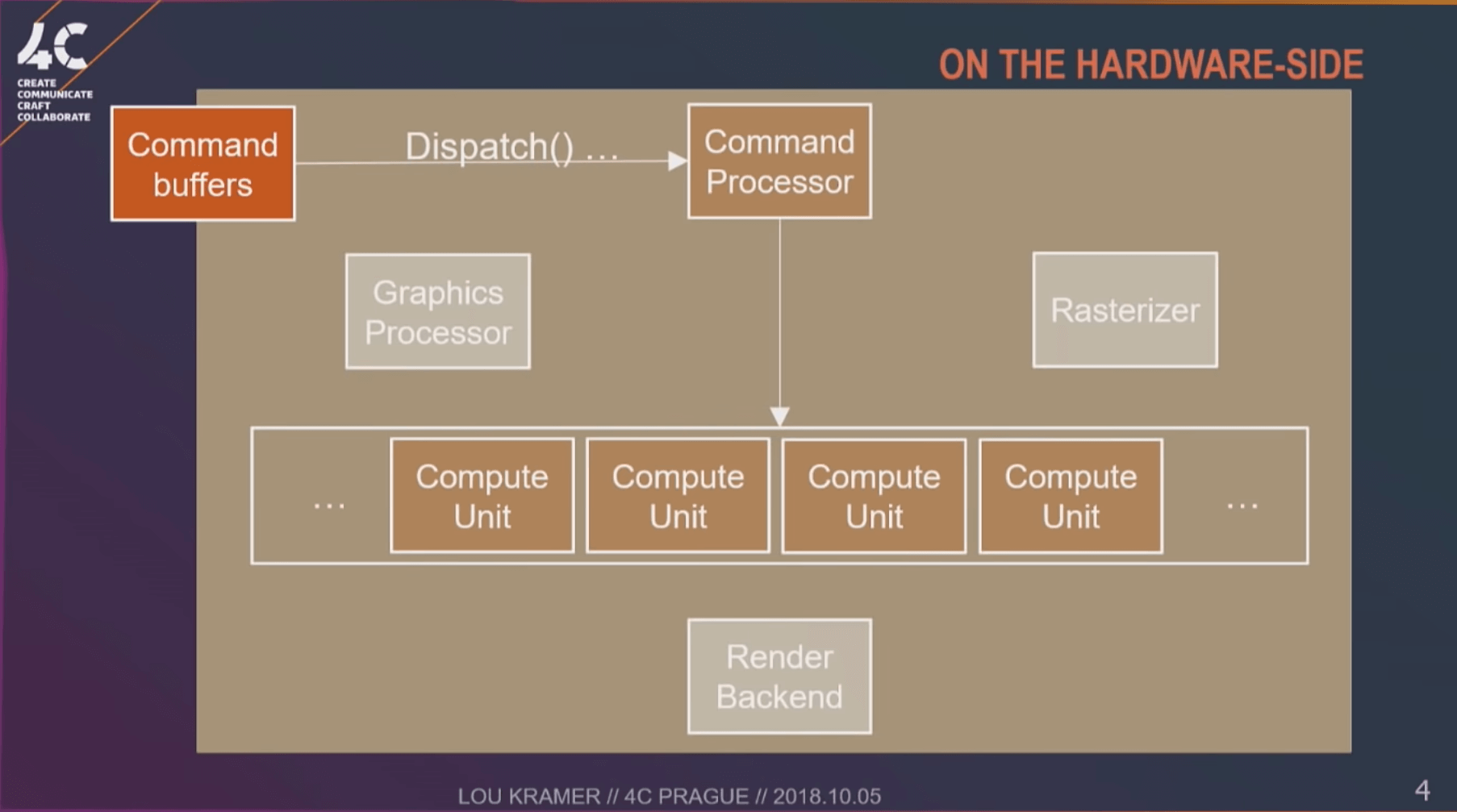
上図は、コンピューティングパイプラインがハードウェア側のワークフローです(3)。比較すると、次のことがわかります。
Compute Shaderはレンダリングパイプラインを通過せずに、GPUを使用してグラフィックスレンダリングに直接関係しない一部の作業を完了でき、ハードウェアのOverheadを削減できます。これがCompute Shaderの利点です。
文法
1.UnityでどうやってCompute Shaderを使用しますか?
上文で紹介しました。現在にはたくさんのグラフィックAPIがCSをサポートしていますが、さまざまなAPIのShading Language文法とAPIは異なります。UnityのShaderLabがHLSLに似っているAPIを採用して、Shaderを書きやすくさせました。
2.Kernel
Unityで新しいCSを作成すると、コードは下記のようになります。
(わずかな変更があります)
// test.compute
#pragma kernel FillWithRed // 1
RWTexture2D<float4> res; // 2
[numthreads(8,8,1)] // 3
void FillWithRed (uint3 dtid : SV_DispatchThreadID) // 4
{
res[dtid.xy] = float4(1,0,0,1); // 5
}
これは簡単なCompute Shader例です、1つのRTを赤で塗りつぶします。
- まずはKernelを宣言します。Kernelは1つのmain関数に相当し、CSの入り口です。これはMetalからのアイデアはずです(7)。1つのアセットファイルに異なるKernel方法を定義でき、一部のコードを共有しながら、独立性も一定的に保証できます。
- そして、1つのRWTexture2Dを宣言して、C#に対応し、RenderTextureであります。
- 関数名の上でまだ1つnumThreadsのattributeがありますが、これについて後に説明します。
- 関数のパラメーターの後に1つのSemantic(SV_DispatchThreadID)があります。これについても後に説明します。とりあえず座標値として使用できます。
- 最後には関数体で、RTにあるピクセルを赤に設定します。
3.Dispatch
このようなCSコードをどうやって執行しますか?C#の中で下記のようなコードをコールします。
public void Dispatch(int kernelIndex,
int threadGroupsX,
int threadGroupsY,
int threadGroupsZ);
CPU側で、このインターフェイスを介してCSをDispatchできます。DispatchはDrawcallと同じようですが、Drawがないです。その中のKernelIndexはComputeShader.FindKernelを介して取得できます。また、ThreadGroupsXYZはスレッドグループの数を表します。では、スレッドグループとは何ですか?
4.スレッドグループ

CSでは、スレッドは3つの次元に分割できます(2)。
上の図で、右側は単一のスレッドを表し、左側は1つのDispatchを表し、真ん中は1つのThread Groupを表します。
Thread Groupとは、複数のスレッドを1つのGroupにまとめることを指します。このGroupの中に、各スレッドに自分の相対位置があります。Group内では、共有変数を使用して相互に通信することもできます。numThreadsのattributeをKernel関数の前に宣言することは、1つのThread GroupにいくつのThreadがあることを示します。
図に示すように、1つのDispatch内は3x2x3のThread Groupsがありますが、1つのGroup内に4x4x2のThreadがあります。このやり方の利点はGPUのwarp/wavefront/EU-threadを利用できることです(2)(3)。
そして、1つ例をあげます。現在、たくさんの画像圧縮アルゴリズムはBlockに基づいており、Thread Group(OpenGLではlocal sizeと呼ばれます)は画像データのBlockのサイズになれ、Group数は画像サイズをBlockのサイズで割った値になれます。各Blockは単独のWork Groupとして処理でき、Group内の情報共有もできます(5)。さらには下図を見でください(6)。
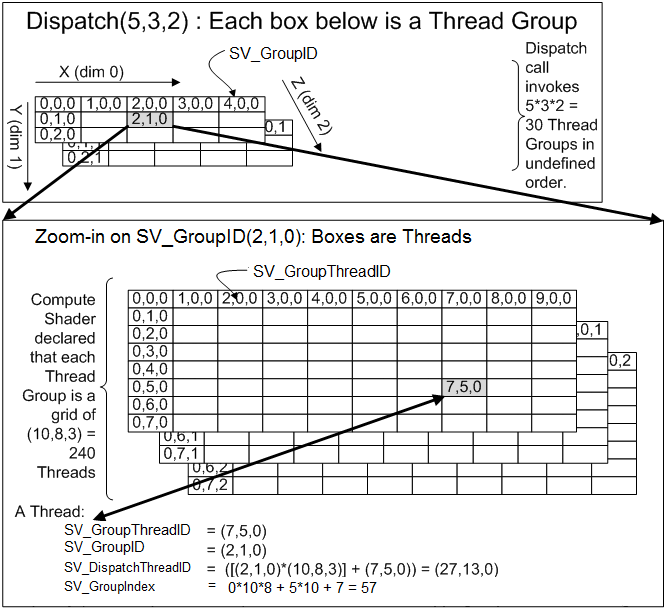
図の上半分が1つの5x3x2のDispatchを表し、図の座標はThread Groupを表します。そして2,1,0のThread Groupを開くと、画像の下半分が見えます。これは10x8x3のThread Groupを表し、図の座標は1つのThreadを表します。
上図のように、これらの座標に基づいてGroupThreadID、GroupID、DispatchThreadID、およびGroupIndexを計算できます。これらのIDは、一般的にインデックスとしてBuffer、TextureまたはThread Group Shared Memoryにあるデータを取得するために使用されます。
たとえば、上記の例では、GroupThreadIDは画像Block内の座標であり、GroupIDは画像をBlockによって割った座標(画像サイズをBlockサイズで割ったもの)であり、DispatchThreadIDはピクセルの座標です。
5.Buffer & Texture
CSは、スカラー、ベクトル、行列、テクスチャ、配列など、いくつかの普通のタイプを使用できます。それ以外、CSをより柔軟に使用するために、StructuredBuffer(略してSBuffer)もリリースされています。
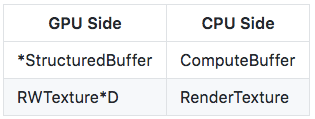
FSでもSBufferが使用でき、他のShaderでも使用できます。)
StructuredBufferには次のものも含まれます。
RWStructuredBuffer
RWStructuredBuffer with counter
(RW)ByteAddressBuffer
AppendStructuredBuffer
ConsumeStructuredBuffer
StructuredBufferはさまざまな組み込みタイプ以外、カスタムStructも含めることができます。
6.GroupShared
GroupSharedを介して、1つの変数をグループ内共有ものにマークすることができます。(またはTGSMと呼ばれます(2))
この変数を使用すると、Thread Group内で通信できます。
たとえば、Forward + / DeferredパイプラインでCompute Shaderを使用して、点光源を排除できます。これは、バトルフィールド3で使用されている手法です(16)(21)。
7.Barrier
異なるスレッドで同じアセットにアクセスする場合、Barrierを使用してブロックおよび同期する必要があります。
次の2つのタイプに分けられます。
①
GroupMemoryBarrier
DeviceMemoryBarrier
AllMemoryBarrier
②
DeviceMemoryBarrierWithGroupSync
GroupMemoryBarrierWithGroupSync
AllMemoryBarrierWithGroupSync
GroupMemoryBarrierは、GroupShared変量を待つアクセスです。
DeviceMemoryBarrierは、TextureまたはBufferを待つアクセスです。
AllMemoryBarrierは上記の2つの合計です。
8.Interlocked
アトミック操作は、スレッドスケジューリングメカニズムによって中断されません。
InterlockedAdd
InterlockedAnd
InterlockedCompareExchange
InterlockedCompareStore
InterlockedExchange
InterlockedMax
InterlockedMin
InterlockedOr
InterlockedXor
ただし、これはint / uintにのみ使用できます。
例えば、グレースケールヒストグラムの計算に、Tonemapping\Auto Exposureなどの効果に使えます(19)。
9.プラットフォームの違い
Unityはクロスプラットフォームの作業をサポートしてくれましたが、まだいくつかのプラットフォームの違いに直面する必要があります。
1)配列が範囲外の場合、DXでは0が返され、他のプラットフォームではエラーが発生します。
2)変数名はキーワード/組み込みライブラリ関数の名前が同じな場合、DXには影響なく、他のプラットフォームではエラーが発生します。
3)SBufferの構造体のビデオメモリレイアウトがメモリレイアウトと一致しない場合、DXが変更する可能性がありますが、他のプラットフォームではエラーが発生します。
4)初期化されていないSBufferまたはTextureは、一部のプラットフォームですべて0になりますが、NaNであっても、他の任意値になる場合があります。
5)Metalは、テクスチャの原子に対する操作やSBufferに対するGetDimensionsコールをサポートしていません。
6)ES 3.1は、CSで少なくとも4つのSBufferをサポートします(したがって、関連するデータをstructとして定義する必要があります)。
7)レンダリングパイプラインでは、es3.1 +のサポートを主張する一部のAndroidスマートフォンは、フラグメントシェーダーのStructuredBufferへのアクセスのみをサポートします。
10.パフォーマンス最適化
さらに、CSを使用する場合、いくつかのパフォーマンス最適化ポイントも知っておく必要があります。
1)Group間の相互作用を最小限に抑えます。ハードウェアはグローバル同期をサポートしていません(2)。同期しないとエラーやクラッシュが発生しやすくなります(3)。
2)GPUが一回Dispatchする時には64(AMDではwavefrontと呼ばれ)または32(NVIDIAではwarpと呼ばれ)のスレッドをコールします(実際にはこれは1つのSIMDテクノロジーです)。ですから、numThreadsの積はこの値の整数倍であることが最適です。しかし、Maliはこのような最適化を必要としません(8)。さらに、MetalはAPIを介してこの値を取得できます(7)。
3)リードバックの回避:リードバック操作はレンダリングパイプラインではあまり使用されず、CSでも使用される可能性があるため、注意する必要があります(20)。
4)分岐、特にThread Group内の分岐を回避します。これは実際には2番目のポイントに関係があります。wavefront/warp整数倍のところで分岐が発生すると、コストははるかに小さくなります(2)(26)。
5)限りにメモリの連続性を確保します(2)。
6)[unroll]を使用してループを開きます。unrollを手動で行う必要のある場合もあります(22)。
まだこのリストされていない、いくつかのレンダリングパイプラインに適用可能なTipsがあります。
アプリ
では、CSを紹介した後に、現時点に利用できるアプリを見てみましょう。
1.GPU Particle System
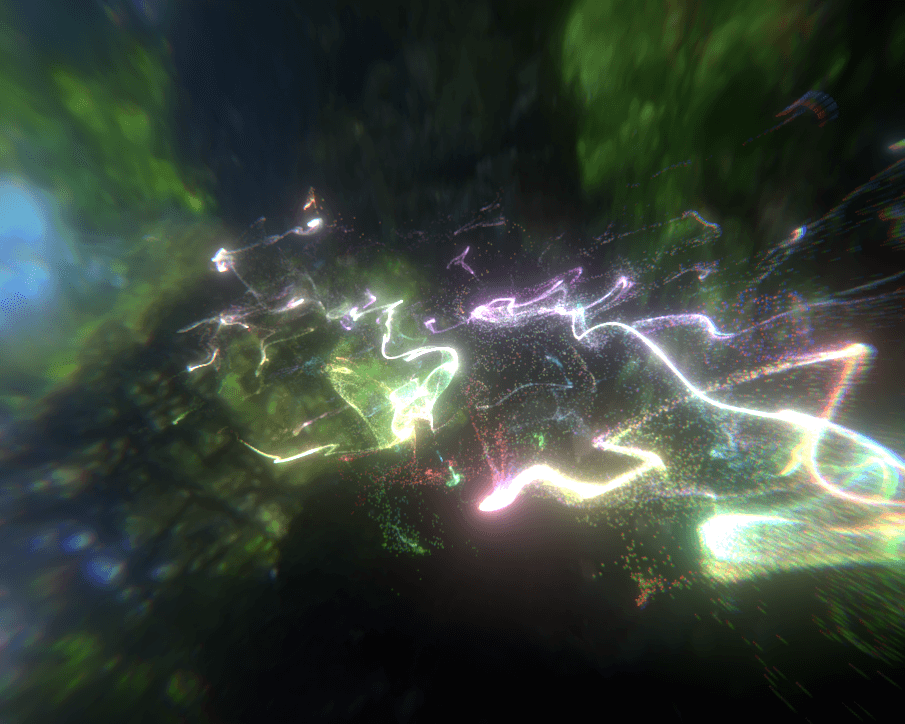
上図には、CSで実現したGPUパーティクルシステムです。この機能でCSを利用してパーティクルの運動軌道を計算します(10)。
2.GPU Simulation

画像には布シミュレーションです。CSを使用して布パーティクルの力の受ける運動の計算、衝突の検出とフィードバック、および制約計算を行いました。他には髪シミュレーションや水シミュレーションなど似たようなものもあります(11)。
3.Image Processing

画像は1つの簡単な画像脱色処理です(12)。RGBと(0.299,0.587,0.114)にDotを行い、グレー値を取得します(24)。似たようなものはまだeye adaptation、color gradingなどがあります(3)。
UnityのPPS2で使用されているHistogramは良い例です。CSのほとんどすべての機能が使用されています(23)。
4.Image Compression

画像はASTCアルゴリズムが圧縮した画像(4×4 6×6 8×8)です(13)。上記のように、CSを使用してBlockに基づくテクスチャ圧縮アルゴリズムを実現できます。
5.Tessellation
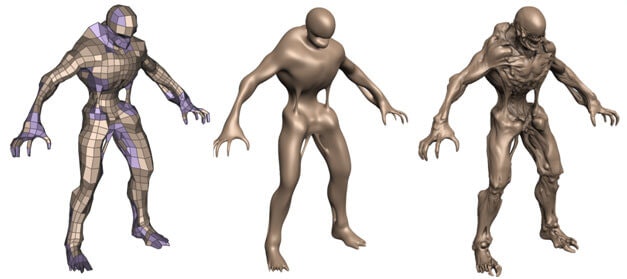
Tessellation(15)のデフォルトパイプラインのTessellationは比較的制限されており、Displacement Mappingを使用して効果を向上できますが、それでも十分に動的ではありません。これをCSと一緒に使用すると、いくつかのロジックと合わせて、より自由や動的な詳細頂点を生成できます(14)(3)。
6.Local Lights Culling

バトルフィールド3では、Defffered Shading Pipelineを使用して、CSを介して点光源、サーチライト、およびその他の光源を排除します(16)。
7.Occlusion Culling

これはMaxwellGengさんが実現したGPU Occlusiong Cullingです。彼はHizの方法を使用して、Clusterにカバーの除外を行いました(17)。この考え方はGPUDRPと呼ばれます。
8.GPU Driven Rendering Pipeline
画像にはアサシン クリード ユニティです。このゲームで、GPUDRPテクノロジーが使用され、Siggraph 2015: Advances in Real-Time Rendering in Games courseで発表しました(18)。
もっとたくさんありますが…
Simple, but not easy.
「Simple, but not easy」とは、Compute Shaderについての私の理解であり、この記事のまとめでもあります。ESは3.1以降からCSをサポートしています。つまり、スマホでのサポート率はそれほど高くありません。
また、スマホの計算力はまだ低いです。GTX 1050 Tiの計算力は1.9k~2.9k Gflops(floating point operations per second)で、768コアがあります。Huawei P20のMali-G72 MP12の計算力は300+ Gflops、coreは12個のみあります(28)。
そのため、スマホでCSを使用することは困難です。しかし、巨大な可能性を秘めていると思います。スマホハードウェアの急速な発展により、Compute Shaderの使用が携帯で普及するまでにそれほど時間はかからないと思います。

備考
1)Graphic Processing Processors (GPUs) Parallel Programming
2)DirectCompute Optimizations and Best Practices
3)[Compute Shaders: Optimize your engine using compute / Lou Kramer, AMD (Video)] (https://www.youtube.com/watch?v=0DLOJPSxJEg)
4)Introduction to Compute Shaders in Vulkan
5)Compute Shader(OpenGL)
6)Compute Shader Overview(Direct3D 11)
7)About Threads and Threadgroups(Metal)
8)ARM® Mali™ GPU OpenCL Developer Guide(Version 3.2)
9)Real-Time Rendering 3rd Edition. Chapter
10)[GPU Particles (Github)] (https://github.com/Robert-K/gpu-particles)
11)GPU Cloth Tool
12)Compute Shader Filters
13)Adaptive Scalable Texture Compression
14)Introduction to 3D Game Programming with DirectX 11
15)DirectX 11 Tessellation (NVIDIA)
16)DirectX 11 Rendering in Battlefield 3
17)Hi-Z GPU Occlusion Culling
18)GPU-Driven Rendering Pipelines
19)https://docs.unity3d.com
20)Problems with ComputeBuffer Readback
21)Volume Tiled Forward Shading (Github)
22)Low-level Shader Optimization for Next-Gen and DX11 (PPT )(Video)
23)Post-processing Stack v2 (Github)
24)デジタル画像処理(ゴンザレス)
25)General-purpose computing on graphics processing units (Wikipedia)
26)グローバルイルミネーションテクノロジー:オフラインからリアルタイムレンダリングまで
27)Mythbusters Demo GPU versus CPU ( NVIDIA )
28)Glops
UWA Technologyは、モバイル/VRなど様々なゲーム開発者向け、パフォーマンス分析と最適化ソリューション及びコンサルティングサービスを提供している会社でございます。
今なら、UWA GOTローカルツールが15日間に無償試用できます!!
よければ、ぜひ!
UWA公式サイト:https://jp.uwa4d.com
UWA GOT OnlineレポートDemo:https://jp.uwa4d.com/u/got/demo.html
UWA公式ブログ:https://blog.jp.uwa4d.com